
При изучении информатики и IT пользователю предстоит разобраться с огромным количеством разнообразных понятий и терминов, включая кодировки и языковые коды.
Именно на этих компонентах заострим внимание. Соответствующие комбинации позволяют работать с разного рода информацией, а также внедрять ее в программные продукты. Сведения пригодятся как тем, кто только начал погружение в разработку, так и уже опытным специалистам.
Кодировки
Перед тем как разбирать код русского языка (и иных языков мира), стоит рассмотреть сначала такое понимание как кодировка. Это – более важный момент в IT и операционных системах.
Кодировка – это способ перевода информации с одного language на другой. Представлена тем или иным «алфавитом» или символьными записями. Сам процесс трансформации носит название кодирования.
Предыстория
Коды мировых языков – это тоже своеобразные кодировки. История их развития началась вместе с созданием компьютеров. Соответствующие устройства предназначались для ускорения и автоматизации разнообразных вычислений.
Изначально компьютеры оперировали только числами. К 1950-м годам за счет вычислительных мощностей ЭВМ удавалось использовать устройства для:
- составление прогнозов;
- экспериментальной и теоретической физики;
- организации расчетов по зарплате подчиненных;
- прогнозирования результатов выборов.
Развитие кодов и кодировок началось с ростом популярности ЭВМ. Устройства должны были воспринимать информацию на самых разных «раскладках», а не только уметь «работать с цифрами». Тогда разработчики стали придумывать стандарты языковых кодов. И не только в плане кодировок, но и для каждого языка мира отдельно. Сейчас же каждый вариант воспринимается системой и обозначается по-своему.
Термины
Изучая коды языков, нужно сначала хорошенько разобраться с терминологией. Здесь стоит обратить внимание на такие понятие:
- символы – минимальные единицы текстов с семантическими значениями;
- символьный набор – набор символов, используемый несколькими языковыми записями;
- кодированный набор символов – символьный набор, в котором каждый компонент соответствует своему уникальному номеру;
- кодовая точка – любое допустимое значение в обозначенном «сборнике комбинаций»;
- кодовое пространство – диапазон целых, значениями которых выступают кодовые точки;
- единица «комбинации» – «размер слова» схемы кодирования (7-бит, 8-бит, 16-бит).
Все это пригодится для представления в информатике и ЭВМ русского и других языков. Далее будут рассмотрены ключевые кодировки. А еще – специальные цифровые коды, которые можно использовать непосредственно в разработке программного обеспечения.
Концепции зарождения идеи
В 1960 году компьютеры столкнулись с одной серьезной проблемой – несовместимостью. Она наблюдалась даже в рамках одного предприятия-производителя. Универсальными такие устройства назвать было нельзя. Для каждой задачи приходилось формировать собственную символьную табличку. И, опираясь на нее, проектировать ввод/вывод электронных материалов.
В 1958 году начали появляться первые компьютерные системы. Это – сети из нескольких устройств. Пример – SAGE, которая объединила станции США и Канады. Здесь вычислительные результаты можно было использовать на других компьютерах в пределах всей сети. Чтобы добиться такого результата, пришлось создавать отдельные, единые таблицы кодов (символов).
К 1962 году IBM смогли сформировать несколько ключевых концепций развития в IT:
- устройства должны быть универсальными;
- компьютерам необходимо обеспечить полноценную совместимость друг с другом.
Через 3 года появились IBM System/360, которые включали в себя 6 моделей из совместимых модулей. Они отличались по производительности и стоимости, что позволило получить потенциальным покупателем свободу выбора. Так ЭВМ стали частью жизни «почти каждого человека». И возникла необходимость в разработке собственных стандартов распознавания символьных записей.
ASCII – первый среди кодирования
ASCII – стандарт кодирования, который является самым первым в истории развития «наборов кодов для компьютеров». Он до сих пор пользуется спросом.
Телетайпы и терминалы
Вместе с IBM и универсальными ПК началось развитие телетайпов. Это – системы передачи текстовых данных на больших расстояниях. Два принтера и столько же клавиатур соединялись парами. Текст, набранный у первого пользователя, печатался на принтере у второго. Обратный процесс тоже действовал.
Телетайпы смогли распознавать множество наименований языков. А еще – преобразовывать текст в сигналы, передаваемые при помощи проводов. Не всегда для этого задействован бинарный вариант. Иногда имеют место трехбуквенные коды на основе азбуки Морзе. Это – три символа:
- точка;
- пауза;
- тире.
Чтобы пользоваться телетайпами, нужно получить символьные коды (таблицы), которые будут опираться на соответствие по типу «текст-сигнал». Для каждого телетайпа таблички могли отличаться. Все зависело от решаемых изначально задач. Пример – написание текста на разных языках мира.
Все это помогло создать терминалы доступа к ПК. Они отправляли сообщения не второму пользователю, а на некий удаленный компьютер. Там полученные материалы обрабатывались при помощи специальных команд. Далее – происходил возврат в виде ответа.
ASCII — подробности
Изучая коды существующих языков, сначала стоит разобраться с кодированием информации. Стандарт ASCII – это самый распространенный вариант для текста. Помогает хранить и передавать различные электронные материалы. Появился в 1963 году. Изобрели его в США.
ASCII включал в себя 128 символов. Первые 32 компонента – это то, что отвечает за управление. Соответствующие элементы нужны для различных операций. Пример – чтобы управлять печатающим устройством телетайпа и выводить составные символьные записи.
Для русского языка ASCII проблему кодировки не решил. Как и для большинства остальных мировых «раскладок». Он прекрасно подошел тем, кто пишет/говорит на английском.
Зарождение Unicode
Пришлось придумывать новые концепции распознавания информации. В связи с развитием интернета данные получили широкое распространение. И путаницы в кодировках иногда приводили к весьма неприятным последствиям – то память выделялась неправильно, то на экране отображались «кракозябры».
Все это привело к тому, что в 1991 году возникла первая полная версия общей таблицы символов. Она получила название Unicode. Тогда включала в себя 7 161 компонентов из 24 мировых языков.
Постепенно кодировка совершенствовалась:
- версия 1.0.1 получила около 20 000 идеограмм японского, китайского и корейского языков;
- в современных разработках – более 143 000 элементов.
На основе Unicode начали появляться новые варианты распознавания информации. Все они достойны внимания.
Возможные кодировки на основе Unicode
Перед изучением кодов языков мира нужно обратить внимание на возможные «варианты кодирования». Записи здесь предусматривают такие стандарты, базирующиеся на Unicode:
- UTF – наблюдается разница в способе записи номера символа в виде набора байт;
- UTF-32 – номер любого компонента занимает 4 байта;
- UTF-16;
- UTF-8 – переменное число байт (самые распространенные символьные записи «отнимают» у памяти 1-2 байта, а остальные – до 4-х).
Unicode сегодня – это единый стандарт кодирования информации. Он позволяет распознавать почти все существующие символьные записи. Активно развивается и открывает больше возможностей перед разработчиками и системными администраторами.
Мировые языки – их представление
Код языка – это специальный код, который присваивает буквы или цифры в виде идентификаторов/классификаторов для того или иного мирового языка. Соответствующая форма представления пригодится каждому разработчику. Пример – чтобы документ в HTML мог видеть разного рода «раскладки клавиатуры».
Проблемы классификации
При рассмотрении соответствующего вопроса нередко возникают некоторые трудности. Они связаны с тем, что имеющиеся «таблицы комбинаций» пытаются классифицировать сложный мир, диалекты и даже сленг.
Пример – английский язык. У англичан и американцев он несколько отличается друг от друга. Имеющиеся «схемы» могут группировать как все варианты «английского» для выбора подходящей клавиатурной раскладки, так и основную массу «общего иностранного». А еще – допускается разделение диалектов с учетом специфики регионов.
Общие схемы
Существуют различные схемы представления возможных вариантов (для HTML и не только):
- Языковые теги IETF. Помогает анализировать теги. Поддерживает расширение до региональных, диалектных и частных обозначений. Может ссылаться на стандарты ISO 639, ISO 3166, а также ISO 26924. Пример – en-US. Английский, который используется в США.
- ISO 639-1. Система двухбуквенного представления. Включает в себя 136 кодов. Официально возникла в 2002 году. Может быть дополнена трехбуквенными кодами.
- ISO 639-2. Система записи символов тремя буквами. Включает 464 варианта. Пример: enm – среднеанглийский.
- ISO 639-3. Расширение предыдущего ИСО стандарта. Охватывает известные живые и неживые, разговорные и письменные языки. Всего имеет 7 589 записей.
- Глоттологические наборы. Созданы для обозначения «мелких» языков. Это – альтернатива ISO 639-3. Пример – merc1242 – мерийский.
- Регистрационные лингвосферы. Двузначное обозначение + от 1 до 6 дополнительных букв регистра Лингвасферы. Возник в 2000 году. Пример: 52- немецкий набор.
- SIL. «Расшифровки», созданные для использования в Ethnologue для языковой статистики. Согласно действующим правилам, соответствующая публикация использует ISO 639-3.
Есть еще и Verbix. Это – структурированные варианты, которые начинаются со старых кодировок SIL. Добавляют к записи дополнительные данные. На практике почти не используются.
ГОСТ
ГОСТ 7.75-97 почти полностью соответствует ИСО 639 (коды имеющихся языков ISO – это общепринятый и распространенный стандарт представления «раскладок» клавиатуры и диалектов). Базируется на кириллическом алфавите и трехбуквенных сочетаниях латинского. Дополнительно предусматривает цифровые коды из трех компонентов.
Разрабатывался стандарт Российской государственном библиотекой. Помогает хранить сведения и обрабатывать их в некоторых странах.
Таблица обозначений
В HTML и разработке рассматриваемая тема является актуальной. Спецификации распознавания информации должны быть грамотно внедрены. Иначе на экране не будут отображаться задуманные сведений.
Чтобы в HTML задать language, можно использовать такой шаблон на веб-страничке:

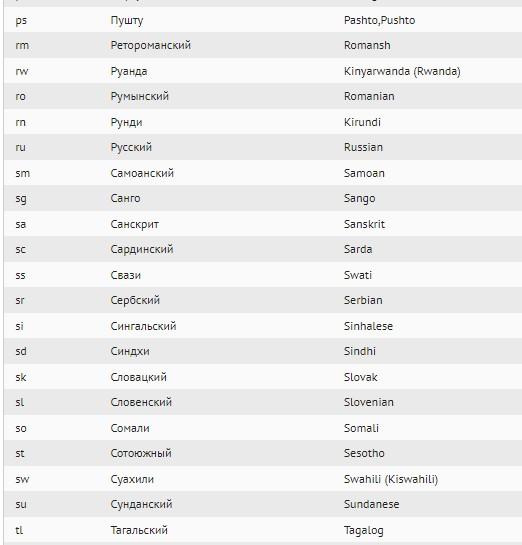
А вот – возможные формы представления в ISO 639-1:
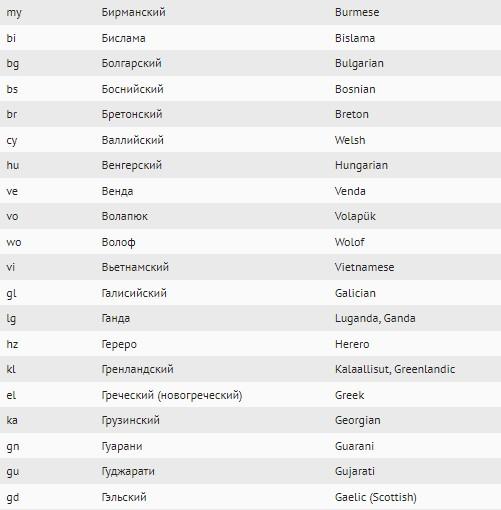
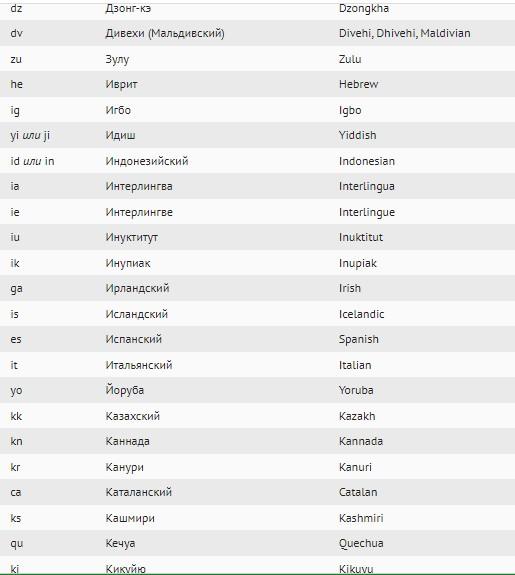
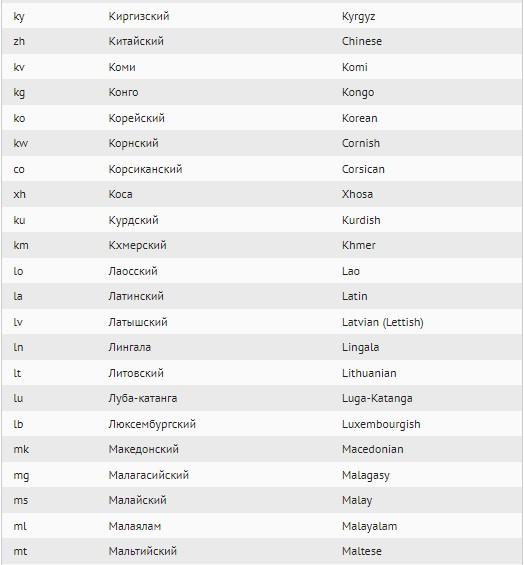
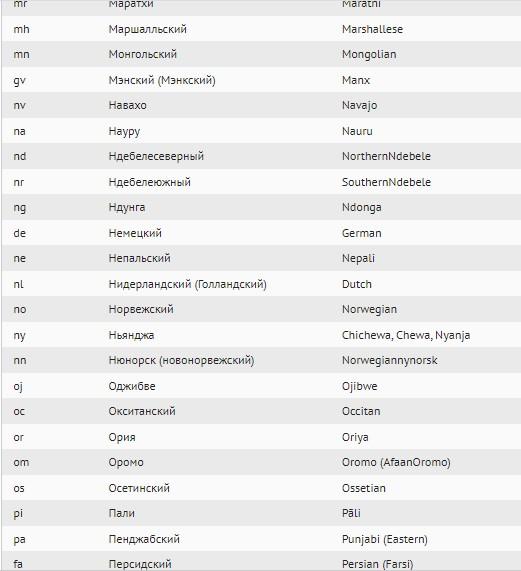


Как быстрее разобраться в теме
Чтобы лучше разбираться в информационных технологиях и разработке, рекомендуется закончить специализированные компьютерные курсы. Они проходят в онлайн режиме в качестве вебинаров с домашними заданиями и лекциями.
Это лучшее решение для тех, кто ведет активный образ жизни. Курсы совместимы с работой и семьей. К их преимуществам относят:
- разнообразие направлений;
- постоянное кураторство;
- домашние задания;
- множество практики;
- помощь в формировании портфолио;
- сжатые сроки обучения и грамотно составленные программы;
- новые знакомства;
- помощь в трудоустройстве.
В срок до 12 месяцев пользователь с нуля сможет получить инновационную IT-профессию. При успешном завершении курса выдается сертификат в электронном виде, который подтвердит приобретенные навыки, знания и умения.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!




