
Кластерный анализ – это многомерная статистическая процедура. Она отвечает за сбор данных, содержащих в себе сведения о выборке объекта. Упорядочивает имеющиеся объекты в сравнительно однородные группы. Кластеризация встречается повсеместно – не только в математике, но и в IT. Именно поэтому необходимо изучить соответствующий вопрос более подробно.
В этой статье будет рассказано о методе кластерного анализа, а также о так называемом евклидовом расстоянии. Предложенная информация пригодится не только разработчикам, но и другим специалистам. Даже тем, кто далек от IT-направления.
Ключевые задачи
Кластерный анализ (соответствующее понятие появилось в 1939 году) – это достаточно обширное понятие. Оно включает в себя набор разных алгоритмов классификации. Рассматриваемая сфера помогает организовывать наблюдаемые данные в наглядные структуры. Пример – в биологии нужно поделить животных на различные виды для описания ключевых различий между ними.
Википедия и иные источники достоверных данных говорят о том, что применения кластеризации обширно и разнообразно. Она встречается в большинстве наук, а также в программировании и разработке.
Поисковики и Википедия указывают на то, что методы кластерного анализа выполняют следующие задачи:
- создание типологии и способов классификации имеющихся данных;
- изучение полезных концептуальных схем группировки заданных объектов;
- выдвижение различных гипотез, опирающихся на полученных в ходе проведенных исследований данные;
- проверка гипотез для определения грамотности классификации и соответствия полученной информации.
Соответствующее понятие нашло широкое применение в статистике, математике, а также работе с BigData.
О целях
Метод кластеров (cluster method) – концепция, которая имеет не только определенные задачи, но и цели. Независимо от того, в какой сфере деятельности применяется подобная концепция, она нужна для:
- Понимания данных путем выявления структуры кластеров. Разделение выборки на конкретные группы схожих между собой объектов дает возможность упрощения дальнейшую обработку данных с последующим принятием решения. К каждому кластеру будет применять собственный метод анализа. Это – принцип «разделяй и властвуй» в действии. Он активно применяется в статистике и BigData.
- Сжатие данных. Если количество исходной информации в выборке достаточно большое, можно его сократить. Для этого необходимо оставить по одному наиболее типичному представителю для каждого кластера.
- Обнаружение новизны. Вследствие данной цели нужно выявить нетипичные объекты. Такие, которые не получится присоединить к уже имеющимся кластерам.
Первая цель предусматривает относительно небольшое количество кластеров. Их стараются сформировать так, чтобы было невозможно запутаться. Во второй ситуации намного важнее обеспечить высокий уровень сходства объектов внутри каждого отдельно взятого кластера. Их количество меняется в зависимости от конкретной ситуации. Третья цель в качестве основной интересующей составляющей выделяет отдельные компоненты. Такие, которые не вписываются ни в один из ранее сформированных кластеров.
Во всех перечисленных ситуациях поддерживается кластеризация (clustering) иерархического характера. В ней крупные кластеры разделяются на более мелкие, те – делаются еще мельче, и так далее. Такие задачи носят название таксономии. Применение подобной концепции приводит к образованию так называемой древообразной иерархической структуры. Каждый объект тут будет характеризоваться путем перечисления всех кластеров, к которым он имеет отношение. Чаще – от самого крупного к наиболее мелкому.
Типы входных сведений
Тип входной информации для statistica и иных наук при кластеризации играет огромную роль. Можно выделить следующие варианты:
- Описание объектов по знакам. Каждый элемент будет описываться за счет набора собственных характеристик. Они носят название признаков. Бывают числовыми и нечисловыми.
- Составление элемента под названием «Матрица расстояния» между объектами. Каждый компонент описывается расстоянием до всех остальных в пределах метрического пространства. Здесь на помощь приходит понятие «Евклидово расстояние».
- Формирование матрицы сходства. При анализе и статистике будет учитываться степень схожести объектов в метрическом расстоянии. Сходство дополняет расстояние (различие) между элементами до 1.
Современная наука и statistica выделяют несколько алгоритмов обработки входных данных. Можно действовать через сравнивание компонентов, отталкиваясь от имеющихся признаков (пример – биологические науки и дробление живых существ на различные типы и виды). Это – Q-тип. Если происходит сравнение признаков на основе объектов, речь пойдет об R-типе. Некоторые специалисты при анализе кластеров используют смешанные типы – QR. Соответствующая методология пока не пользуется спросом из-за своей «тяжести». Википедия указывает на то, что широкого использования подобная концепция пока не достигла.
Основные этапы
Методика кластеризации получила распространение в statistica и иных научных сферах. Пример – биология и работа с BigData. Независимо от того, где именно будет применяться кластерный анализ, он всегда подразделяется на этапы.
В качестве «базы» используется такой алгоритм:
- Отбор выборки для дальнейших операций. Здесь подразумевается, что есть смысл делить на кластеры только количественные данные (те сведения, в которых есть числа).
- Определение множества переменных для дальнейшей оценки в выборке. Это – признаковое пространство.
- Вычисление значений выбранных мер сходства и отличий между имеющимися компонентами.
- Применение кластерного анализа для создания групп элементов, схожих между собой.
- Проверка достоверности полученных результатов.
Сколько конкретно этапов будет в исследовании, зависит от предметной области, но предложенная концепция является базовой. К изначальным сведениям выдвигаются требования относительно однородности и полноты. В первом случае тяжесть понимания небольшая: сущности, с которыми планируется работа, должны относиться к одному типу природы. Если ранее было проведено факторное исследование, то «ремонт» выборки не пригодится – выдвинутые требования выполняются автоматически факторным моделированием. В противном случае имеющуюся выборку придется откорректировать.
О расстояниях
Примеры кластерного анализа изучены, основные его концепции – тоже. Теперь можно рассмотреть понятие евклидова расстояния. Оно помогает определять схожесть между исследуемыми компонентами.
При работе с кластерами в статистике и иных науках могут пригодится следующие понятия:
- Евклидово расстояние. Общий тип «измерения». Выступает геометрическим расстоянием в многомерном пространстве. Вычислить его можно по такой формуле:
.
- Квадрат Евклидова расстояния (Евклидов квадрат). Его применение зависит от тяжести оценки данных. Позволяет придавать больше веса более отдаленным друг от друга элементов в кластере. Вычисляется так:
.
- Манхэттенское расстояние. Средняя разность по координатам. Чаще всего приходит к тем же результатам, что и в случае с Евклидовым. Влияние этой меры для больших выбросов уменьшается:
.
- Чебышева. Полезно, если нужно определить два компонента как элементы «разной тяжести» или «различные». Применяется, если они отличаются по одной координате:
.
- Степенное. Нужно для уменьшения или увеличения веса, относящегося к размерности, для которой элементы сильно отличаются:
.
Также предстоит рассмотреть процент несогласия.
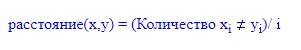
Кластерный анализ использует его, если данные являются категориальными.
Как быстро изучить
Лучше понять рассмотренное понятие помогут специализированные курсы от образовательного онлайн центра. Это отличное дополнение к специализированной литературе и видео-урокам. Пример – от OTUS. Школа позволяет дистанционно освоить не только инновационные IT-профессии в сжатые сроки, но и познакомиться с иными актуальными сферами деятельности.
В течение курса, который может длиться до 12 месяцев, человека с нуля научат программировать, анализировать и даже создавать сложные 3D-модели с нуля. В пределах дистанционного образовательного центра гарантированы интересные домашние задания, постоянное кураторство и богатая практика. По завершении обучения будет выдан электронный сертификат. С его помощью ученик сможет подтвердить полученные навыки и знания, а также умения в выбранной области.
Также можно отдать предпочтение самообразованию. Здесь придется всю информацию искать самостоятельно, а подтвердить навыки не получится. Останется концентрироваться на практике и участвовать в различных тематических мероприятиях.
А еще некоторые предпочитают получать среднее профессиональное образование в выбранном направлении. Неплохое решение для тех, кто планирует дальнейшее поступление в ВУЗ. Рассмотренная тема изучается на математическом факультете.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!
Также вам может быть интересен следующий курс:



