
В далеком 1976 году швейцарским ученым была написана книга «Алгоритмы + Структуры данных = Программы». Прошло уже более сорока лет, но это утверждение до сих пор актуально. Вы должны знать структуры данных, если учите языки программирования и желаете стать разработчиком. И не только знать, но и уметь их применять. Причем не столь важно, закончили ли вы институт либо просто освоили курсы программирования, — на собеседовании при устройстве на работу у вас в 90 % случаев спросят про структуры данных.
Этот материал — адаптированный перевод статьи «The top data structures you should know for your next coding interview». В этом переводе будут вкратце рассмотрены основные структуры данных, которые могут понадобиться при программировании, плюс будут перечислены наиболее популярные вопросы, которые часто задают на собеседованиях.
Изучаем структуры данных: что это?
Если говорить простым языком, то структура данных представляет собой контейнер, в котором информация скомпонована специальным образом. Чего удается достичь благодаря такому строению? Для сравнения, скажем, что при выполнении одних операций определенная структура данных будет весьма эффективна, в то время как при выполнении других — не очень. Задача разработчика вне зависимости от языка программирования (language of programming) как раз в том и состоит, чтобы уметь выбирать наиболее подходящую структуру и знать, как сравнить их между собой с учетом поставленной задачи. Но это невозможно без ясного и единого представления о существующих способах организации информации. Именно это единое представление вы и получите в процессе изучения материалов этой статьи. И займет это совсем немного времени.
Изучаем структуры данных: зачем вообще они нужны?
Структура позволяет хранить информацию в упорядоченном виде, а информация — это основополагающий термин информатики, что понятно даже, исходя из словообразования. И не так уж важно, какую конкретно задачу решает программист: таки или иначе он все равно будет иметь дело с обработкой данных, причем хранить их надо будет то в одном формате, то в другом.
Изучаем структуры данных: топ-8
Ниже перечислены самые распространенные способы структурирования данных:
- Массивы.
- Очереди.
- Стеки.
- Деревья.
- Связные списки.
- Графы.
- Боры.
- Хэш-таблицы.
Массивы
Самый распространенный способ структуризации. Ниже показан простейший массив из 4-х элементов:
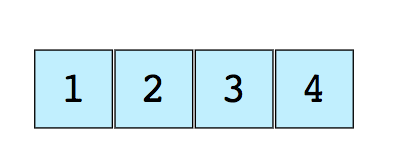
Каждый элемент имеет числовое значение (индекс), которое соответствует положению элемента в массиве. Обычно в языках программирования нумерация начинается не с единицы, а с нуля.
Массивы бывают:
— одномерные (как на картинке);
— многомерные.
Простейшие операции:
- Insert — вставка элемента на позицию с заданным индексом;
- Get — возвращение элемента, занимающего позицию с заданным индексом;
- Delete — удаление;
- Size — получение общего числа элементов.
Какие вопросы, связанные с массивам, часто задают на собеседовании:
- найдите 2-й минимальный элемент;
- найдите неповторяющиеся целые числа;
- выполните объединение двух отсортированных массивов;
- выполните упорядочение положительных и отрицательных значений.
Стеки
Стек обычно сравнивают со стопкой книг. Когда нужно взять какую-либо книгу, к примеру, лежащую в центре стопки, вам надо сначала снять те книги, которые лежат выше. Это известный принцип LIFO (кто последний пришел, тот первый выйдет).
На картинке ниже — стек, который содержит 3 элемента:
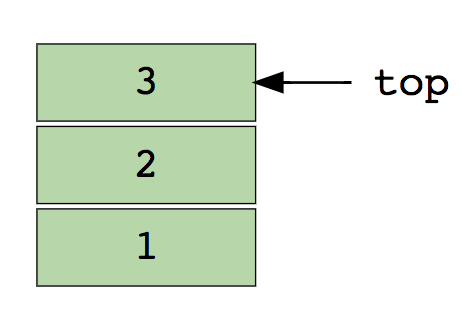
Простейшие операции:
- Push — вставка элемента в стек сверху;
- Pop — возвращение верхнего компонента в стек после удаления;
- isEmpty — возвращение true, когда стек пуст;
- Top — возвращение верхнего компонента без удаления его из стека.
Вопросы о стеке:
- вычислите постфиксное выражение посредством стека;
- отсортируйте значения;
- проверьте сбалансированные скобки в выражении.
Очереди
Очередь представляет собой линейную структура данных, где элементы хранятся последовательно. Однако при сравнении со стеком мы увидим, что здесь действует уже принцип FIFO (первый пришел — первый вышел). Классический пример — очередь покупателей в гипермаркете.
Изображение очереди:
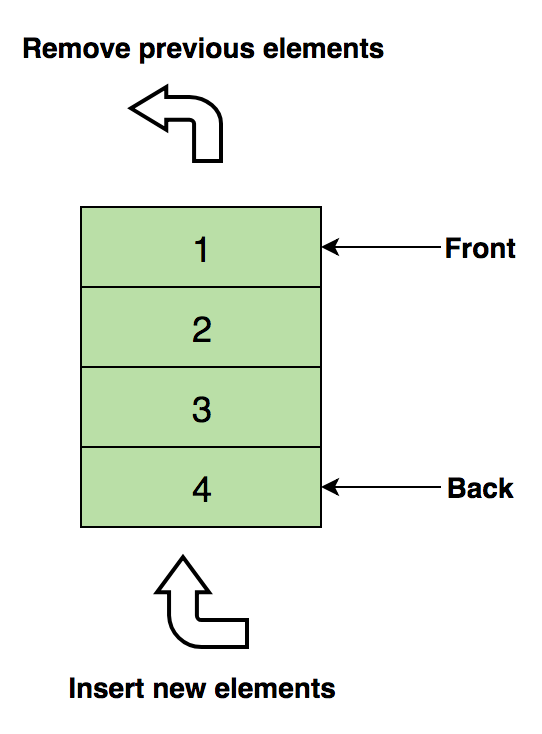
Операции:
- Enqueue() — добавление элемента в конец очереди;
- Dequeue() — удаление элемента из начала;
- isEmpty() — возвращение true, если очередь пуста;
- Top() — возвращение первого элемента.
Вопросы:
- реализовать стек посредством очереди;
- обратить первые k-элементы в очереди;
- сгенерировать двоичные числа от 1 до n, используя очередь.
Связный список
Эта структура напоминает массив, но если выполнить сравнение, становится понятно, что связный список отличается по ряду характеристик:
— выделение памяти;
— внутренняя структура;
— особенности вставки и удаления.
Связный список можно назвать цепочкой узлов, причем каждый из них содержит информацию: к примеру, данные и указатель на последующий узел в цепочке. Существует головной указатель, который соответствует первому элементу в списке, а если список пуст, то указатель направлен на null.
Применение — реализация файловых систем, хэш-таблицы, списки смежности.

Типы:
- односвязный (однонаправленный);
- двусвязный (двунаправленный).
Простейшие действия:
- InsertAtEnd — вставка заданного элемента в конец;
- InsertAtHead — вставка в начало (с головы);
- Delete — удаление из списка;
- DeleteAtHead — удаление первого компонента;
- Search — возвращение заданного компонента из списка;
- isEmpty — возвращение true, если имеющийся список пуст.
Вопросы:
- обратить связный список;
- найти петлю;
- вернуть N-ный узел с начала списка;
- удалить дублирующиеся значения.
Графы
Графом называют множество узлов, которые соединены друг с другом, образуя сеть. Узлы = вершины. Пара (x, y) — это ребро, которое может иметь стоимость или вес, что характеризует, насколько затратным является переход от одной вершины к другой.
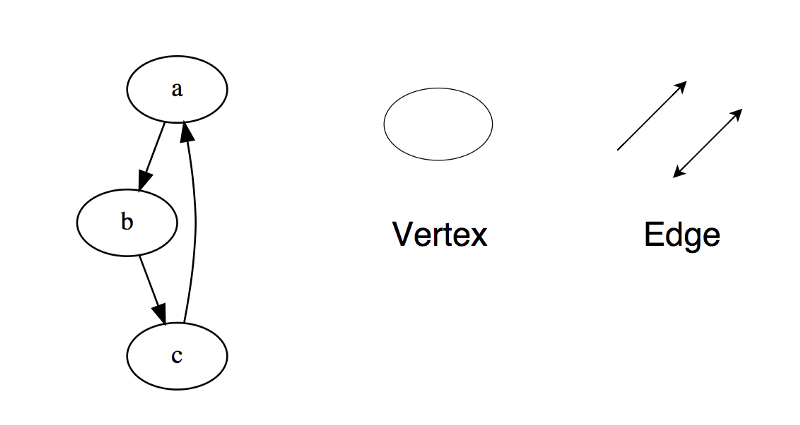
Типы:
- неориентированные;
- ориентированные.
В языке программирования популярны графы 2-х типов:
- матрица смежности;
- список смежности.
Также надо знать самые популярные алгоритмы обхода графа:
- поиск в ширину;
- поиск в глубину.
Вопросы к собеседованию, которые желательно проработать:
- реализация поиска в ширину и глубину;
- проверка, является ли граф деревом;
- подсчет числа ребер;
- поиск кратчайшего пути между 2-мя вершинами.
Деревья
Деревья — иерархическая структура, которые состоят из вершин и ребер, соединяющих эти вершины. Мы можем сказать, что деревья подобны графам, но тут существует различие: у первых не бывает циклов.
Сегодня деревья применяются в сфере ИИ, а также в сложных алгоритмах, где они выступают в роли эффективного хранилища данных. С деревом знаком, по сути, любой программист.
Ниже — рисунок простого дерева:
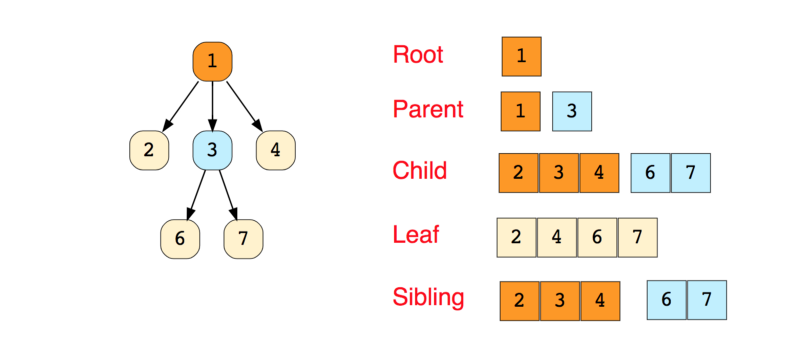
Деревья бывают разных типов:
- N-арное;
- сбалансированное;
- двоичное;
- двоичное дерево поиска;
- АВЛ-дерево;
- красно-черное дерево;
- 2—3 дерево.
Сегодня широко используют двоичные деревья.
На собеседовании у вас могут попросить найти:
- высоту двоичного дерева;
- k-ное максимальное значение в 2-чном древе поиска;
- узлы, которые расположены на расстоянии “k” от корня;
- предки заданной вершины в 2-чном дереве.
Бор
Второе название — «префиксное дерево». Речь идет о древовидной структуре, которая весьма эффективна в процессе решении задач на строки. Бор обеспечивает быстрое извлечение информации и часто используется при поиске слов в словаре, автоматических завершений в поисковике, а также в IP-маршрутизации.
Давайте посмотрим, как 3 слова «top», «thus» и «their» хранятся в бору:
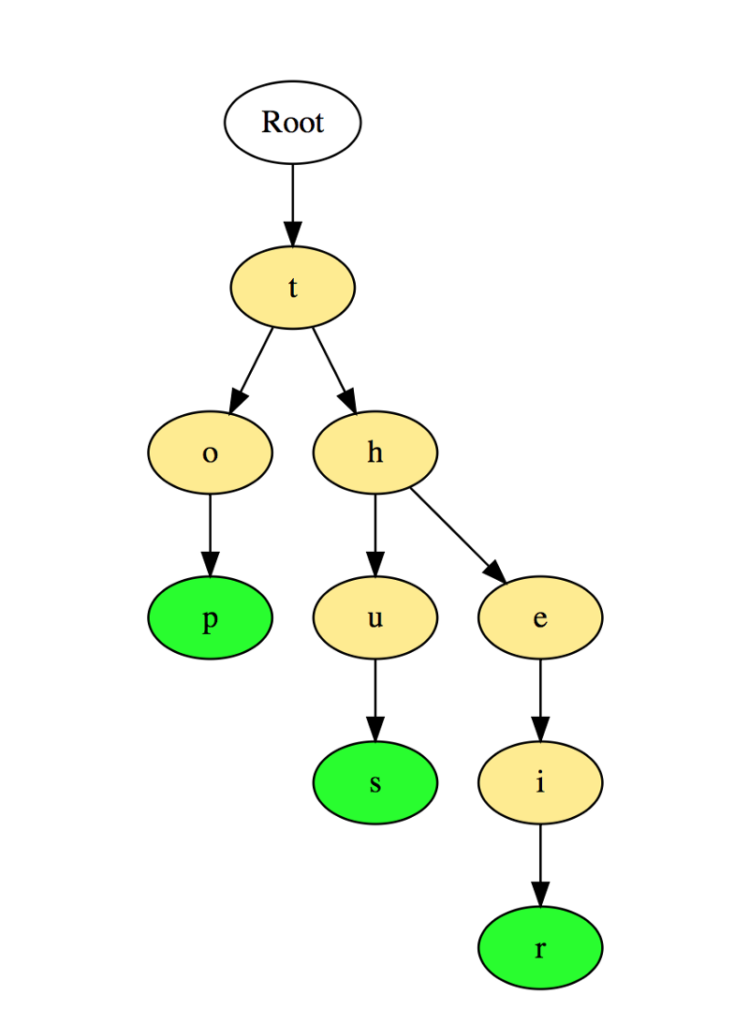
Вопросы:
- подсчет общего числа слов, которые сохранены в бору;
- вывод на экран всех слов, сохраненных в бору;
- сортировка элементов массива посредством бора;
- построение слова из словаря;
- создание словаря T9.
Хэш-таблица
Хэширование используется в целях уникальной идентификации и сохранения объектов по вычисленному индексу, который называют «ключом». В результате объект хранится в формате «ключ-значение», а коллекция этих объектов представляет собой «словарь». Поиск объекта осуществляется по его ключу. Есть разные структуры данных, которые построены по принципам хэширования, к примеру, широко известна хэш-таблица (обычно ее реализуют посредством массивов).
От чего зависит производительность хэширующей структуры:
- от хэш-функции;
- от размера хэш-таблицы;
- от метода обработки коллизий.
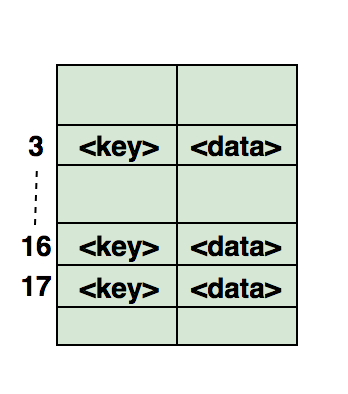
Что могут спросить:
- поиск симметричных пар;
- отслеживание полной траектории пути;
- поиск, является ли массив подмножеством другого массива;
- проверка, можно ли назвать массивы непересекающимися.
Надеемся, этот перевод был вам полезен, и теперь вы имеете единое понимание основных структур данных, которые должен знать каждый разработчик. Мы уверены, что предоставленная информация обязательно поможет на собеседовании по программированию. Успехов!


