

Основные принципы Hadoop
Мы уже вкратце рассказывали об архитектуре Hadoop, и о том, что основными компонентами этой экосистемы являются HDFS и MapReduce. В этой статье поговорим о принципах работы Hadoop.
Принцип № 1: горизонтальное масштабирование
Давайте представим, что в кластере возникли неполадки, и нам не хватает ресурсов имеющихся серверов. Существуют 2 модели поведения: 1. Выполнить апгрейд уже имеющегося железа либо заменить его — это всем известное вертикальное масштабирование. 2. Дополнить имеющийся комплект серверов более новыми устройствами — это, соответственно, горизонтальное масштабирование.
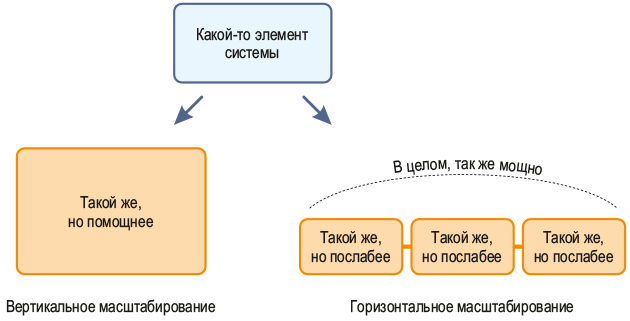
Экосистема Hadoop заточена под вариант номер 2. Почему? Ответ прост — в случае горизонтального масштабирования ресурсы кластера почти не ограничены, а расширять его можно, по сути, бесконечно.
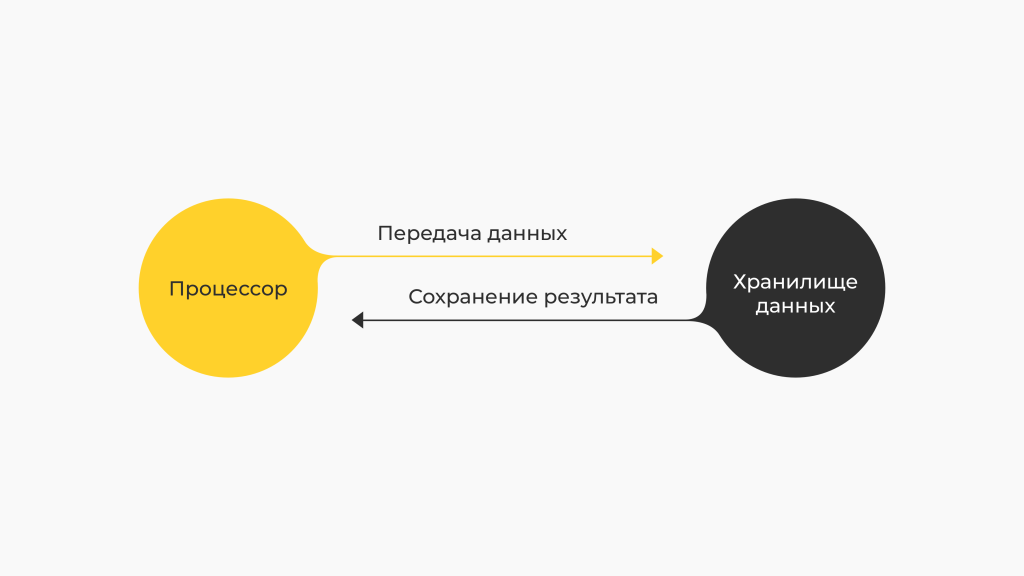
Принцип № 2: код отправляется к данным, а не наоборот
Существует подход, когда для хранения и обработки данных выделяются сервера. Во время работы с большими объёмами данных приходится их передавать между этими серверами. Решение является непростым, энергозатратным, да и, чего уж там скрывать, дорогим.
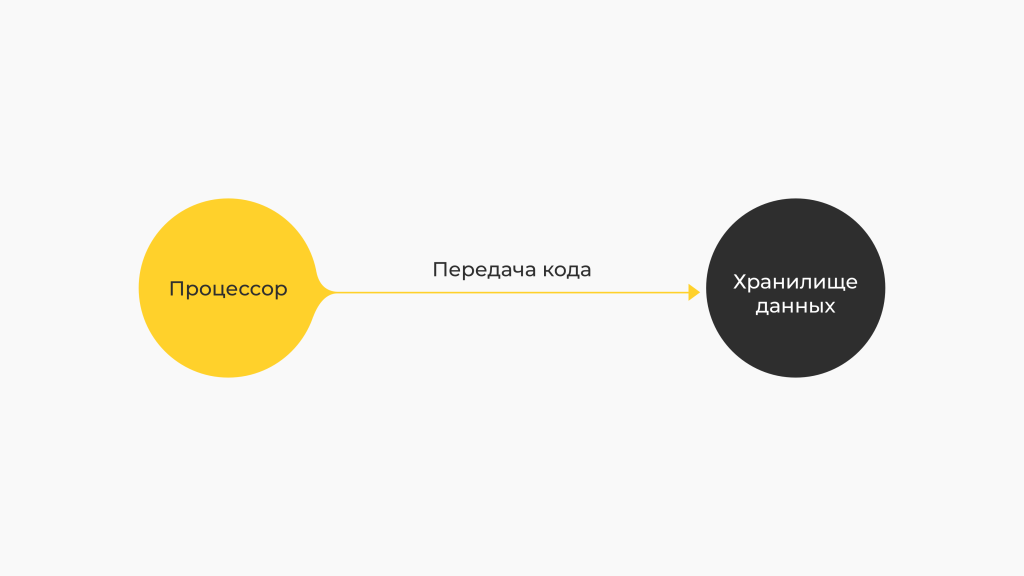
В случае с Hadoop все происходит более эффективно: если надо выполнить обработку данных, мы не осуществляем их физический перенос на обрабатывающий сервер, а лишь копируем нужную часть кода, перенося этот код к данным. Итог — система становится «легче» и функционирует быстрее.
Принцип № 3: отказоустойчивость
Экосистема Hadoop учитывает вероятность отказа железа и нивелирует эту вероятность следующими механизмами: 1. Репликацией данных. Речь идёт о восстановлении утерянной части данных. 2. Перезапуском тасков. Это механизм, запоминающий таски, а также регулярно проверяющий и обновляющий их.
Таким образом, исходя из вышеописанных трёх принципов, можно сформулировать одно из основных достоинств экосистемы Hadoop: кластер машин может состоять из самых обыкновенных серверов, к которым не предъявляются чрезмерные запросы в плане отказоустойчивости.
Принцип № 4: инкапсуляция сложности реализации
Если в двух словах, то это значит, что пользователь лишь продумывает, как именно он желает обрабатывать данные, больше фокусируясь при этом на бизнес-логике процесса, а не на программной части. Профит такого подхода очевиден.

Кто изучает Hadoop?
В основном, знание экосистемы пригодится специалистам, работающим с BigData. Это и аналитики, и разработчики. Если говорить о конкретных сферах, то это, как правило, банки, IT-компании и крупные сервисы с большой клиентской базой.