
В этой статье поговорим о том, что является структурой данных, какие структурированные типы наиболее распространены, что такое обобщенные модели, какие компоненты к этим моделям относятся.
Весь мир вокруг нас состоит из информации, и один из способов ее представления — это числа. Хорошо известно, что информация, хранимая в памяти электронной вычислительной техники, представляют собой, по сути, совокупность единиц и нулей (такой способ представления называется битовым). Биты объединяются в определенные последовательности — байты, а каждый участок оперативной памяти, который способен вместить 1 байт, имеет свой адрес, то есть порядковый номер.

8 битов или 1 байт — это основа и для представления символов. Вне зависимости от того, буквенные это или цифровые значения, их надо как-то обрабатывать. И чтобы эта обработка была более эффективна, значения структурируют, то есть упорядочивают. Таким образом образуется структура данных — эффективный способ их организации. Как следствие, упрощается работа, происходит экономия времени. То есть мы получаем некое множество компонентов и связей между ними — в качестве примера можно привести те же элементы в списке.
Любую структуру можно разделить на два следующих типа:
— простая — форма представления определена архитектурой электронно-вычислительной техники;
— сложная — форма представления конструируется и формируется пользователем в целях решения конкретных задач.
Что является простой структурой данных?
На практике простая структура данных представляется числами, символами и т. п., то есть речь идет об элементах, в дальнейшем дроблении которых отсутствует смысл. Важно добавить, что из простых (элементарных) структурированных конструкций уже образуются сложные.
Структуризация на примерах
Рассмотрим некоторые наиболее распространенные структуры. Одна из самых популярных называется массивом.
Массив можно назвать функцией с конечной областью определения. По сути, это простая совокупность элементов одного типа или средство оперирования группой однотипных данных. Отдельный элемент массива задают индексом. Сам по себе массив бывает одномерным, 2-мерным, многомерным. Когда мы говорим об одномерных массивах переменной длины, мы должны упомянуть такие его разновидности, как стек (Last In, First Out) и очередь (First In, First Out).

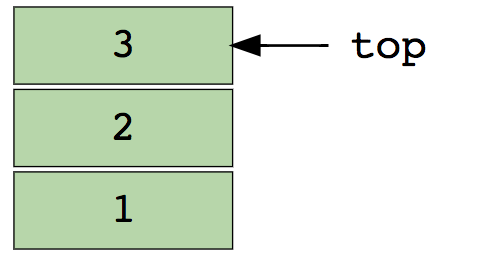
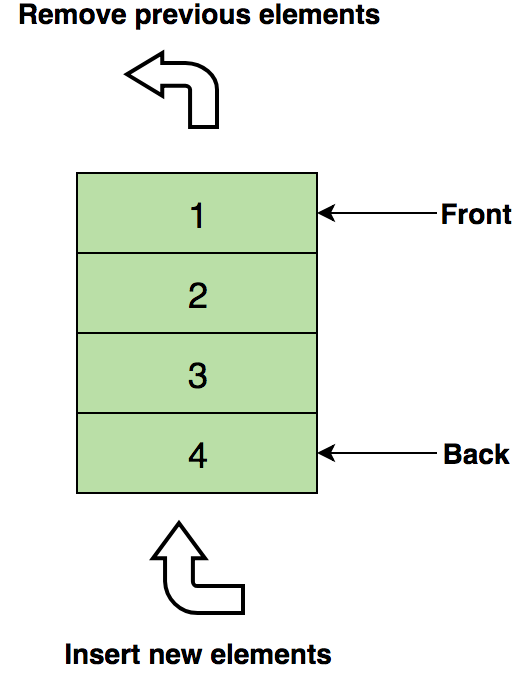
Отдельного упоминания заслуживает запись (декартово произведение). Она представляет собой совокупность связанных структурированных элементов разнотипных данных. В самом простом случае запись включает в себя некое постоянное число элементов, называемых полями. Совокупность записей, структурированных одинаково, называют файлами. Чтобы существовала возможность по извлечению из файла отдельных записей, каждой такой записи присваивают уникальный номер либо имя, которые используются в качестве идентификатора записи, располагаясь в отдельном поле. Также этот идентификатор называют ключом.
Виды структуризации по отношению к памяти ЭВМ
Тот же массив либо запись обычно занимают в памяти электронной вычислительной техники постоянный объем, используемый при выполнении программ и не изменяемый со временем. В результате говорят о статических структурах. К ним же относятся и множества.
Однако существует структурированные конструкции, способные менять свою длину — их называют динамическими структурами. Сюда относятся, к примеру, деревья или связные списки.
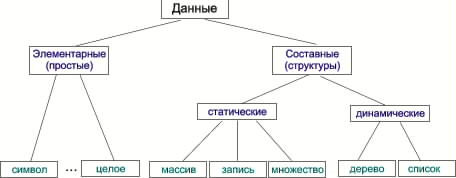
Скажем несколько слов о дереве. Для размещения элементов в этом случае требуется нелинейное адресное пространство. Обычно это структуры иерархического строения, которые состоят из вершин и ребер. Один из классических примеров — бинарное (двоичное) дерево. В качестве деревьев может быть представлена и другая структура: рекурсивная, классификационная и пр.
Модели данных
Выше мы рассматривали простейшие способы структуризации. Однако давайте вспомним, что данные могут быть организованы и более сложным способом — в таком случае тот же массив или дерево будут включены в другую структу ру данных в качестве элементов. К примеру, представьте себе запись, элементами которой являются стек, массив, дерево и т. п.
Существует много сложных типов, однако специалисты выделяют лишь обобщенные. Эти так называемые обобщенные структуры данных представляют собой модели данных, отражающие представления пользователей о реальном мире.
Любая такая модель содержит три компонента:
- структура данных. С помощью этого компонента описывается точка зрения пользователя на представление данных;
- набор допустимых операций. Модель данных предполагает наличие ЯОД — языка определения данных, который описывает структуру их хранения. Вдобавок к этому, необходим язык манипулирования данными (ЯМД) — по-английски он называется Data Manipulation Language (DML). Язык включает в себя операции по извлечению, добавлению и модификации имеющихся данных. Классический пример DML — декларативный язык программирования SQL;
- механизм ограничения целостности. Позволяет поддерживать соответствие данных предметной области, опираясь в своей основе на формально описанные правила.
Модели имеют свое историческое развитие. Достаточно вспомнить виды систем управления БД, которые тоже представляют собой модели:
- иерархические,
- сетевые,
- реляционные,
- объектно-реляционные,
- объектно-ориентированные.
По материалам http://www.mstu.edu.ru/study/materials/zelenkov/ch_1_1.html.




