

Масштабирование реляционных СУБД и NoSQL-подход
Большинство современных баз данных, с которыми привыкли работать разработчики, поддерживают реляционную алгебру. Как известно, в таком случае данные хранятся в таблицах, поэтому периодически возникает необходимость в получении этих данных с помощью JOIN. Для примера рассмотрим простой запрос к БД.
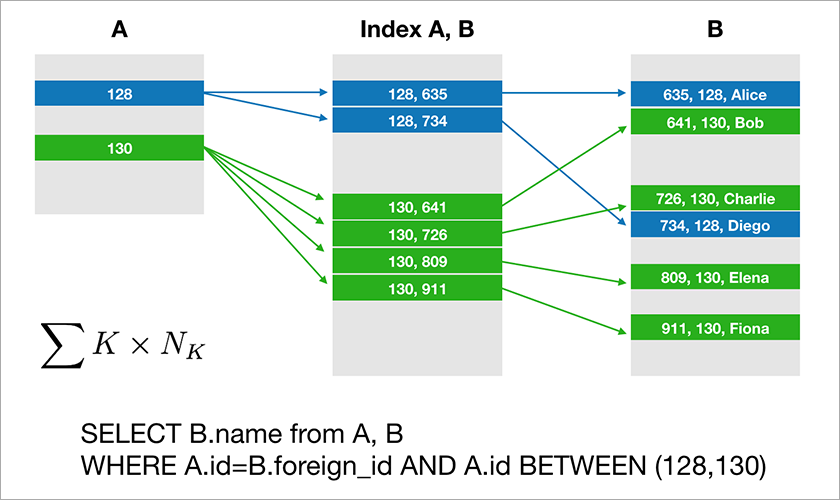
Предполагается, что A.id представляет собой Primary Key с кластерным индексом. В этом случае оптимизатор построит план, который, вероятнее всего, сначала выполнит выборку необходимых записей из таблицы A, а далее возьмет из подходящего индекса (A,B) ссылки на записи в таблице B. При этом следует отметить, что время выполнения данного запроса растет логарифмически в зависимости от числа записей в таблицах.
Теперь давайте представим, что наши данные распределены по 4-м серверам кластера, причем нам необходимо выполнить тот же запрос:
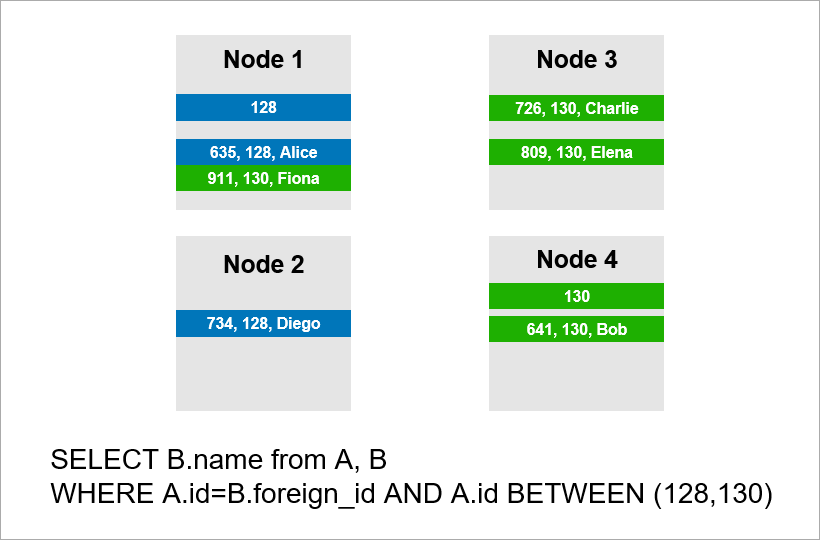
Когда система управления БД не желает просматривать все записи всего кластера, она, скорее всего, попытается найти записи с A.id равным 128, 129 либо 130, а также найти для них соответствующие подходящие записи из таблицы B. Однако если A.id не является ключом шардирования, система управления БД заранее не знает, да и не может знать, на каком конкретно сервере находятся данные таблицы А. Таким образом, приходится все равно обращаться ко всем серверам, дабы определить, есть ли там записи A.id, подходящие под наше условие. Далее каждый сервер может сделать внутри себя JOIN, однако этого мало. Обратите внимание, что запись на ноде 2 нужна нам в выборке, однако там отсутствует запись c A.id=128. А если ноды 1 и 2 станут делать JOIN независимо, результат запроса будет неполным, то есть часть данных мы не получим.
Именно поэтому, чтобы выполнить данный запрос, каждому серверу необходимо обратиться ко всем остальным. Причем время выполнения будет расти квадратично в зависимости от числа серверов. Повезет, если будет возможность шардировать все таблицы по одному и тому же ключу — в таком случае все серверы обходить не надо будет. Но на практике это маловероятно — всегда будут запросы, когда требуется выборка не по ключу шардирования.
Следовательно, операции JOIN масштабируются принципиально плохо, и именно в этом заключается фундаментальная проблема реляционного подхода.
Подход NoSQL
Различные трудности с масштабированием классических СУБД стали причиной появления NoSQL-баз данных, где нет операции JOIN. Как утверждалось — нет джоинов — нет и проблем. Однако при этом отсутствуют и ACID-свойства, а вот об этом маркетологи, к сожалению, умолчали.
В итоге сразу же нашлись спецы, которые проверили на прочность различные распределенные системы с последующей публичной выкладкой результатов. Так вот, оказалось, что существуют сценарии, при которых: — кластер Redis теряет 45 % сохраненных данных; — MongoDB — 9 % записей; — кластер RabbitMQ — до 35 % сообщений; — Cassandra — до 5 % записей.
При этом мы говорим о потере после того, как кластер сообщит клиенту об успешном сохранении. Что тут скажешь — как правило, мы ожидаем от выбранной технологии большей надежности.
Как тут не вспомнить базу данных Spanner — детище Google. Эта БД работает по всем миру, гарантируя ACID-свойства, Serializability и даже больше. В дата-центрах установлены атомные часы, обеспечивающие точное время, что, в свою очередь, дает возможность выстраивать глобальный порядок транзакций, причем без необходимости пересылать между континентами сетевые пакеты. Вообще, основная идея Spanner проста — пусть лучше программисты разбираются с проблемами производительности, возникающими при большом числе транзакций, чем создают костыли вокруг отсутствия этих самых транзакций. Но, как это часто бывает, за интересное решение нужно платить, поэтому Spanner — закрытая технология, которая вам не подойдет, если вы не желаете зависеть от одного вендора.
Раз мы вспомнили о Spanner, нельзя не упомянуть и CockroachDB, которую разработали выходцы из Google, попытавшись сделать open source-аналог Spanner. Название «cockroach» здесь не случайно («таракан», англ.) и должно было символизировать живучесть БД. Однако в 2018 году уже высказывались мнения о неготовности продукта к production, а все из-за того, что кластер терял данные. И даже при проверке в 2019 году более новых версий случалось, что, хоть данные и не терялись, но некоторые простейшие запросы выполнялись слишком долго. Однако создатели CockroachDB продолжают развивать свой проект и, возможно, вскоре сумеют устранить большинство недостатков.
Выводы
Что можно сказать точно? Во-первых, на сегодняшний день мы имеем и до сих пор используем реляционные БД, но, к сожалению, они хорошо масштабируются лишь вертикально, а это, честно говоря, дорого. Во-вторых, существуют NoSQL-решения, но, увы, без транзакций и без гарантий ACID (если хочешь ACID — пиши костыли). Как то так.
Статья подготовлена по материалам блога компании Pyrus.