
В этой статье пойдет разговор о том, что такое структуры данных в контексте разработки программного обеспечения. Кроме общих описаний и понятий, попробуем определить значение структур данных в программировании. Отдельное внимание будет уделено строению такой популярной структуры данных, как массив. Знание некоторых нюансов позволит вам оптимизировать свою работу и обеспечить грамотное применение этой известнейшей и широко используемой структуры данных.
Но начать следует с описания структуры данных как таковой. Что же определяет это понятие? Если не вдаваться в сложные определения и термины, можно сказать одним простым предложением: структура данных — это не что иное, как определенный способ организации данных, обеспечивающий максимально эффективное их использование. Ничего сложного в этом описании нет и быть не может: ведь у нас всегда есть некая информация в цифровом виде, и этой информацией приходится постоянно оперировать. И чтобы использование было эффективным, нужно все это как-то организовать. Как?
Способы организации данных, как и их структуры, бывают разные. Но мы сейчас не об этом. Лучше задать следующий вопрос: какие основные операции используются разработчиком? Что конкретно приходится выполнять? В реальности определение всех задач можно свести к следующим:
- доступ (получаем информацию);
- поиск (находим информацию);
- вставка (добавляем новое);
- удаление (удаляем ненужное).
Для выполнения вышеописанных операций существует множество разных структур данных. Какие-то из них более эффективны, какие-то менее. Получить общее представление о связи структур данных с выполняемыми над ними операциями можно на картинке ниже:
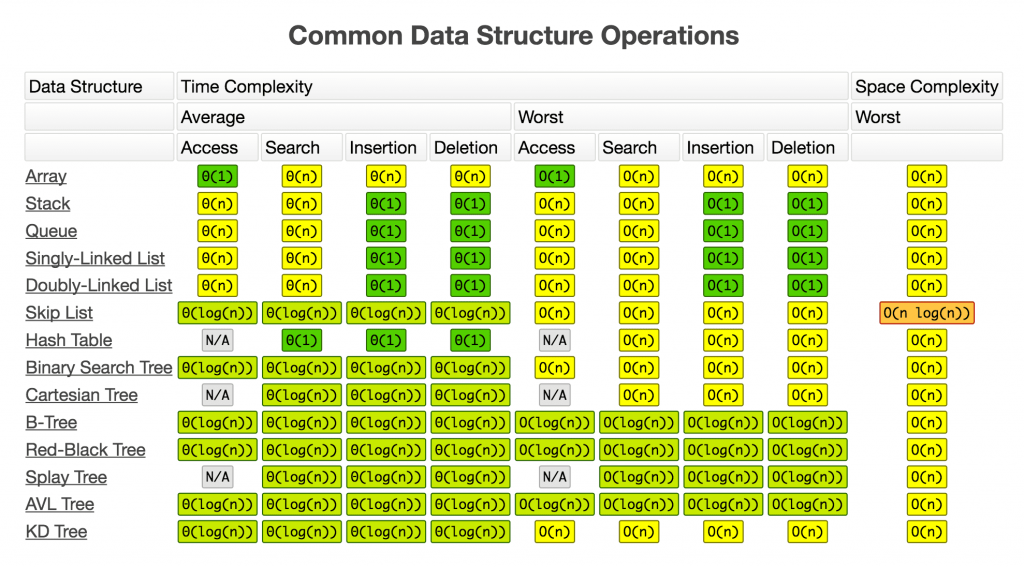
Таким образом, современный разработчик должен понимать (и это важно), что существуют не только разные типы, но и разные структуры данных, причем они по-разному эффективны для решения поставленных задач. Поэтому наличие соответствующих знаний позволяет правильно выбирать структуру с учетом предполагаемых операций, времени и сложности, чтобы потом максимально грамотно ее использовать.
Теперь поговорим о самом «ярком представителе жанра», нередко используемом в ежедневной разработке, причем вне зависимости от того, какой язык программирования вы используете. По определению это массив.
Массив как структура данных
Для начала посмотрим на основные операции, которые приходится осуществлять с массивом, а также выполним анализ сложности.
Представим, что у нас есть следующий массив:
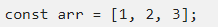
Что вообще с ним можно сделать? Ну, к примеру, получить нужный элемент, обратившись к индексу.

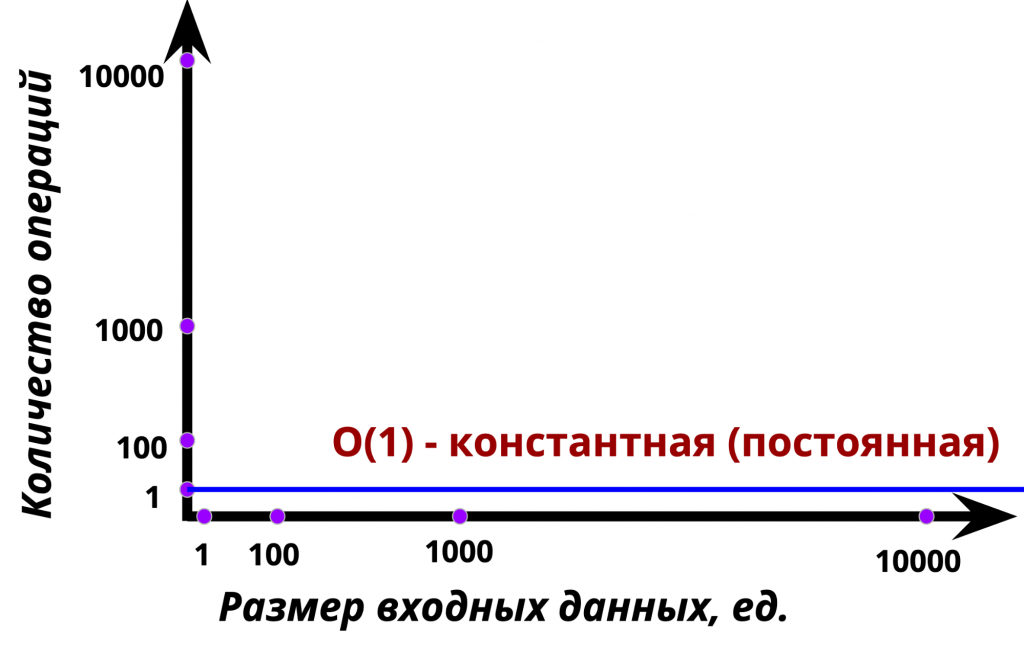
Какова сложность такой операции? Если вы подумали про O(1), то вы абсолютно правы. В этом случае число операций не растет и является постоянным, что справедливо, по сути, при любых входных значениях.
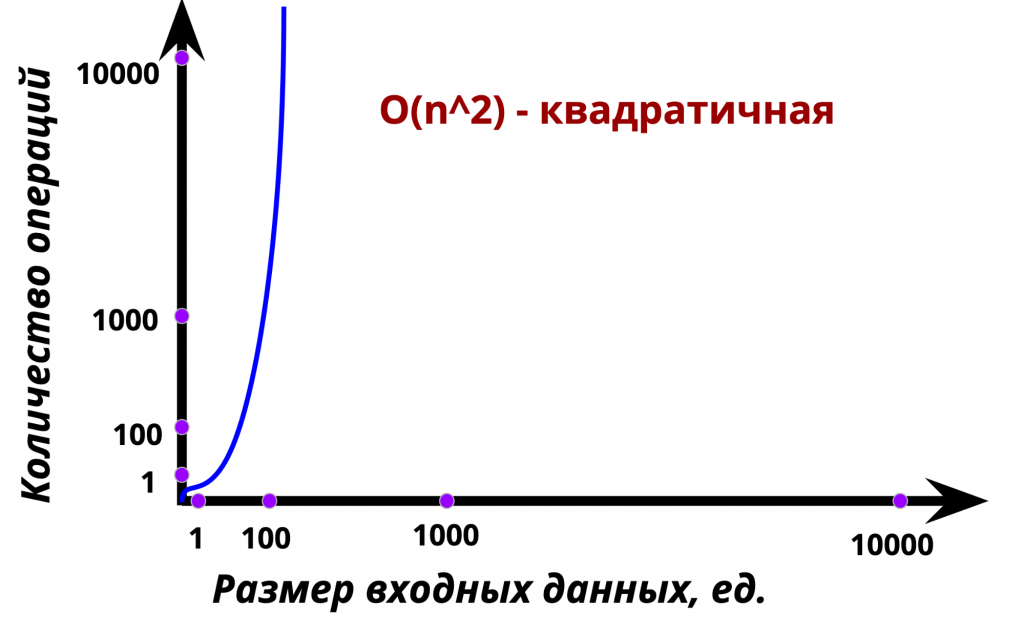
Для сравнения приведем график квадратичной сложности, где разработчика может ожидать резкое увеличение сложности, причем, как порой даже кажется, на ровном месте.
Но вернемся к нашей сложности O(1). Разработчик, используя индекс (уникальный идентификатор), может мгновенно получить любой элемент массива, причем даже несуществующий (в таком случае будет undefined). Точно так же по индексу можно выполнять и запись.

Но в идеале так делать все же обычно не стоит, так как это чревато неприятными последствиями: к примеру, можно получить «дырки» в нашем массиве и другие «радости мутаций». Однако это тема отдельного разговора. Мы же лучше поговорим о методах. Добавим элемент в конец массива:

Сложность операции будет тоже O(1).
А что насчет удаления с конца?
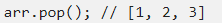
Тут мы тоже имеем O(1). Неплохо. Давайте посмотрим, что у нас получается при добавлении и удалении с начала массива:

А вот здесь несколько иная картина. И вставка, и удаление элементов с начала списка обладают линейной сложностью О(n).
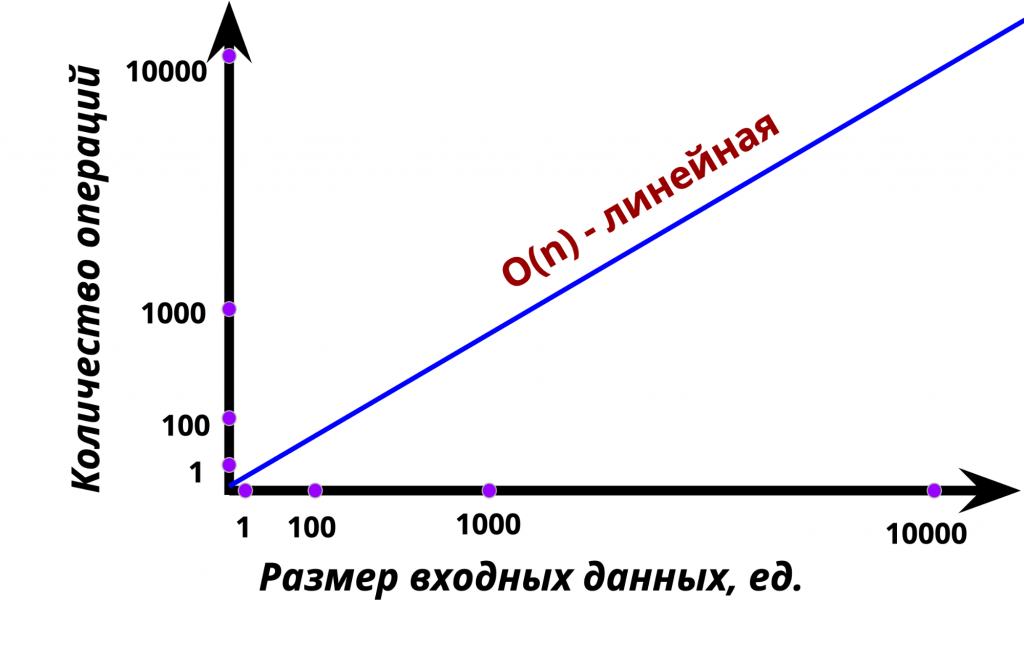
А все потому, что при манипуляции элементами из начала списка нам надо обновлять индексы всех последующих элементов. Когда происходит удаление, элемент, который был вторым, должен уже стать первым, а вторым станет третий и так далее. Аналогично и при вставке в начало: надо обновлять индексы всех последующих элементов.
Таким образом, это уже менее эффективно. Именно потому разные реализации стеков (stack) основываются не на unshift & shift, а на push & pop. Немного отвлечемся и вспомним про такую структуру данных, как стек. Стек можно представить как стопку книг: лежащую сверху мы берем для чтения первой, а если добавляем новую книгу, то кладем ее поверх стопки, то есть теперь уже она становится первой для чтения. Такой подход называют LIFO — last in, first out. Наиболее популярными в разработке являются различные стеки операций, к примеру:
— стек изменений в редакторе кода (для получения возможности быстро отменять изменения, возвращаясь к предыдущим состояниям);
— стек передвижения по веб-страницам в браузере (для обеспечения быстрого перехода по страницам).
Также стоит упомянуть и прочие методы работы с массивами, имеющие сложность О(n) — это, по сути, почти все основные методы, используемые при работе с массивами — всё, что мы ищем, фильтруем, переворачиваем, перебираем и даже трансформируем в строку (toString) — всё вышеперечисленное имеет сложность O(n).
На этом все, если хотите знать большое, вам могут быть полезны следующие статьи:
— «Топ-8 структур данных для программиста»;
— «Дерево как структура данных. Двоичные деревья».
Источник: https://dou.ua/lenta/articles/what-you-should-know-about-algorithms/.





