

Транзакции в highload-проектах

Все мы прекрасно знаем 4 главных требования к транзакциям: атомарность, изолированность, согласованность и долговечность (ACID — Atomicity, Consistency, Isolation, Durability). Давайте поговорим о транзакциях в контексте высоконагруженных проектов.
Когда мы рассуждаем о распределенных БД, мы предполагаем, что данные необходимо масштабировать. Чтение масштабируется прекрасно, поэтому тысячи транзакций могут параллельно читать данные без каких-либо проблем. Но если вместе с чтением другие транзакции осуществляют запись данных, то не исключены негативные эффекты. Например, достаточно просто получить ситуацию, когда одна транзакция будет читать различные значения тех же самых записей. Дабы не быть голословными, рассмотрим примеры.
Dirty reads
В этой транзакции мы дважды отправляем тот же самый запрос: сделать выборку всех юзеров с ID равным единице. Когда вторая транзакция изменит эту строчку, сделав потом rollback, наша база данных, с одной стороны, каких-либо изменений не увидит, а вот с другой — первая транзакция прочтет различные значения возраста для Joe.

Non-repeatable reads
Второй случай — транзакция записи завершилась с успехом, а транзакция чтения во время выполнения того же самого запроса получила различные данные.

И если в первом случае клиент прочел данные, которые в БД отсутствовали, то во втором — клиент оба раза прочел данные из БД, которые оказались различными, хотя чтение осуществлялось в рамках одной транзакции.
Phantom reads
Речь идет о ситуации, когда мы в контексте одной транзакции повторно читаем какой-либо диапазон, получая различный набор строк. И где-то посередине влезает другая транзакция, вставляя либо удаляя записи.

Для исключения вышеописанных негативных эффектов СУБД реализуют: — механизмы блокировок (транзакция ограничивает доступ к данным иным транзакциям, с которыми она сейчас работает); — мультиверсионный контроль версий или MVCC (транзакция никогда не меняет ранее записанные данные, всегда создавая новую версию).
Существующий сегодня стандарт ANSI/ISO SQL определяет четыре уровня изоляции транзакций, влияющих на степень их взаимной блокировки. И чем выше уровень изоляции, тем меньше существует негативных эффектов. Плата за это — увеличение вероятности deadlocks и замедление работы приложения (дело в том, что транзакции чаще находятся в ожидании снятия блокировки с необходимых им данных).
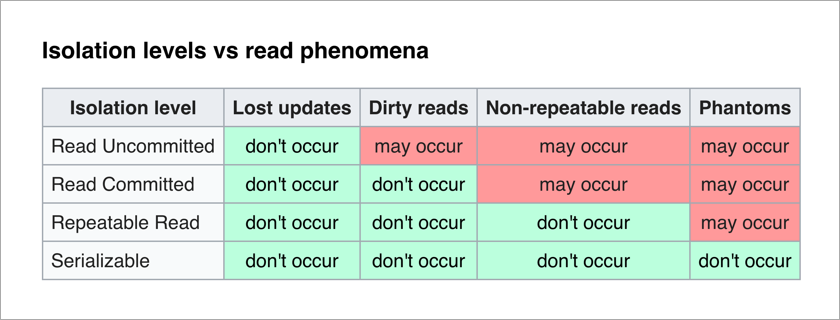
Самый приятный уровень для прикладного программиста — Serializable (отсутствуют негативные эффекты, а вся сложность обеспечения целостности данных перекладывается на СУБД). Но тут стоит подумать про наивную реализацию уровня Serializable — при осуществлении каждой транзакции мы просто выполняем блокировку всех остальных. Теоретически, каждая транзакция записи может выполняться за 50 мкс (речь идет о времени одной операции записи у SSD-дисков). Мы же хотим сохранять данные, допустим, на 3 машины. И если они располагаются в одном дата-центре, на запись уйдет 1-3 мс. Если же они находятся в нескольких разных городах, запись может занять и 10-12 мс. Таким образом, в случае наивной реализации уровня Serializable последовательной записью, мы получаем возможность выполнять не более 100 транзакций в сек. И это при том, что отдельный SSD-диск позволяет осуществлять около 20 тыс. операций записи в секунду.
Вывод из этого прост: записи лучше выполнять параллельно, а для их масштабирования необходим хороший механизм разрешения конфликтов.
Статья подготовлена по материалам блога компании Pyrus.