
На этапе создания спецификаций и требований, необходимых для разработки качественного ПО, важно определить структуру и формат данных, используемых в программном приложении. Каким же образом классифицируются структуры данных? Какие форматы представления данных используются? Чем различаются статические, динамические и полустатические структуры? Об этом — наша статья.
Вне зависимости от сложности и содержания любые данные представлены в памяти электронно-вычислительных устройств (ЭВМ) в виде последовательности битов (двоичных разрядов), причем их значения — это соответствующие двоичные числа. Однако сами по себе битовые последовательности структурированы недостаточно, поэтому они не очень удобны для практического использования. Именно поэтому на практике применяют структуры данных, которые организованы более сложно. Понятие структуры тесно связано с понятием типа данных.
Классификация
Структуры данных бывают физические и логические. В отличие от последних, физические отражают, по сути, способ представления данных в памяти ЭВМ, поэтому их называют еще и внутренними.
По своему составу структуры данных классифицируют на следующие типы:
— простые. Их нельзя разделить на составные части, которые больше, чем биты, то есть мы говорим о неделимых единицах. Для простого типа ясно определен размер и способ размещения структуры в памяти ПК;
— сложные, они же интегрированные. Состоят из других структур данных, которые бывают как простые, так и, в свою очередь, тоже сложные.
По наличию связей структуры бывают:
— несвязные: массивы, векторы, строки, стеки (Last In, First Out), очереди (First In, First Out);
— связные (к примеру, связные списки).
Также существует понятие изменчивости — это изменение количества элементов либо связей между ними. По признаку изменчивости структуры бывают:
— статические;
— полустатические;
— динамические.
Классификацию можно посмотреть на картинке ниже:
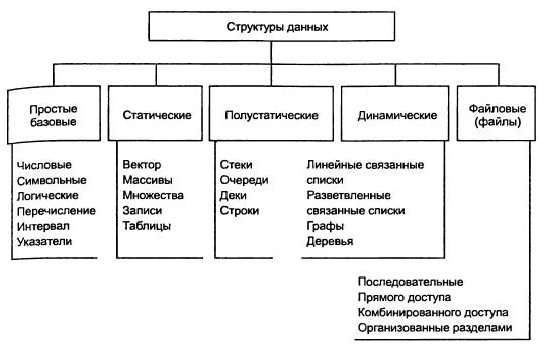
Здесь отдельного упоминания заслуживают файлы как структуры данных. Файлами называют, к примеру, совокупность записей, структурированных одинаково. Файлы бывают:
— последовательные;
— прямого или комбинированного доступа;
— организованные разделами.
Следующий критерий — характеристика упорядоченности элементов. По признаку упорядоченности структуры бывают:
— нелинейные: деревья, графы, многосвязные списки;
— линейные. По характеру распределения компонентов в памяти ЭВМ они могут иметь последовательное распределение (строки, векторы, массивы, стеки, очереди) и произвольное связное распределение (односвязные и двусвязные списки).
Когда мы указываем тип данных, мы четко определяем:
— размер памяти, который отводится под конкретную структуру;
— способ размещения структуры в памяти;
— значения, которые допустимы для этого типа данных;
— операции, которые поддерживаются.
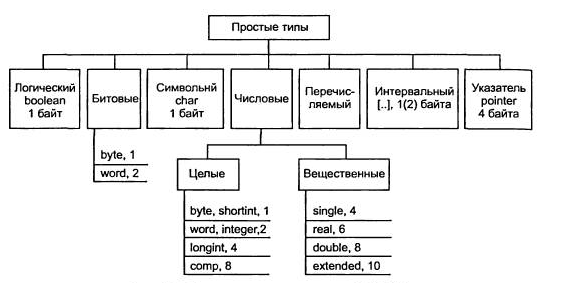
Простые структуры данных
Как уже было сказано выше, это основа для создания более сложных структур. Также простые структуры называют примитивными либо базовыми (типами данных). Какие структуры сюда относят:
— битовые,
— числовые,
— логические,
— перечисляемые,
— символьные,
— интервальные,
— указатели.
Для примера — структура простых типов для языка программирования Pascal:
Далее — формат представления беззнаковых чисел:

И формат представления чисел со знаком:

Статические структуры
Это не что иное, как структурированное множество простых структур. К примеру, тот же вектор можно представить упорядоченным множеством чисел. Для статических структур изменчивость несвойственна, ведь размер памяти ЭВМ, который отводится для этих данных, является постоянным, выделяясь на этапе компиляции либо выполнения программы.
Вектор
Вектором также называют и одномерный массив. Это структура данных, где число элементов фиксировано, причем речь идет об однотипных компонентах. У каждого компонента — свой индекс (уникальный номер). С физической точки зрения векторные компоненты размещаются в памяти в ячейках, расположенных подряд.
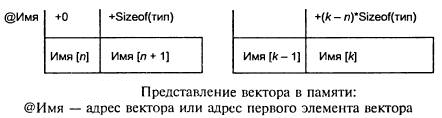
Двумерный массив
Двумерный массив (он же матрица) представляет собой вектор, причем каждый его элемент — тоже вектор. Если учесть внешние сходства, тогда то, что является справедливым для вектора, является справедливым и для матрицы.
Множество
Это набор неповторяющихся данных одного типа. Множество способно принимать все значения базового типа, а так как он не должен превышать 256 значений, то типом элементов множеств могут быть char, byte и их производные.
В памяти множество хранится в виде массива битов, причем каждый бит показывает, принадлежит ли элемент объявленному множеству. Таким образом, максимальное число элементов множества равно 256, а множество может занимать не больше 32 байт.
Записи
Комбинированный тип данных, в котором значения представляют собой нетривиальную структуру. Записи формируются из нескольких полей разного типа, причем внешний доступ к этим полям происходит по именам полей. Из этого можно сделать простейшее заключение: записи — это средство представления программных моделей реальных объектов, ведь реальный объект имеет несколько внешних свойств, описываемых разнотипными данными.
К примеру, с помощью записи можно описать преподавателя университета. В этом случае объект «преподаватель» будет иметь следующие характеристики:
- табельный номер, представленный целым положительным числом;
- фамилия-имя-отчество, представленные строкой символов;
- пол («М», «Ж») — это символ;
- наличие ученой степени — строка символов;
- зарплата — вещественное число;
- и так далее.
В памяти компьютера это можно представить:
— в виде последовательности полей, которые занимают произвольную непрерывную область памяти:

— в виде связного списка, имеющего указатели на значения полей записи:
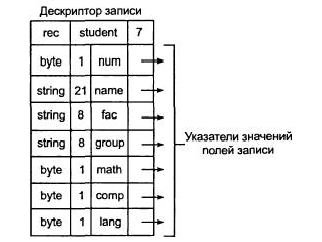
Полустатические структуры
Характеристики:
— переменная длина;
— поддержка простых способов изменения этой длины;
— изменение длины возможно не в произвольных, а в определенных пределах, которые не будут превышать максимально-допустимые (предельные) значения.
С точки зрения логики полустатическая структура — это последовательность данных, связанная отношениями линейного списка. Доступ к элементу возможен по порядковому номеру.
С физической точки зрения полустатические структуры представлены в виде вектора, располагаясь в непрерывной области памяти ПК. Также их можно представить в качестве однонаправленного связного списка, где каждый последующий компонент адресуется указателем, который находится в текущем компоненте.
Примеры: стеки, строки, очереди, деки.
Динамические структуры
Не обладают постоянным размером, в результате чего память выделяется в момент создания элементов либо в процессе выполнения программы. Когда необходимость в элементе отпадает, занимаемая им память освобождается.
Так как компонент находится в памяти не по порядку и не в одной области, его адрес нельзя вычислить из адреса начального либо предыдущего компонента. Именно поэтому компонентная связь формируется через указатели, которые содержат соответствующие адреса в памяти. Это не что иное, как связное представление данных в памяти. Вывод напрашивается сам собой: такое представление обеспечивает высокую изменчивость структуры.
Преимущества:
• размер структуры ограничивается лишь объемом памяти ЭВМ;
• во время изменения логической последовательности элементов (выполнении основных операций по удалению, добавлению, изменению порядка следования) нужна лишь коррекция указателей.
Недостатки:
• работа с указателями требует от разработчика высокой квалификации;
• на указатели тратится дополнительная память;
• на доступ тратится дополнительное время.
Связные линейные списки
Это простейшие динамические структуры. Они представляют собой упорядоченные множества, которые содержат переменное число компонентов, причем отсутствуют ограничения по длине.
Ниже изображен односвязный список:

Что здесь что:
— INF — информационное поле, которое содержит данные;
— NEXT — указатель на последующий компонент списка;
— «Голова списка» — указатель на начало;
— nil — указатель на последний элемент.
На практике использовать и обрабатывать односвязный список не всегда удобно, ведь нельзя перемещаться в противоположную сторону, что ставит под вопрос оперативное выполнение некоторых операций. Однако такая возможность существует у двухсвязного списка, ведь в нем каждый элемент обеспечивает хранение двух указателей: на последующий и на предыдущий компоненты. Также для удобства обработки он имеет особый элемент — указатель конца списка. Но за повышенное удобство и оперативное выполнение операций надо платить — в случае с двухсвязным списком наличие 2-х указателей в каждом компоненте повышает сложность и становится причиной дополнительных затрат памяти.
Заключение
В качестве заключения скажем, что структуризация данных осуществляется сегодня множеством различных способов. Понимание особенностей структур данных, их строения, функций и основных характеристик позволит вам повысить качество создаваемого программного обеспечения, не говоря уже о более оперативной разработке. Также при определении формата данных нужно всегда учитывать специфику поставленных задач, делая это еще на этапе создания спецификаций и требований.
По материалам http://starik2222.narod.ru/trpp/lec2/19.htm.


