

Project Reactor — реактивный подход в высоконагруженном приложении
Как известно, микросервисная архитектура основывается на выделении небольших независимых служб, при этом каждая из них реализует отдельную бизнес-функцию. И если в монолитной архитектуре всё связано (при отказе одной функции могут отказать и остальные), то в случае с микросервисами обеспечивается повышенная гибкость и устойчивость системы.
Если же мы говорим о High Load-приложениях, мы говорим о крупных IT-решениях, а они могут иметь в своей архитектуре десятки микросервисов, причём с каждым из них может работать независимая команда.
Реальный пример из практики
Рассмотрим реальный кейс от SimbirSoft на примере создания сервиса для начисления кэшбэка. Одна страховая компания попросила модернизировать своё онлайн-приложение, построенное на микросервисах. Была поставлена задача реализовать кэшбэк (начисление бонусных баллов при покупке страхового полиса).
На словах всё выглядело несложно: 1. За каждый оплаченный либо продлённый полис происходит начисление клиенту определённого кэшбэка через бухгалтерский сервис. Клиент имеет доступ к информации об этом начислении. 2. Когда суммарный кэшбэк достигает определённого значения, происходит автоматический перевод средств пользователю посредством бухгалтерского сервиса. Клиент имеет доступ к истории выплат.
В основном проекте применялась очередь сообщений Kafka в виде средства обмена данными между микросервисами, а также в виде единственного реплицированного хранилища данных.
Когда нужна реализация каких-либо функций на микросервисной архитектуре, всегда следует думать о возможности горизонтального масштабирования. Код в этом случае должен функционировать не только в многопоточной среде, но и если запустится несколько контейнеров с микросервисом.
Также добавим, что клиентов у этого приложения неограниченное множество, причём многие из них являются мобильными, а значит, довольно медленными.
Blocking vs Non-blocking
В случае применения стандартной сервлетной архитектуры каждый запрос выполняется в отдельном потоке. В целом этот подход неплох, особенно, если мы вспомним возможности современных серверов, способных обрабатывать сотни соединений одновременно.
Но тут есть пара нюансов: 1) не всегда присутствует возможность купить такой сервер; 2) всегда что-то может пойти не так (и это главный нюанс). Допустим, появятся задержки бэка либо вы столкнётесь с ситуацией «retry storm». В результате число активных потоков и соединений увеличится, и кластерные ноды могут попасть в спираль за счёт того, что резервные копии потоков увеличат нагрузку на сервер и перегрузят кластер. Да, мы можем встроить механизмы регулирования, дабы компенсировать риски и стабилизировать ситуацию, но это не решит всех проблем. Плюс, восстановление бывает долгим и рискованным.
А вот асинхронные системы работают несколько иначе. Как правило, в них одному ядру соответствует один поток, причём сам цикл запроса-ответа обрабатывается посредством событий и коллбэков. Выходит, что в тех местах, где мы «платили» за запрос целым потоком, просто добавится очередное сообщение.
Очевидно, что и восстановление после разных неприятностей будет даваться легче, ведь обработать доп. сообщения в очереди проще, чем складировать множество потоков. А так как все запросы асинхронны, у нас упрощается и масштабируемость системы. И в случае, если видно большое число сообщений в очереди, можно просто временно создать дополнительных потребителей.
То есть устойчивость такой системы достигается благодаря самой природе асинхронного подхода. Какие тут нюансы: 1) мы можем попробовать обрабатывать исключение локально; 2) в асинхронных системах не происходит блокировка компонентов обработкой исключений, т. е. ошибка в одном компоненте на остальные не влияет. Мало того, когда один компонент с обработкой сообщения не справляется, это сообщение можно обработать другим компонентом, который записан на тот же адрес.
Но, как известно, у всего есть своя цена, поэтому у асинхронного подхода существует и минусы. Например, усложняется разработка и отладка. Да и не всегда переход на асинхронный код даёт улучшение в производительности.
Но вернёмся к нашему приложению. У него множество юзеров, осуществляющих доступ с мобильных девайсов. Это и стало причиной применить один из асинхронных фреймворков.
Заказчик хотел, чтобы проект был реализован на Java (это повышало удобство дальнейшей поддержки). Так как вариантов высокоуровневых абстракций было не очень-то много, был выбран Project Reactor.
Работаем с Project Reactor
Reactor — реализация спецификации Reactive Streams. В «реакторе» существуют две основные структуры данных — Mono и Flux. И обе они представляют собой реализации интерфейса Publisher, являясь асинхронным потоком элементов или единичным асинхронным элементом соответственно.
Внешне стримы в Reactor похожи на стандартные Java-стримы по коллекциям (java.util.stream.Stream). Да, в языке программирования Java, Stream — это не только механизм работы с коллекциями. Но здесь надо вспомнить и то, что Flux — это тоже не коллекция.
В «Джаве» перед началом стрима по коллекции есть все её элементы, то есть мы знаем её размер и так далее. А вот Flux лучше рассматривать в качествен некой отложенной коллекции, число элементов в которой неизвестно в момент выполнения стрима.
Пусть мы и можем сконвертировать Flux в коллекцию стандартными средствами, это будет просто блокирующая операция, которая не даст гарантии выполнения последующих элементов. Обычно (кроме тестов) так делать нельзя, ведь мы желаем минимизировать число блокирующих операций и уменьшить время простоя железа, особенно, когда мы говорим про операции ввода-вывода.
Схема работы
В самом начале работы с проектом надо, основываясь на техническом задании, определить функциональные блоки, которые потом станут отдельными микросервисами.
Можно сразу отметить, что приложение имеет три главных процесса: 1. Получение информации извне (пользователи, оплата, полисы) с последующим начислением кэшбэка на основе полученной информации. Назовём этот сервис «Калькулятор». 2. Общение с пользователем. Наше приложение обращается к хранилищу, дабы найти нужный кэшбэк по конкретному пользователю. Это 2-й сервис — «Хранилище». 3. Общение с бухгалтерским сервисом. Т. к. начисление кэшбэка и выплаты будут проводится через бухгалтерский сервис, назовём 3-й сервис «Бухгалтер».
Таким образом, у нас получилась вполне себе простая схема:
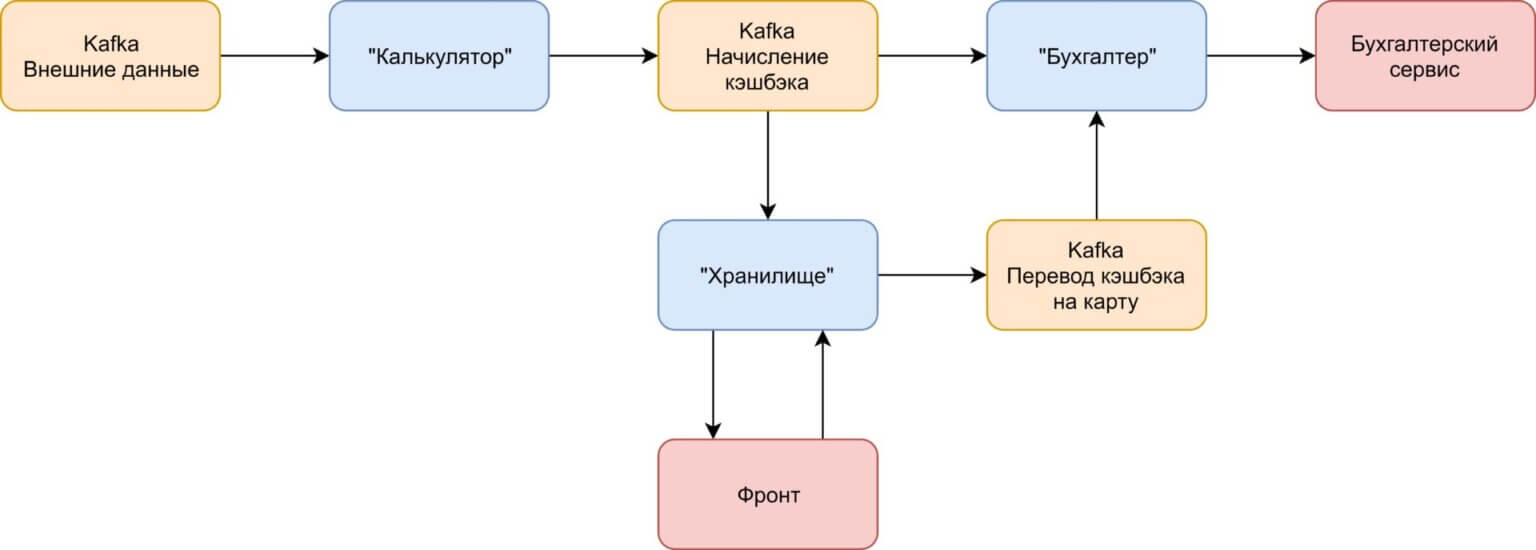
Сервер «Калькулятор» вычисляет кэшбэк по каждому пользователю/полису/факту оплаты, отправляя сообщение в отдельную очередь. Сервисы «Бухгалтер» и «Хранилище» читают сообщения из данной очереди. «Хранилище» выполняет сохранение кэшбэка и показывает его юзеру, а при достижения минимального порога выплаты активирует зачисление средств пользователю на его карту. «Бухгалтер» осуществляет вызов внешнего бухгалтерского сервиса в целях физического начисления бонусов.
Организуем локальное хранилище
Большое значение придаётся очерёдности вышеописанных процессов. Например, очевидно, что «Калькулятор» функционирует на основании сообщений, поступающих от внешних сервисов. Но бывают ситуации, когда «Калькулятор» не может принять решение об отправке на основании одного входящего сообщения. Допустим, ему надо проверить два внешних топика: оплату и полисы. В данном случае требуется внутреннее хранилище, которое нужно формировать на основе всех внешних сообщений.
Сравнив стандартные SQL-варианты и подход NoSQL, было отдано предпочтение MongoDB, т. к.: 1. Для mongoDB существует готовый фреймворк для работы с Project Reactor — reactive mongo. 2. У нас мало таблиц, как и связей между таблицами. 3. База проста в применении, не надо следить за соответствием моделей таблицам.
Также надо разделить процессы по формированию локального хранилища и принятию решений об отправке. Каким образом это реализовать, если решение об отправке принимается на основании тех же самых сообщений, по которым строится внутреннее хранилище? Один из вариантов — разделение по времени и запуск начисления по внешнему планировщику. Пожалуй, это самый простой и понятный способ реализации.
Репроцессинг
Дабы упростить архитектуру приложения и уменьшить риски, желательно применять микросервисы stateless, без локальных хранилищ. В результате не имеет значения, какая информация у нас на входе, т. к. она просто проходит по цепочке стрима.
Если это по тем либо иным причинам невозможно, стоит попробовать изолировать логику работы с состоянием в отдельном слое. Говоря иначе, надо поставить дополнительный уровень абстракции над логикой с состоянием. В таком случае в приложении присутствует сегмент statefull, однако он изолирован, а другие его части с состоянием не связаны.
Но на деле с этим, бывает, возникают сложности. Допустим, не позволяет архитектура, отсутствует время либо понимание, каким образом это реализовать в конкретном проекте. Могут и не позволять требования репроцессинга. Во время включения и выключения сервиса (и сбросе оффсетов) такой сервис станет повторно выполнять уже выполненные действия. В нашей ситуации «Калькулятор» станет повторно отбрасывать сообщения о начислениях кэшбэка. Мало того, даже локальное хранилище не будет гарантировать правильную работу, ведь оно не реплицировано и может быть целиком удалено в любой момент и вместе с сервисом.
Для решения вопроса можно использовать специальную очередь отправленных сообщений. Именно эту очередь мы будем читать, записывая в локальное хранилище на старте сервиса, совместно с остальными внешними сообщениями.
Другие особенности
Очередная особенность Project Reactor связана с работой с фронтэндом. Её суть в том, что во многих случаях просто получить какое-нибудь значение нам недостаточно. Гораздо чаще надо получить значение, а потом отслеживать его изменения. Данный вопрос решается просто посредством reactive mongo. У хранилища из библиотеки reactive mongo имеются методы отслеживания и получения, которые вернут как требуемое значение, так и его последующие изменения, если они будут.
Также обратите внимание на сервис «Бухгалтер». Допустим, данный сервис работает с внешним API по REST либо, как у нас, по SOAP. Здесь тоже действуют требования по репроцессингу, плюс требуется отдельная очередь истории. Но возможны и доп. требования по устойчивости системы в целом.
К примеру, что произойдёт, когда внешний API ответит 500-й ошибкой? В нашем случае мы сможем использовать стандартный механизм «Реактора»
Тестирование
Разумеется, проект не заканчивается созданием рабочих модулей. Требуется проверить его работоспособность, допустим, посредством юнит-тестов. Для рабочих модулей на Project Reactor в юнит-тестах применяют StepVerifier — внутренний компонент, позволяющий верно тестировать функциональность. К тому же, StepVerifier имеет легкодоступную и исчерпывающую документацию.
Теперь скажем пару слов про интеграционные тесты. Во многих случаях они предполагают запуск микросервисов в контейнерах, поэтому при проектировании нужно подумать о полноценном логировании. Если это не выполнено, существует риск долгого поиска причин падения каждый раз.
После выполнения модульных и интеграционных тестов стало ясно, что приложение к асинхронной работе готово. А также покрыто тестами и готово и к горизонтальному масштабированию, плюс устойчиво к неожиданным отключениям. В целом разработка заняла порядка 3-х недель с отладкой и ревью заказчика.
Итог
Если вы имеете дело с высоконагруженными приложениями с большим числом внешних пользователей, рассмотрите вариант асинхронной работы с использованием реактивного подхода.
Хоть реактивная реализация и не всегда повышает быстродействие системы, зато она существенно повышает её устойчивость и масштабируемость.
Применение Reactor даёт возможность относительно просто реализовать асинхронную работу, сделав решение наглядным и понятным для последующей поддержки. Также работа с Project Reactor потребует особенного внимания при написании кода, в частности, при выстраивании стримов Mono и Flux. Вдобавок к этому, нужно постоянно сверяться с документацией и выполнять промежуточные тесты.
В этой статье были рассмотрены: — асинхронная работа; — репроцессинг; — организация хранилищ; — вызов внешних сервисов; — тестирование и прочие особенности, о которых нельзя забывать, если вы реализуете проект с микросервисами и Reactor.
Возможно, этот опыт команды SimbirSoft, пригодится и вам. Успехов в построении высоконагруженных приложений!