
Вся информация в компьютере представлена различными способами. Чтобы она была понятна устройству, а не человеку, используются различные таблицы кодирования. Они называются символьными кодировками.
Сегодня предстоит познакомиться с соответствующими компонентами поближе. Нужно выяснить, то вообще собой представляет кодирование информации, для каких именно целей оно применяется. А еще – изучить наиболее распространенные кодировки символов в современных компьютерах.
Опубликованная ниже информация рассчитана не только для IT-специалистов, но и для обычных ПК-пользователей. Она поможет выяснить принципы распознавания символьной информации современными гаджетами.
Кодирование – это…
Кодирование символов – это система представления букв, цифр, а также специальных символов при помощи числовых кодов. Процесс присвоения числовых значений графическим символам, особенно печатным символам человеческого языка.
За счет кодирования можно обеспечить символьным элементам:
- хранение;
- передачу;
- преобразование посредством компьютеров или иных цифровых современных устройств.
Числовые значения, формирующие кодировку, – это кодовые точки. В совокупности они образуют пространство кода или кодовую страницу. Это сочетание также носит название таблицы символов.
Термины и связанные определения
При изучении кодов символов необходимо запомнить несколько ключевых определений и понятий. Это поможет быстрее разобраться в выбранном направлении:
- Знак препинания – минимальная единица текста, наделенная тем или иным смысловым значением.
- Набор символов – совокупность элементов, используемых для представления текста. В качестве примера можно привести латинский или греческий алфавит.
- Кодированный символьный набор – набор символов, который преобразован в набор уникальных чисел (кодов). Исторически сложилось так, что этот компонент называется кодовой страницей.
- Набор символов – совокупность символьных компонентов, которые могут быть представлены определенным набором кодированных символов. Этот элемент бывает закрытым – в него не допускаются никакие изменения без формирования нового стандарта. Также набор символов бывает открытый. Он допускает разнообразные дополнения.
- Кодовая точка – значение или позиция символа в кодировке набора символов.
- Кодовое пространство – диапазон числовых значений (кодов), задаваемых набором кодируемых символов.
- Кодовая единица – минимальная комбинация битов, которая может представлять собой символ в символьной кодировке. В информатике этим термином характеризуют размер слова в кодировке.
Теперь можно более подробно рассмотреть варианты кодов, используемых для представления печатных элементов в современных компьютерах.
ASCII
ASCII или American Standard Code for Information Interchange – это американский стандартный код информационного обмена. Произносится как «Аски».
Он был разработан в 1963 году. ASCII до сих пор используется для работы с кодами в компьютерах, хоть и не слишком часто.
Данный «код» представляет собой кодировку интерпретации:
- десятичных цифр;
- латинского и национального алфавитов;
- управляющих символов;
- знаков препинания.
Изначально код создавался 7-битным. С его развитием каждый элемент стал храниться в 8 битах. Старший бит всегда установлен в 0. Теперь распространена 8-битная ASCII. В компьютерах чаще всего используются расширения «Аски» с задействованной второй половиной байта.
У ASCII есть вариант без национальных составляющих. Он называется US-ASCII. Всего в рассматриваемой кодировке представлено 128 символьных элемента. Для каждого устанавливается свой код интерпретации. В состав ASCII сейчас входят не только ранее перечисленные компоненты, но и:
- математические символы;
- арабские цифры;
- заглавные и строчные буквы латинского алфавита;
- 32 управляющих символьных записи.
Сейчас управляющие компоненты используются редко.
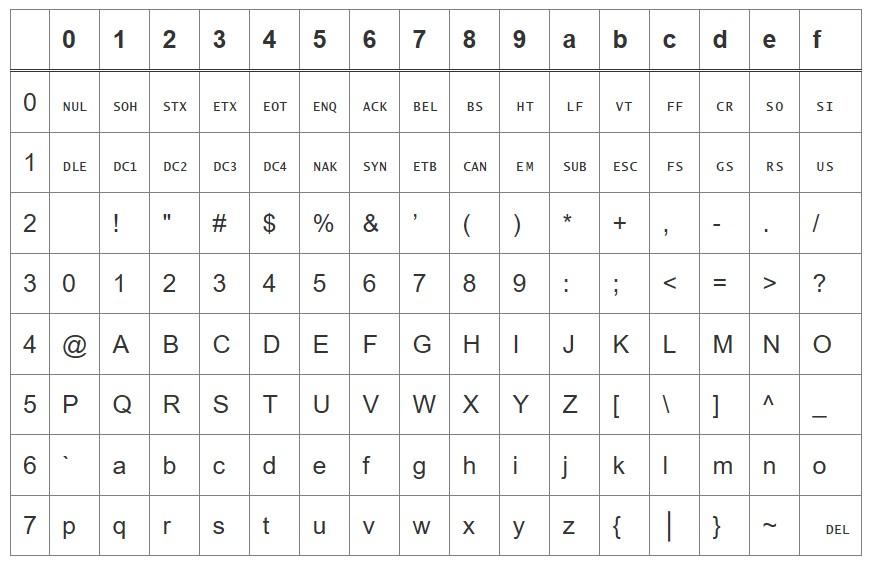
Выше можно увидеть, как выглядит таблица ASCII.
Расширенные ASCII
ASCII стала основой для развития разнообразных современных кодировок. Изначально в ней было всего 128 составляющих. В расширенной интерпретации получилось присвоить коды 256 элементам. Их можно было закодировать в одном байте информации. Это привело к возможности добавления в «Аски» букв национальных языков.
В качестве расширенного ASCII появилась CP866. В ней можно было присвоить коды русскому алфавиту. Ее верхняя часть полностью совпадала с базовой версией «Аски». Нижняя обладала несколько измененным видом. С помощью CP866 появилась возможность кодирования русских букв и псевдографики.
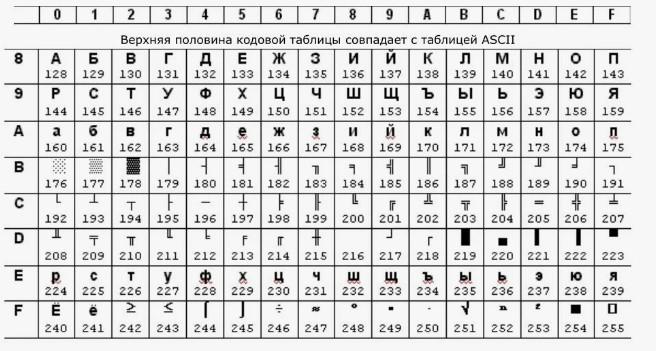
CP866 распространялась компанией IBM. Для представления русского языка со временем появились другие кодировки расширенной интерпретации «Аски». В качестве примера можно привести KOI-8.
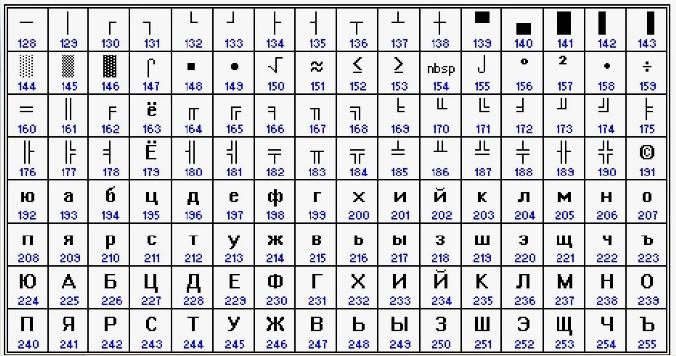
Принцип работы с кодами здесь точно такой же, как и у CP866 – каждый элемент текста кодируется одним байтом. Первая половина совпадает с «Аски», поэтому выше представлена вторая ее часть. В KOI-8 кириллические буквы в таблице будут идти не в алфавитном порядке, как в CP866.
Windows-1251
Символы ASCII и некоторые ее расширенные версии уже изучены, но на них развитие таблиц кодов не закончилось. Дальнейший прогресс связан с тем, что графические операционные системы начали набирать огромную популярность. Псевдографика стала отходить на второй план. Со временем она вовсе пропала. Это привело к появлению целой группы расширенных версий «Аски», но без псевдографических составляющих. Они стали относиться к ANSI-кодировкам, разработанным американским институтом стандартизации. Наиболее популярным вариантом выступила кодировка Windows-1251.
Вместо псевдографики тут появились:
- символы русской типографики (без знака ударения);
- символы, используемые в близких к русскому славянских языках (белорусскому, украинскому и так далее).
Из-за такого обилия методов шифрования русского языка у производителей шрифтов и программного обеспечения стали возникать проблемы. Это привело к тому, что вместо положенного текста на экране начали появляться так называемые «кракозябры». Она символизирует о путанице кодов, используемых в тексте.
Windows-1251 была создана компанией Microsoft. Она является стандартной 8-битной кодировкой русских версий операционных систем Windows до 10-ой версии включительно. Раньше была очень популярна, но сейчас ее распространенность значительно упала.
Unicode
Unicode (или «Юникод») – это современный стандарт представления символьных данных кодами. Он появился из-за того, что одним байтом информации невозможно описать алфавиты групп юго-восточной Азии (иероглифы).
Это привело к тому, что в 1991 году некоммерческая организация «Консорциум Юникода» представила свою собственную разработку кодирования данных. Она получила название Unicode. Применение соответствующего стандарта позволяет закодировать очень много разнообразных элементов систем письменности:
- математические компоненты;
- буквы кириллицы, латиницы, греческого алфавита;
- элементы музыкальной нотной нотации;
- китайские и японские иероглифы.
При использовании «Юникода» переключаться между кодовыми таблицами не нужно. Этот стандарт включает в себя две части: универсальный символьный набор (UCS), а также семейство кодировок (UTF). В первом случае код выражается неотрицательным целым числом, записываемым в шестнадцатеричной форме с префиксом U+. Во втором случае определяются способы преобразования кодов для передачи в файлах или потоках.
UTF-32
Unicode предусматривает несколько интерпретаций. Каждая из них поддерживает свои ключевые особенности. Первой вариацией упомянутого стандарта стал UTF-32. Цифра в его названии указывает на количество бит, используемых для кодирования одного элемента.
32 бита – это 4 байта данных. Столько необходимо для одного единственного знака в универсальной кодировке UTF. Это привело к тому, что один и тот же файл с текстом, закодированный в ASCII и UTF-32, в последнем случае будет весить в 4 раза больше. Это плохо, зато пользователи смогли с таким методом шифровать миллиарды печатных элементов и знаков.
UTF-16
Количество доступных для шифрования знаков при помощи UTF-32 многим языкам не требовалось. Это только приводило к образованию очень «тяжелых» исходных файлов, а также приводило к увеличению объема интернет-трафика и хранимых сведений. Подобное расточительство в годы развития кодировок мало кто мог себе позволить.
Это привело к появлению новой вариации стандарта – UTF-16. Она стала настолько удачной, что была принята в качестве базового пространства всех знаков, которые сейчас используются в компьютерах. Для кодирования тут используются всего 2 байта.
Посмотреть соответствующую таблицу можно прямо в Windows. Для этого предстоит:
- Открыть «Пуск».
- Переключиться в «Программы»–«Стандартные».
- Выбрать пункт «Служебные».
- Кликнуть по «Таблица символов».
- Переключиться в «Дополнительные параметры» и включить Unicode.
Теперь у каждого шрифта можно посмотреть представление знаков в виде UTF-16. Соответствующие коды размещаются в левом нижнем углу окна. Они включают в себя 4 шестнадцатеричных цифры.
UTF-8
UTF-8 – это кодировка переменной длины. Еще один стандарт «Юникода», который стал результатом развития информационных технологий. Несмотря на 8 в названии, кодировка действительно имеет переменную длину. Каждый элемент в таблице может быть закодирован последовательностью длиной от 1 до 6 байт.
На практике в UTF-8 используются от 1 до 4 байт. Все, что находится за пределами этого диапазона, трудно представить. Латинские знаки тут кодируются в 1 байт, как в ASCII.
Если приложение не понимает Unicode, оно все равно сможет работать в UTF-8. Кириллица здесь кодируется в 2 байта, грузинский алфавит – в 3.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!


