

Мощный выпускной проект студента курса «Администратор Linux»

Предлагаем вашему вниманию проектную работу одного из студентов OTUS, выполненную им в рамках обучения на курсе «Администратор Linux». Это высокодоступная кластерная файловая система, интегрированная с кластером СУБД, централизованной системой телеметрии, аудита и авторизации.
1. Описание стенда
Для развёртывания всех компонент системы использовался Vagrant, с помощью которого разворачивался стенд, состоящий из 7 виртуальных машин: — 1 виртуальная машина — центральный сервер телеметрии, аудита и авторизации; — 6 виртуальных машин — кластерная файловая система, кластер СУБД.
Для экономии ресурсов совместили 3 узла кластера СУБД с узлами кластерной файловой системы. Для развёртывания всех компонент системы использовался Ansible.
Названия виртуальных машин: • ns.otus.test (ns) — центральный сервер телеметрии, аудита и авторизации; • master01.otus.test (master01) — узел кластерной ФС, узел кластера СУБД; • master02.otus.test (master02) — узел кластерной ФС, узел кластера СУБД; • master03.otus.test (master03) — узел кластерной ФС, узел кластера СУБД; • node01.otus.test (node01) — узел кластерной ФС; • node02.otus.test (node04) — узел кластерной ФС; • node03.otus.test (node03) — узел кластерной ФС.
1.1 Центральный сервер телеметрии, аудита и авторизации
Для устойчивой работы всех компонент стенда была развёрнута первая виртуальная машина, на которую установили следующие сервисы: • DNS — локальный сервер разрешения имён; • NTP — локальный сервер точного времени; • Kerberos — локальный сервер авторизации; • Prometheus — центральный сервер сбора телеметрии; • Grafana — сервер визуализации телеметрии; • Netdata — центральный сервер сбора и визуализации телеметрии в реальном времени; • Lizardfs-cgi — сервер отображения состояния кластерной файловой системы; • Lizardfs-client — клиент для подключения к кластерной файловой системе; • Haproxy — балансировщик нагрузки на кластер СУБД; • Etcd — key-value база данных для кластера СУБД; • Auditd — центральный сервер для сбора событий аудита всех компонент системы; • Nginx — web-сервер, работающий в режиме reverse-proxy; • Autofs — сервиc автомонтирования сетевых ресурсов.
DNS, NTP, Kerberos и Etcd использовались для интеграции сервисов и их компонент.
1.2 Узлы файловой кластерной системы и кластера СУБД
На всех узлах кластера были развёрнуты следующие вспомогательные сервисы: • NTP — клиент синхронизации с локальным NTP-сервером; • Kerberos — kerberos-клиент; • Auditd — клиент auditd; • Netdata — клиент сбора телеметрии.
На узлах master01-master03 развернули роли: • LizardFS Uraft Master Node — lizardfs-mfsmaster, lizardfs-uraft; • PostgreSQL 11 — сервер PostgreSQL 11; • TimescaleDB — расширение для PostgreSQL, позволяющее использовать постгрес как TimeseriesDB; • Patroni — создание кластера PostgreSQL.
На узлах node01-node03 развернули роли: • LizardFS Node — lizardfs-chunkserver, lizardfs-metalogger; • LVM — управление томами LVM2.
1.3 Использование стенда
После клонирования репозитория в папке с проектом (otus-homework/project) выполнили
Попадаем в ВМ
$ vagrant ssh ns $ echo "vagrant" | kinit $ sudo aureport -x --summary
Далее можно заходить на все ноды кластера без ввода пароля.
2. Компоненты стенда
Общая схема стенда с разделением ролей:
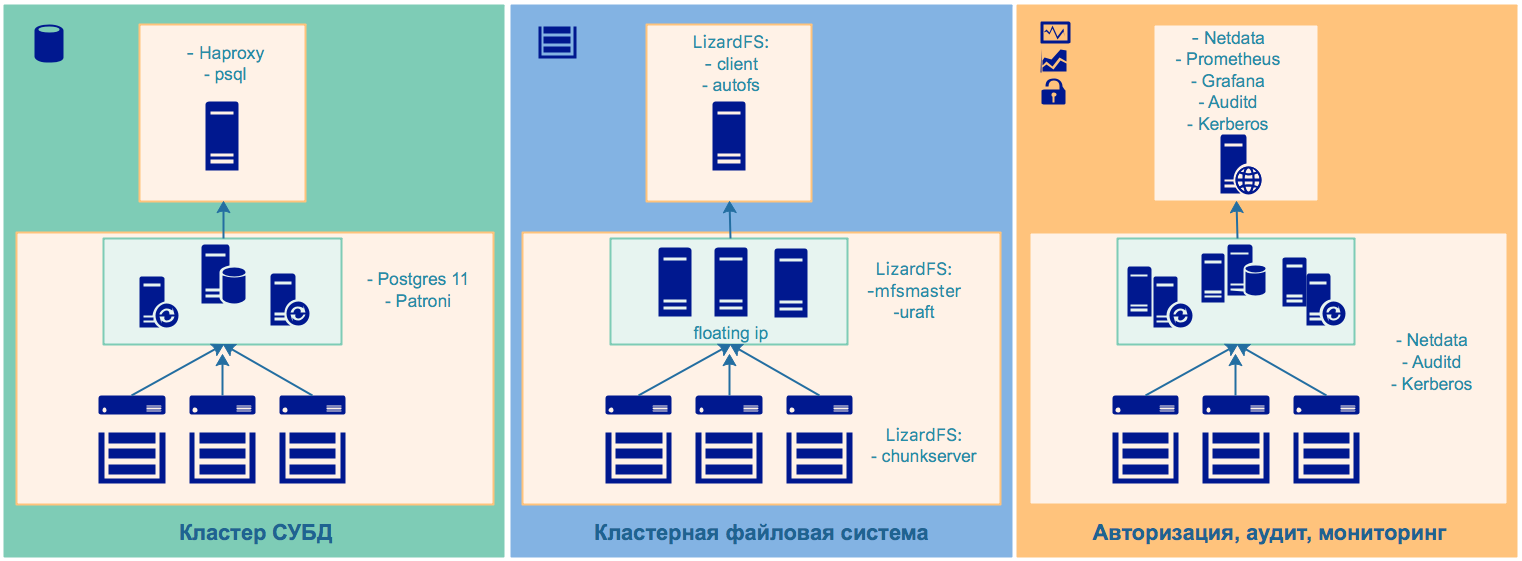
2.1 Высокодоступная кластерная файловая система
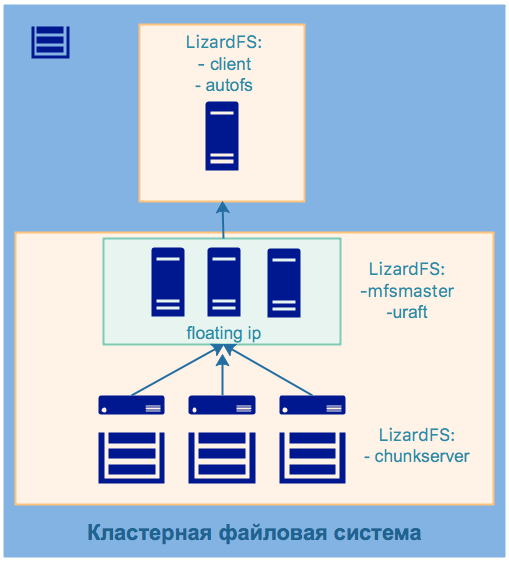 Для проекта была выбрана кластерная файловая система LizardFS. Это распределённая, масштабируемая, отказоустойчивая и высокодоступная файловая система. Она позволяет объединять дисковое пространство, расположенное на многих серверах, в единое пространство имён, которое видно в Unix-подобных системах и системах Windows так же, как и в других файловых системах. LizardFS обеспечивает безопасность файлов, сохраняя все данные во многих репликах на доступных серверах. Её также можно использовать для создания доступного хранилища, поскольку она работает без каких-либо проблем на обычном оборудовании.
Для проекта была выбрана кластерная файловая система LizardFS. Это распределённая, масштабируемая, отказоустойчивая и высокодоступная файловая система. Она позволяет объединять дисковое пространство, расположенное на многих серверах, в единое пространство имён, которое видно в Unix-подобных системах и системах Windows так же, как и в других файловых системах. LizardFS обеспечивает безопасность файлов, сохраняя все данные во многих репликах на доступных серверах. Её также можно использовать для создания доступного хранилища, поскольку она работает без каких-либо проблем на обычном оборудовании.
Отказы дисков и серверов обрабатываются прозрачно, без простоев и потери данных. Если требования к хранилищу растут, можно масштабировать существующую установку LizardFS, просто добавляя новые серверы — в любое время, без простоев. Система автоматически перемещает данные на вновь добавленные серверы, потому что она постоянно заботится о балансировке использования диска на всех подключённых узлах. Удаление серверов так же просто, как добавление нового.
Уникальные функции: • поддержка многих центров обработки данных и типов носителей, • быстрые снимки, • механизмы QoS, • квоты, • ...
LizardFS хранит метаданные (например, имена файлов, метки времени изменения, деревья каталогов) и фактические данные отдельно. Метаданные хранятся на серверах метаданных, а данные хранятся на компьютерах, называемых серверами чанков.
Типичная установка состоит из:
• Как минимум двух серверов метаданных, которые работают в режиме master-slave для восстановления после сбоев. Их роль также заключается в управлении всей установкой, поэтому активный сервер метаданных часто называют главным сервером. Роль других серверов метаданных состоит в том, чтобы просто синхронизировать их с активными главными серверами, поэтому их часто называют теневыми главными серверами. Любой теневой мастер-сервер в любое время готов взять на себя роль активного мастер-сервера.
• Сhunkservers, серверов хранения данных. Каждый файл делится на блоки, называемые чанками (каждый размером до 64 Мб), которые хранятся на серверах чанков. Предлагаемая конфигурация сервера чанков — это машина с большим дисковым пространством, доступным в конфигурации JBOD или RAID в зависимости от требований. Процессор и оперативная память не очень важны. У вас могут быть всего 2 чанк-сервера (минимум, чтобы ваши данные были устойчивы к любым сбоям диска) или до сотен из них. Типичный чанксервер имеет 8, 12, 16 или даже более жёстких дисков. Каждый файл может распространяться на серверы чанков в определённом режиме репликации: standard, xor или ec.
• Клиентов, которые используют данные, хранящиеся в LizardFS. Эти машины используют монтирование LizardFS для доступа к файлам при установке и обработке их так же, как файлы на локальных жёстких дисках. Файлы, хранящиеся в LizardFS, могут быть просмотрены и одновременно доступны как можно большему числу клиентов.
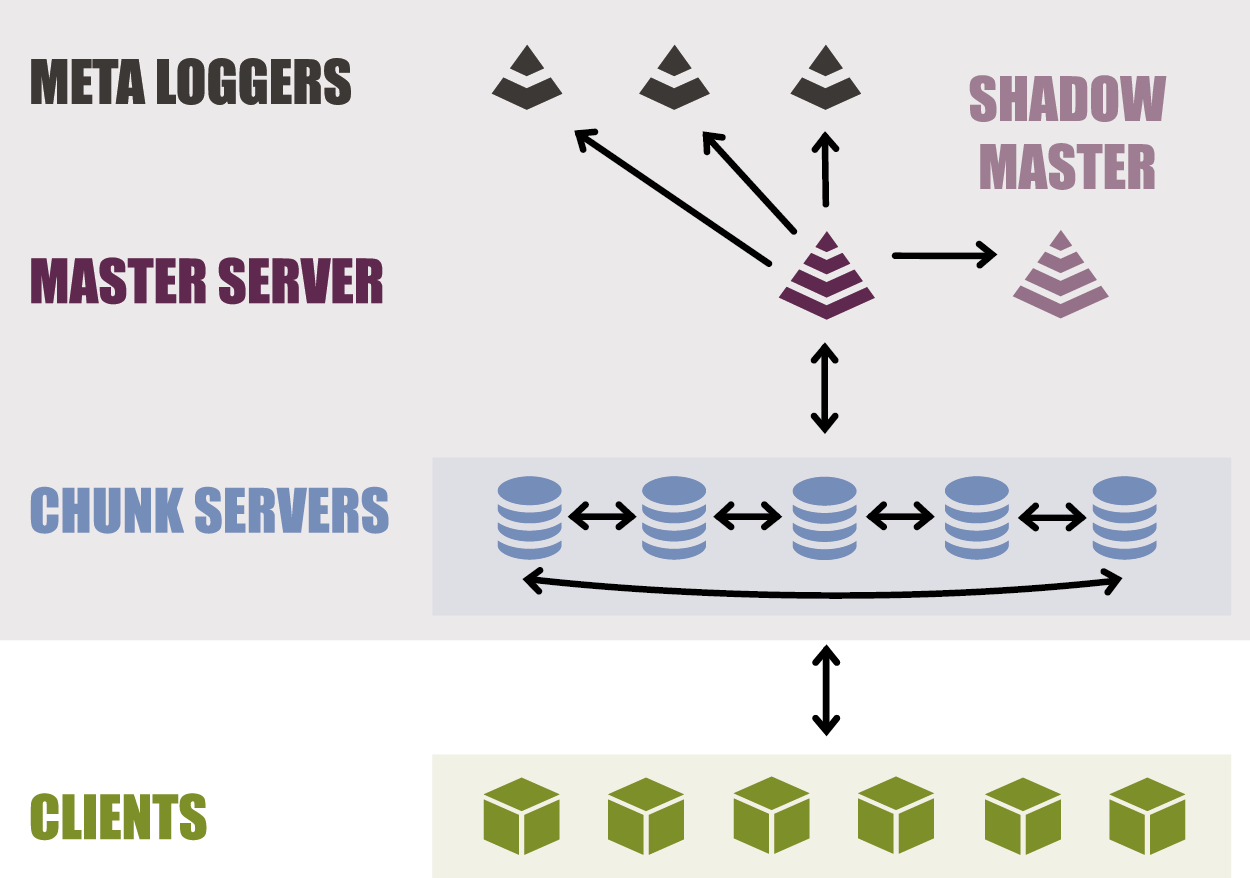 Режим репликации каталога или даже файла может быть определён индивидуально:
• Standard. Режим предназначен для явного определения количества копий фрагментов данных, которые вы хотите сохранить в кластере и на определенной группе узлов. В сочетании с «пользовательскими целями» (goals) это удобно для гео-репликации.
• Xor. Похож на механизм репликации, известный в RAID5.
• Ec — erasure coding. Похож на механизм репликации, известный в RAID6.
Режим репликации каталога или даже файла может быть определён индивидуально:
• Standard. Режим предназначен для явного определения количества копий фрагментов данных, которые вы хотите сохранить в кластере и на определенной группе узлов. В сочетании с «пользовательскими целями» (goals) это удобно для гео-репликации.
• Xor. Похож на механизм репликации, известный в RAID5.
• Ec — erasure coding. Похож на механизм репликации, известный в RAID6.
Отдельный инструмент для обеспечения высокой доступности — LizardFS Uraft, стал доступен OpenSource-сообществу в июле 2018 года. Компонент предназначен для организации высокодоступного кластера файловой системы.
Схема развёртывания кластерной ФС: • устанавливаем мастер-сервера (ноды master01-master03); • устанавливаем компонент высокой доступности uraft (ноды master01-master03); • запускаем uraft, который запускает мастер-сервера на каждой из мастер-нод; • проводятся выборы, где определяется главный мастер-сервер; • ноде, на которой определен главный мастер-сервер; назначается плавающий ip; • остальные мастер-ноды устанавливаются в режим shadow; • устанавливаем и запускаем чанк сервера (ноды node01-node03), которые соединяются с мастер-сервером.
В нашем примере на ВМ master01-master03 развёрнуты компоненты lizardfs-mfsmaster, lizardfs-uraft. Для обеспечения высокой доступности используется технология floating ip. При остановке главного мастер-сервера происходят выборы, выбирается новый ведущий мастер, которому назначается плавающий ip.
На ВМ node01-node03 развёрнуты компоненты lizardfs-chunkserver, lizardfs-metalogger, к каждой ноде подключен диск, который смонтирован в систему. В конфигурации сервера чанков он определён, как доступный для работы внутри кластерной файловой системы.
На ВМ ns установлен компонент lizardfs-client, lizardfs-admin, lizardfs-cgiserv, с помощью которых монтируется, управляется и мониторится кластерная файловая система. Также установлен сервис autofs для автоматического монтирования ФС в /data/lizard.
Пример монтирования ФС:
$ mfsmount -o big_writes,nosuid,nodev,noatime,allow_other -o cacheexpirationtime=500 -o readaheadmaxwindowsize=4096 /mnt
Проверка статусов мастер-серверов:
$ for i in {1..3}; do telnet master0$i 9428; done
Вывод команды:
Trying 192.168.50.21... Connected to master01. Escape character is '^]'. SERVER ID 0 I'M THE BOOSSSS president=1 state=LEADER term=586 voted_for=0 leader_id=0 data_version=1 loyalty_agreement=0 local_time=3550745 blocked_promote=0 votes=[ 1| 1| 1] heart=[ 0.00| 0.00| 0.00] recv =[ 1| 1| 1] ver =[ 1| 1| 1] Connection closed by foreign host. Trying 192.168.50.22... Connected to master02. Escape character is '^]'. SERVER ID 1 president=0 state=FOLLOWER term=586 voted_for=0 leader_id=0 data_version=1 loyalty_agreement=1 local_time=3567651 blocked_promote=0 Connection closed by foreign host. Trying 192.168.50.23... Connected to master03. Escape character is '^]'. SERVER ID 2 president=0 state=FOLLOWER term=586 voted_for=-1 leader_id=0 data_version=1 loyalty_agreement=1 local_time=3551294 blocked_promote=0 Connection closed by foreign host.
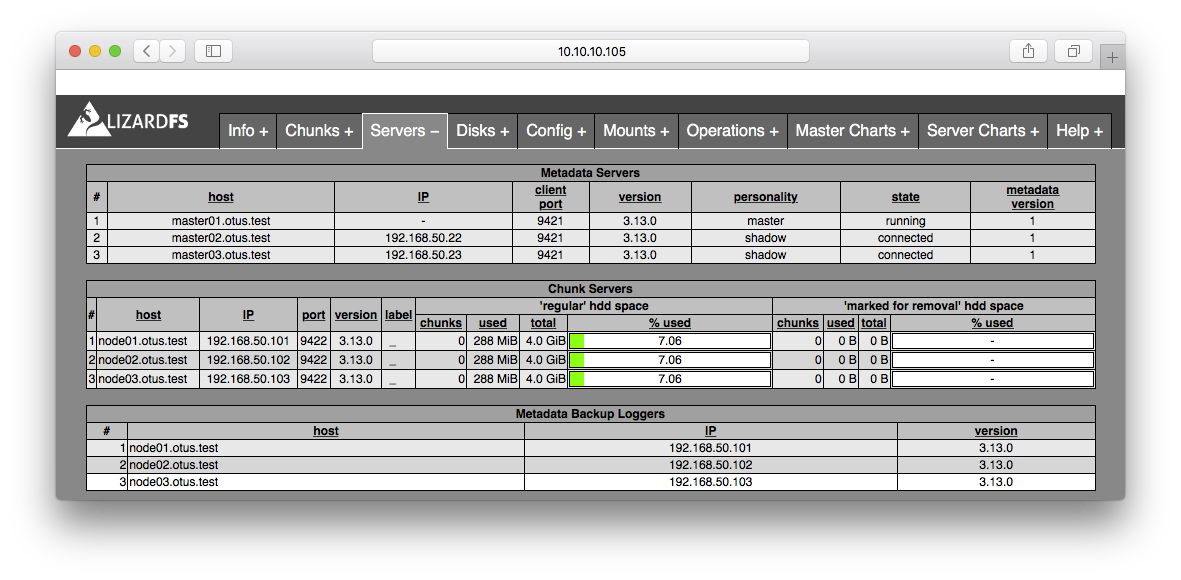
Мониторинг состояния файловой системы:
2.2 Кластер СУБД
Схема кластера:
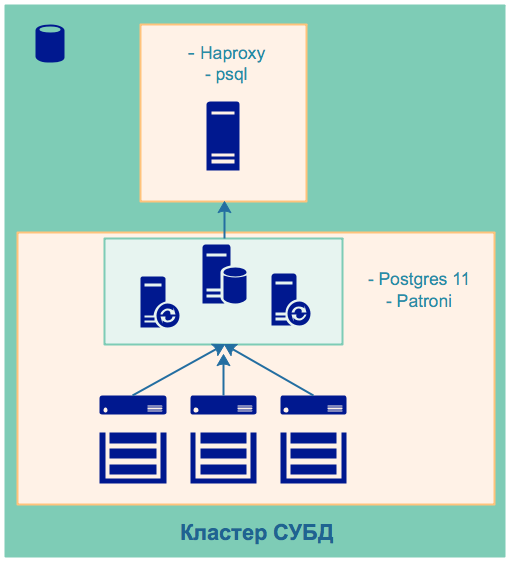 Кластер высокой доступности Postgres. Развёртывание кластера идентично выполненной работе в ДЗ 29.
Разворачиваемыt компоненты:
• PostgreSQL 11;
• Patroni;
• TimescaleDB.
Однако есть дополнения в виде установки двух расширений для использования Postgres в качестве Timeseries DB (об этом ниже).
Кластер высокой доступности Postgres. Развёртывание кластера идентично выполненной работе в ДЗ 29.
Разворачиваемыt компоненты:
• PostgreSQL 11;
• Patroni;
• TimescaleDB.
Однако есть дополнения в виде установки двух расширений для использования Postgres в качестве Timeseries DB (об этом ниже).
Устанавливаются расширения
Подключение к кластеру (логин/пароль: postgres/postgres):
psql -U postgres -h ns.otus.test
2.3 Мониторинг
Схема мониторинга:
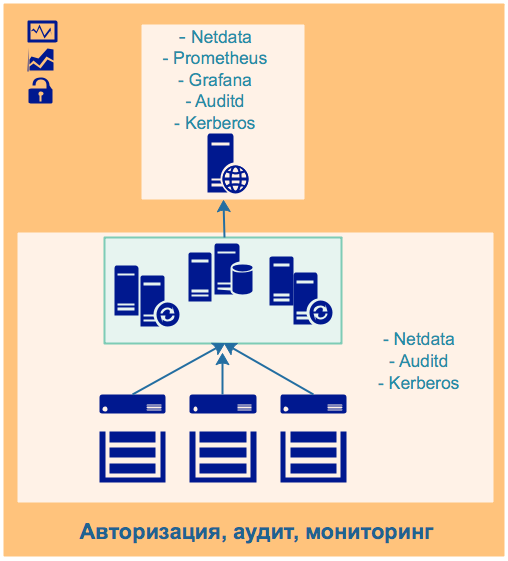 Мониторинг условно разделён на две части: реального времени и пассивный.
Мониторинг условно разделён на две части: реального времени и пассивный.
В мониторинге реального времени будем использовать Netdata. Netdata на всех ВМ отличных от центральной (ns.otus.test) настроим в режиме Stream, чтобы генерируемый поток метрик от каждого хоста пересылался центральному серверу Netdata.
Центральный сервер настроим на приём метрик и их визуализацию. Если в нашем кластере происходят аномалии, то будет возможно наблюдать параметры, критичные для системы в реальном времени. У Netdata достаточно широкая функциональность. Конечно, в курсовом проекте её невозможно охватить в полном объеме.
 Пассивный мониторинг необходим для спокойного анализа причин возникновения проблем, которые привели к негативным последствиям. Для сбора метрик будем использовать возможность Netdata отдавать метрики в формате Prometheus. На ns.otus.test установим и настроим Prometheus, в prometheus.yml определим endpoints для сбора метрик со всех нод стенда. Вместе с Prometheus установим
Пассивный мониторинг необходим для спокойного анализа причин возникновения проблем, которые привели к негативным последствиям. Для сбора метрик будем использовать возможность Netdata отдавать метрики в формате Prometheus. На ns.otus.test установим и настроим Prometheus, в prometheus.yml определим endpoints для сбора метрик со всех нод стенда. Вместе с Prometheus установим
Схема работы коллектора метрик:
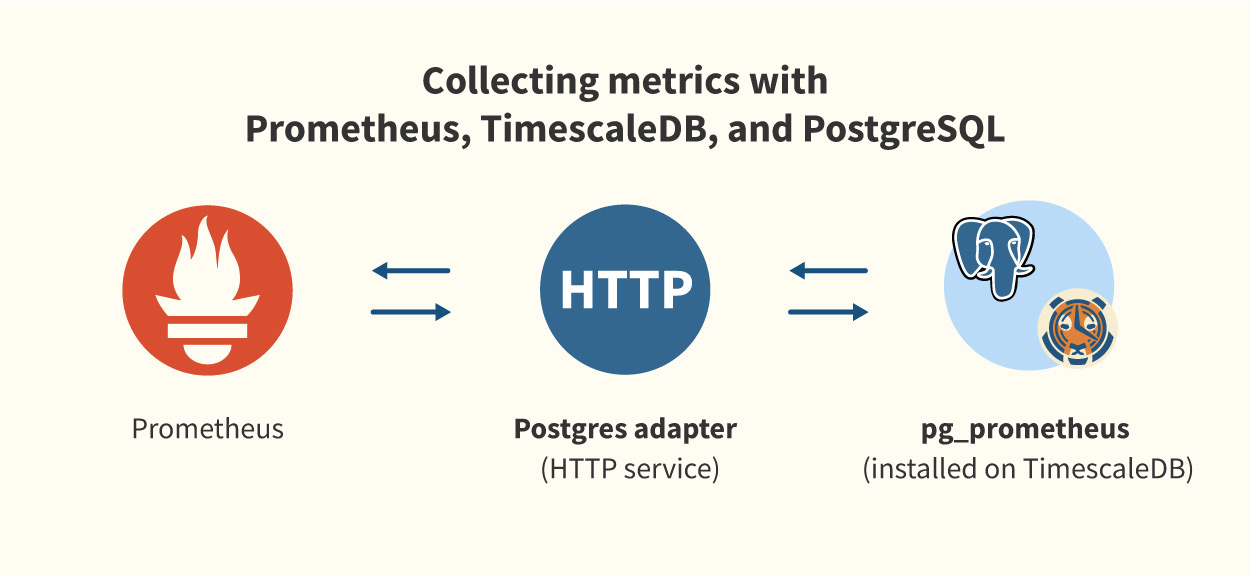 Рrometheus postgresql adapter также можно настроить на работу в режиме высокой доступности. Внутри БД создаётся несколько таблиц (см. структуру таблиц, документация), куда попадают данные мониторинга.
Рrometheus postgresql adapter также можно настроить на работу в режиме высокой доступности. Внутри БД создаётся несколько таблиц (см. структуру таблиц, документация), куда попадают данные мониторинга.
Итого, схема работы пассивного мониторинга: Netdata -> Prometheus -> prometheus-postgresql-adapter -> PostgesSQL+TimescaleDB+pg_prometheus -> Grafana.
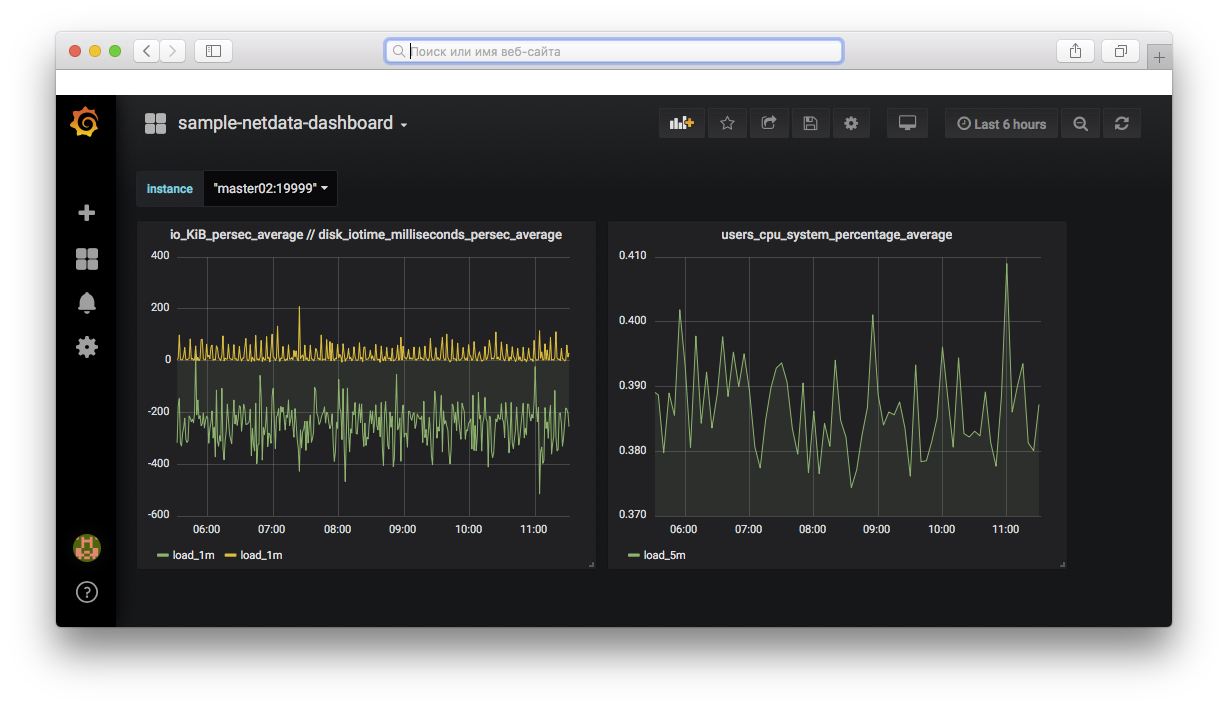
На ns.otus.test установим Grafana, создадим для неё демонстрационный dashboard, где будем отображать метрики, получая их с помощью SQL-запросов из БД.
Пример SQL-запроса:
SELECT time_bucket ('1m', time) AS time, avg(value) as load_1m FROM metrics WHERE time BETWEEN $__timeFrom() AND $__timeTo() AND name = 'netdata_users_cpu_system_percentage_average' AND labels @> '{"instance": "ns:19999"}' GROUP BY 1 ORDER BY 1 ASC;
Выберем все значения метрики
Готовый пример тестового dashboard.
2.4 Аудит
Аудит системных событий настроен по мотивам ДЗ 14. Все ноды пересылают события аудита на ns.otus.test, список правил аудита генерируется с помощью шаблона.
Общий краткий отчёт о событиях в кластере:
$ aureport Summary Report ====================== Skipping line 37 in /etc/audit/auditd.conf: too long Range of time in logs: 01/01/1970 03:00:00.000 - 04/30/2019 16:26:52.204 Selected time for report: 01/01/1970 03:00:00 - 04/30/2019 16:26:52.204 Number of changes in configuration: 0 Number of changes to accounts, groups, or roles: 3 Number of logins: 2 Number of failed logins: 0 Number of authentications: 4 Number of failed authentications: 0 Number of users: 2 Number of terminals: 8 Number of host names: 4 Number of executables: 20 Number of commands: 22 Number of files: 30 Number of AVC's: 0 Number of MAC events: 2 Number of failed syscalls: 18015 Number of anomaly events: 0 Number of responses to anomaly events: 0 Number of crypto events: 25 Number of integrity events: 0 Number of virt events: 0 Number of keys: 0 Number of process IDs: 14866 Number of events: 36719
3. Развёртывание инфраструктуры в облаке
3.1 Доступ к Яндекс.Облаку
На локальной машине необходимо установить Yandex.Cloud CLI и выполнить начальные настройки:
$ curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bash && source "/home/otus-user/.bashrc" $ yc init
В процессе инициализации cli инструмента будут запрошены доступы Яндекс.Облака. Будет создан файл
3.2 Создание AWS S3 совместимого бакета и сервисного аккаунта
В веб-консоли аккаунта Яндекс.Облака создаём объектное хранилище с именем
3.3 Пользователь otus-user, ssh-ключ
На облачную виртуальную машину будем заходить под пользователем
$ ssh-keygen -t rsa -b 4096 -f /home/otus-user/.ssh/otus-user-key -q -N ""
3.4 Использование стартового скрипта
Скрипт
Публичная часть ключа otus-user должна быть включена в метаданные создаваемой ВМ.
Metadata — данные, которые будут применены скриптами cloud-init при старте ВМ в Яндекс.Облаке.
После старта ВМ необходимо зайти в нее по SSH и выполнить дальнейшую настройку:
$ ssh -i ~/.ssh/otus-user-key otus-user@$(yc compute instance get bastion --format json | jq -r '.network_interfaces[].primary_v4_address.one_to_one_nat.address')
3.5 Настройка первой виртуальной машины в облаке
3.5.1 Доступ к Яндекс.Облаку
Установим Yandex Cloud CLI:
$ curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bash && source "/home/otus-user/.bashrc"
С локальной машины из
3.5.2 Настройка и инициализация Terraform, импорт ранее созданных ресурсов
Убедимся, что в бакете отсутствует старый стейт Terraform. Если он есть, то его необходимо удалить для дальнейшей корректной работы при создании новой инфраструктуры.
В директории с кодом инфраструктуры проекта
Для работы Terraform с Яндекс.Облаком необходим провайдер. Провайдер устанавливается автоматически при инициализации в директории с проектом, но для этого необходимы учетные данные из
На этапе создания первой ВМ был сгенерирован новый ssh-ключ для доступа к новосоздаваемым ресурсам
Инициализация Terraform выполняется с параметрами, так как мы создаем бэкенд, лежащий в объектном хранилище. Команда инициализации выглядит так:
$ terraform init -backend-config="access_key=key_id" -backend-config="secret_key=secret" -backend-config="bucket=state"
Необходимо создать сервисного пользователя, назначить ему права на каталог, в котором должна быть развёрнута инфраструктура и находиться уже созданный бакет, а также получить для него ключи доступа.
$ yc iam service-account create --name otus-user $ yc iam access-key create --service-account-name otus-user $ yc resource-manager folder add-access-binding **ИМЯ_КАТАЛОГА** --role editor --subject serviceAccount:**service_account_id**
Вывод команд будет следующим, здесь нам интересны два ключа
access_key: ... **key_id:** xxx...xxx **secret:** xxx....xxxxxx
Из-за особенностей реализации Яндекс.Облака между назначением прав пользователю на каталог и работой с ним должно пройти примерно 60 секунд.
В терминологии Terraform мы создаём backend для хранения Terraform state, который необходим, если предполагается совместное использование этого инструмента.
На этапе создания стартовой ВМ мы создали виртуальную сеть (my-network) и в ней подсеть (my-subnet). Эти же ресурсы мы описали с помощью терраформ. Заметим, что терраформ ничего не знает о том, что эти ресурсы уже созданы. Поэтому перед развертыванием полной инфраструктуры проекта необходимо выполнить импорт описанных и уже созданных ресурсов:
$ terraform import yandex_vpc_network.my-network network_id $ terraform import yandex_vpc_subnet.my-subnet subnet_id
После этого шага всё готово к развёртыванию полной инфраструктуры проекта.
Для выполнения всех вышеперечисленных операций написан скрипт
В скрипте в переменную CATALOG необходимо подставить имя каталога в облаке, в котором будет происходить развёртывание инфраструктуры (в новосозданном аккаунте обычно это каталог
3.5.3 Развёртывание инфраструктуры проекта
Для создания инфраструктуры:
$ terraform plan $ terraform apply
Проверяем:
$ terraform state list
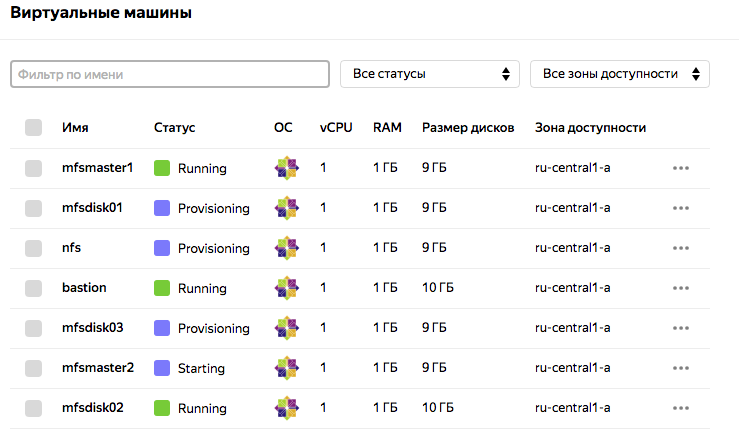 Дальнейшие шаги состоят в запуске ansible playbooks с нужными ролями для установки кластера LizardFS.
Дальнейшие шаги состоят в запуске ansible playbooks с нужными ролями для установки кластера LizardFS.
Вот и всё. Подробности реализации и исходный код проекта смотрите в репозитории автора. Там же вы найдёте массу полезных ссылок.