

Удаление одинаковых строк в PostgreSQL
Если получилось, что в таблице отсутствует первичный ключ (primary key), скорее всего, среди записей есть дубликаты. Речь идёт о дублирующихся строках или случаях, когда дублируется одна либо более колонок. Посмотрим на таблицу с информацией о покупателях, где вторая по счёту строка полностью задублирована:
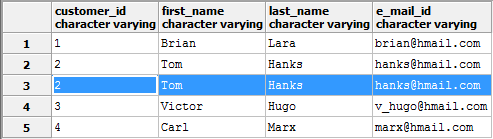
Чтобы удалить все дубликаты, нам подойдёт следующий запрос:
DELETE FROM customers WHERE ctid NOT IN (SELECT max(ctid) FROM customers GROUP BY customers.*);
По умолчанию, уникальное для каждой записи поле ctid скрыто, однако оно существует в каждой таблице.
Тут следует заметить, что запрос довольно требователен к ресурсам, что следует учитывать при его использовании на рабочем проекте — просто будьте аккуратны.
В следующей ситуации повторяются значения полей.
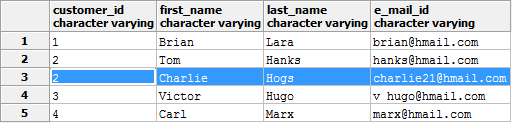
Если допускается удалять дубликаты, не сохраняя все данные, используем следующий запрос:
DELETE FROM customers WHERE ctid NOT IN (SELECT max(ctid) FROM customers GROUP BY customer_id);
Если же информация важна, сначала давайте найдём записи с дубликатами:
SELECT * FROM customers WHERE ctid NOT IN (SELECT max(ctid) FROM customers GROUP BY customer_id);

До удаления такой записи мы можем перенести её во временную таблицу либо заменить значение customer_id на другое.
Как бы там ни было, общая форма запроса на удаление вышеописанных записей будет выглядеть так:
DELETE FROM table_name WHERE ctid NOT IN (SELECT max(ctid) FROM table_name GROUP BY column1, [column 2,] );
Возможно, вам также будут интересны следующие статьи: — «Работа с конфигурацией в PostgreSQL»; — «Безопасное изменение типа поля в PostgreSQL»; — «Полезные команды в PostgreSQL»; — «Поиск «потерянных» значений в PostgreSQL».
По материалам «15 Advanced PostgreSQL Commands with Examples» и «10 Most Useful PostgreSQL Commands with Examples».