

Time series-данные в реляционной СУБД

Предлагаем вашему вниманию краткий пересказ выступления Ивана Муратова, нашего преподавателя на курсе «Архитектор высоких нагрузок». Речь идёт о докладе, с которым Иван выступил на конференции HighLoad++ Siberia 2019 в Новосибирске. Тема доклада — «Time series-данные в реляционной СУБД. Расширения TimescaleDB и PipelineDB для PostgreSQL».
Time series-данные — это данные о процессе, которые собраны в разные моменты жизни этого процесса. Если мы говорим об автомобиле, то это его скорость, направление, координаты. Если мы говорим об использовании ресурсов на сервере, то это оперативная память, свободное место на дисках, нагрузка на CPU и т. д.
Можно выделить следующие особенности time series-данных или, как их ещё называют, временных рядов: — время фиксации. Любая time series-запись имеет поле с меткой времени, в которое было зафиксировано значение; — почти всегда работа происходит в append-only режиме. Таким образом, новые данные не заменяют старые. Удалению подлежат только устаревшие данные; — характеристики процесса (скорость, данные о нагрузке, координаты и т. п.) — это уровни временного ряда; — time series-записи не рассматриваются отдельно друг от друга. Данные используются только в совокупности по временным окнам, периодам или интервалам.
Time series-хранилища сегодня в тренде!
Если говорить о популярных решениях для хранения данных, то можно с уверенностью сказать, что Time series-хранилища сегодня в тренде. Этот факт подтверждает, к примеру, график с сайта db-engines.com, где отображена популярность различных моделей хранения данных за последние 2 года:
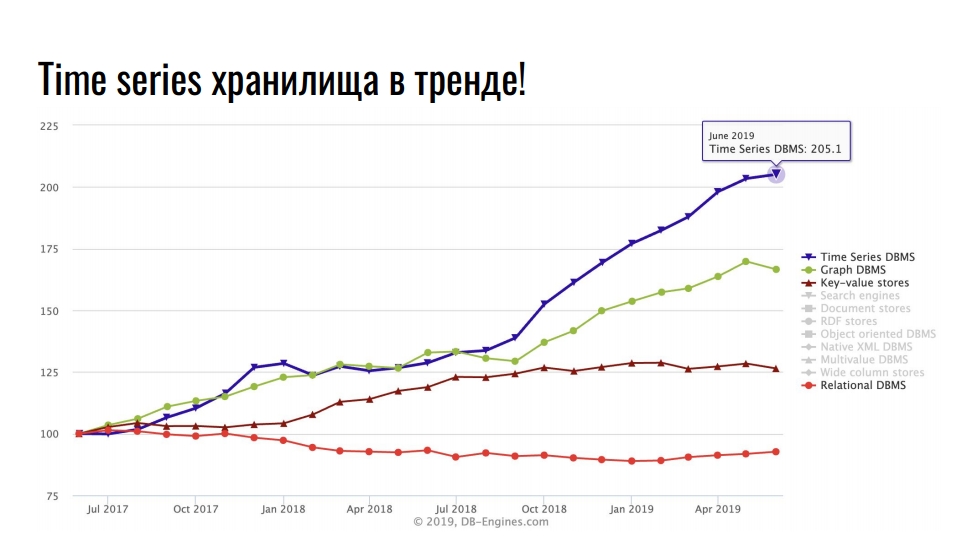
Как мы видим, сегодня в лидерах time series-хранилища, на 2 месте — графовые БД, затем key-value и реляционные базы.
С чем связана такая популярность специализированных хранилищ? Одна из причин — интенсивный рост интеграции информационных технологий: Big Data, IoT, мониторинг highload-инфраструктуры, соцсети. Ведь, кроме полезных бизнес-данных, даже метрики и логи занимают очень много ресурсов.
Решения для хранения time series-данных
Рассмотрим очередной график, где отображены специализированные решения для хранения time series-данных:
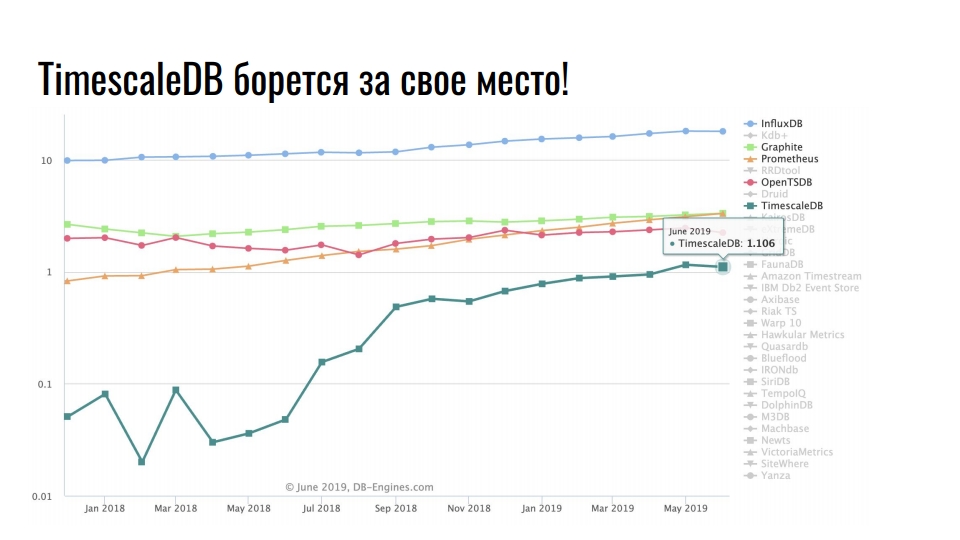
Лидером является InfluxDB. Впрочем, это неудивительно, и все кто работал с time series-данными, про этот продукт знают. Но хотелось бы отметить 10-кратный рост у TimescaleDB. О нём и поговорим.
TimescaleDB
TimescaleDB — это расширение к реляционной СУБД с открытым исходным кодом, которое борется за место под солнцем среди продуктов, изначально разработанных под под time series. Расширение оптимизировано для быстрой вставки и сложных запросов.
Особенности TimescaleDB: — устойчивая скорость записи при росте объёма базы под большими нагрузками, а также при увеличении количества партиций; — возможность использования стандартных возможностей PostgreSQL, таких как SQL, репликация, восстановление, резервное копирование и др.; — неплохой набор интеграций, к примеру, с Prometheus, Grafana, Zabbix, Telegraf, Kubernetes; — есть бесплатная версия с открытым кодом.
В первую очередь, TimescaleDB создана для хранения данных, с чем она прекрасно справляется. Это мощная система секционирования с минимальными ограничениями, если сравнивать с нативными в PostgreSQL.
Теперь пришло время сказать несколько слов про PipelineDB.
PipelineDB
PipelineDB — высокопроизводительное расширение, разработанное для выполнения непрерывных SQL-запросов для данных time series.
Особенности: — непрерывная обработка поступающих данные c помощью SQL и помещение результата в таблицу; — SQL-интерфейс; — возможны интеграции с Apache Kafka и Amazon Kinesis; — есть выполнение хранимых процедур по условиям; — есть бесплатная версия с открытым кодом; — разработка заморожена на версии 1.0, сейчас выходят лишь багфиксы.
В первую очередь, расширение PipelineDB создано для высокопроизводительной потоковой обработки данных. PipelineDB позволяет выполнять вычисления на больших массивах данных, при этом отсутствует необходимость сохранять сами данные.
Совместное применение PipelineDB и TimescaleDB
С PostgreSQL и этими расширениями мы сможем хранить и обрабатывать большие массивы данных time series, а применений можно придумать очень много. Вот, к примеру, реальный кейс из сферы мониторинга транспорта:
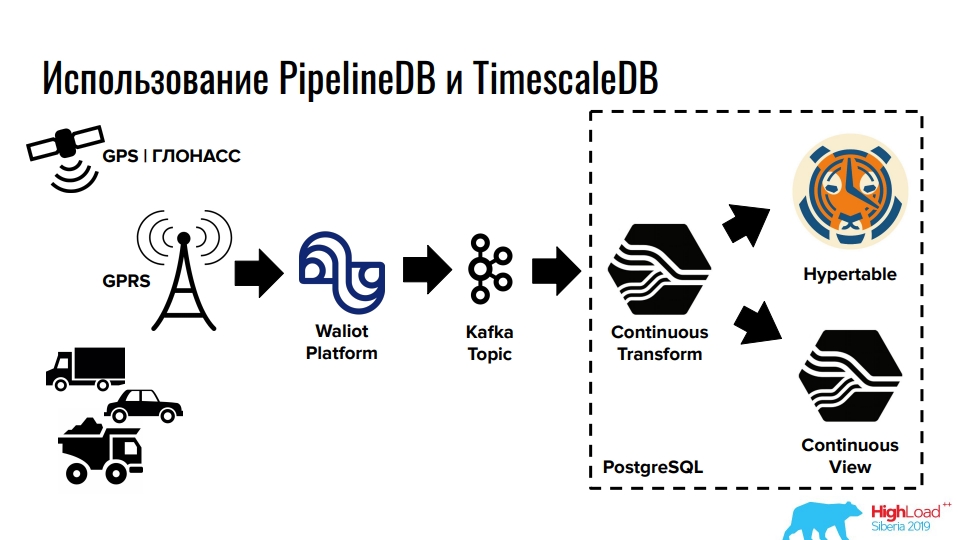
Итак, TimescaleDB позволяет хранить большие объёмы благодаря «хитрому» партицированию, а PipelineDB предоставляет работу со стримами и интеграцию с очередями прямо в PostgreSQL. А для задач, где одновременно нужна реляционная СУБД, NoSQL и time series, вышеописанный вариант использования PipelineDB и TimescaleDB может быть весьма удобен.
Чтобы «потрогать» всё самостоятельно, смотрите демо на GitHub либо запустите Docker-образ, внутри которого вы найдёте сборку из последнего PostgreSQL, PipelineDB и TimescaleDB.