

История появления DataOps
Поговорим о том, когда появился термин DataOps, а также в каком году он прочно вошел в лексикон специалистов по данным.
Термин DataOps (от Data Operations) впервые прозвучал в 2015 г., и произошло это в блоге Энди Палмера. Энди Палмер, наряду с легендарным Майклом Стоунбрейкером, является сооснователем компании Tamr.


Следующее упоминание о DataOps произошло уже в марте 2017 г. на конференции "Strata+Hadoop World". И прошло оно не просто так, ведь термин был зафиксирован в книге "Creating a Data-Driven Enterprise with DataOps", причем написана эта книга была не кем-нибудь, а специалистами, 4 года работавшими над проектом Apache Hive в команде Facebook Data Service Team.

Тут уместно будет вспомнить движение "SQL для Hadoop", которое было начато Hive и нацелено на решение проблемы по предоставлению аналитикам удобных средств для работы с большими данными. Ведь, несмотря на наличие множества инструментов обработки Big Data, Hadoop до сих пор является трудным даже для специалистов по данным, не говоря о бизнесе, который вовсе не хочет тратить время на освоение, в результате чего в алгоритме «потоки гетерогенных данных — специалисты по данным — конечные юзеры» формируется узкое место -- «бутылочное горлышко». Причем для устранения этого узкого места одного лишь средства доступа к данным явно недостаточно — надо ведь еще и обеспечить сбор/подготовку данных, надо управлять эксплуатацией данных и вовремя реагировать на рост/падение объемов и нагрузок. А еще крайне важно снабжать аналитиков именно «свежими» данными, ну а разработчиков — «живыми задачами», которые способны привести к значимым для бизнеса результатам в сжатые сроки.
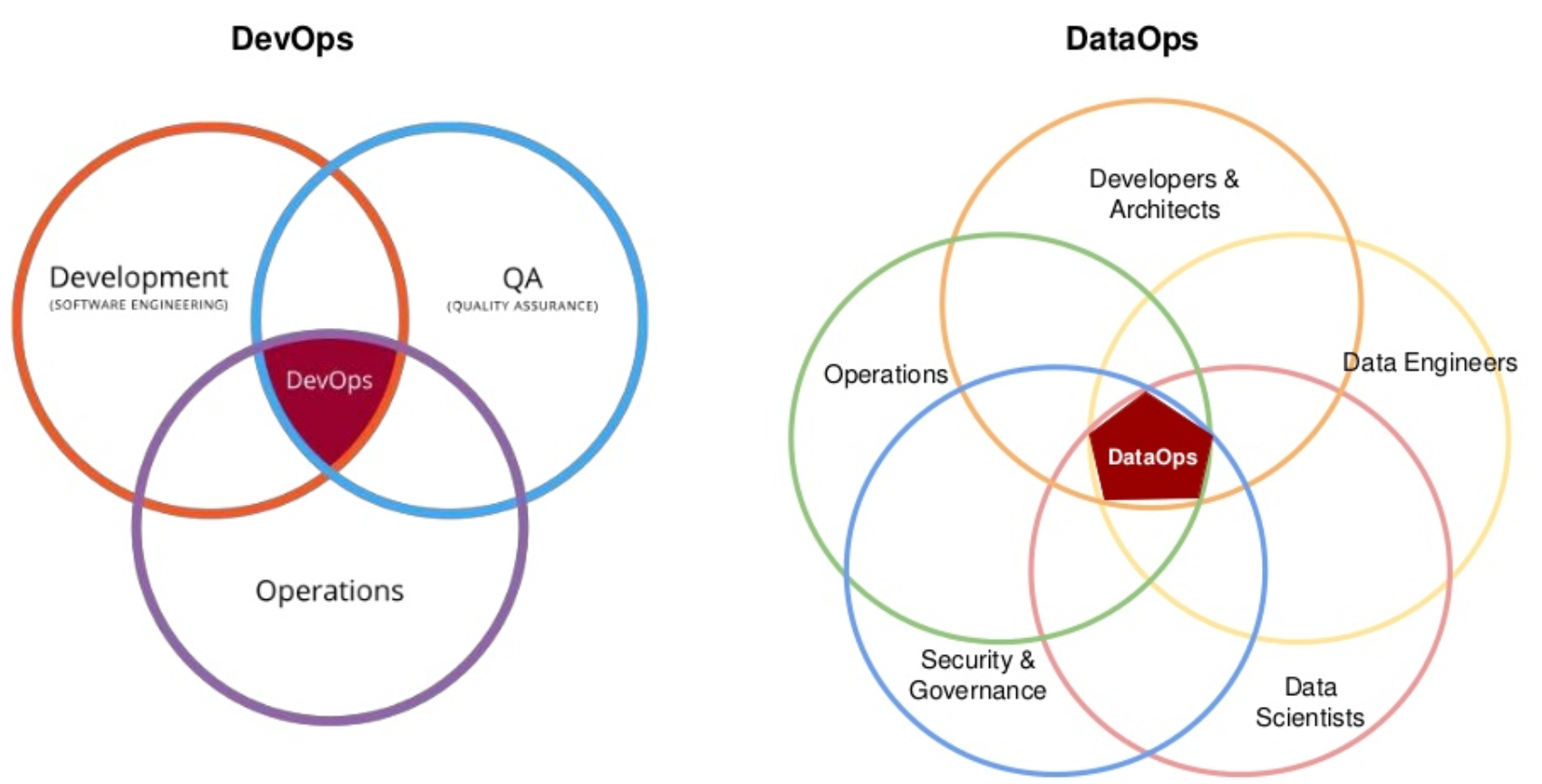
Как же достичь такой «нирваны» при общении с данными? И вот здесь-то на сцену и вышел DataOps. Собственно говоря, в отличие от множества модных терминов, расшифровывать слово DataOps, по сути, и не нужно, ведь и так понятно, что разговор идет об интеграции таких ветвей, как аналитика, разработка и эксплуатация в условиях BigData, то есть перед нами, если говорить простыми словами, не что иное, как DevOps для больших данных (хотя, конечно же, нюансы в интерпретации деталей вполне себе допустимы). Не секрет, что компаниям, бизнес которых выстроен на Big Data, приходится чуть ли не каждый день вводить в эксплуатацию новые сервисы, созданные на основе данных. Такие практики естественны и применялись задолго до DataOps.
Но именно с появлением последней, состояние «нирваны» при общении с данными почувствовали такие гиганты, как LinkedIn, eBay, Twitter, Uber и Netflix. Именно эти компании в числе первых увидели на примере Facebook, что данные в современном мире — это власть, особенно если вы умеете работать с этими данными, опираясь не только на технологии, но и путем изменения всей культуры, как это, к слову, и предусматривает концепция DataOps.
В связи со всем вышесказанным, становится даже странным и удивительным, что термин появился так поздно. По сути, он и вошел-то в лексикон инженеров по данным всего лишь конце 2017 г. и только потом был узаконен аналитиками Gartner в IT-глоссарии, где это понятие характеризуется следующим образом:

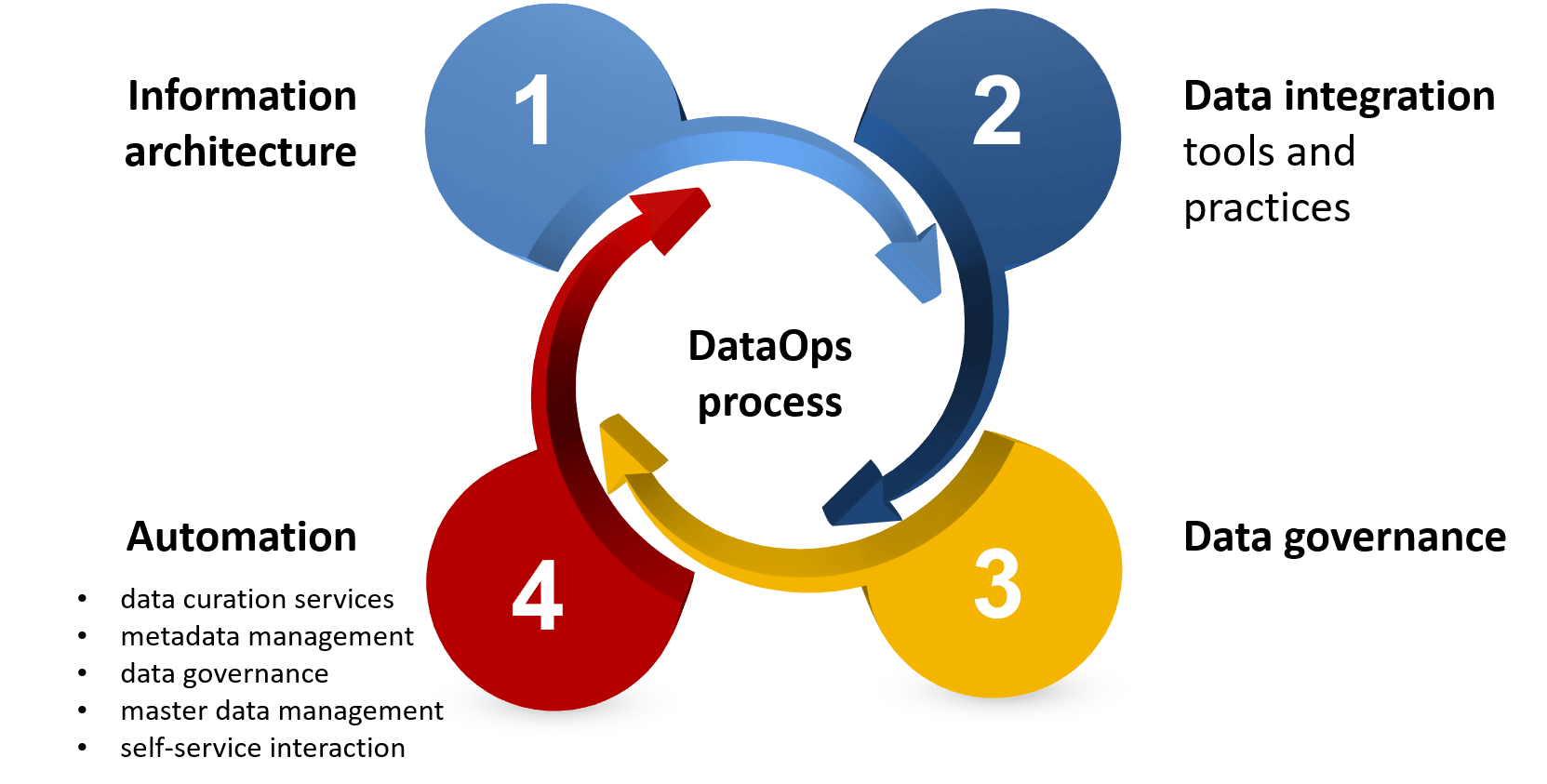
Ну и, напоследок, вспомним главные принципы DataOps:
- следует думать не о серверах, а о сервисах;
- инфраструктура работы с данными представляет собой код;
- автоматизируйте все!
- не забывайте про DevOps: компания, управляемая данными, представляет собой DataOps + DevOps, которые реализованы с учетом принципов Agile.
По материалам https://www.osp.ru/.