
Привет! Я — Максим Чудинов, выпускник курса «SRE практики и инструменты». В конце обучения каждый студент курса выполнял итоговую работу, чтобы закрепить полученные знания. Я расскажу про свой проект «Кластер Opensearch для централизованного хранения логов».
Предыстория
Я инженер команды мониторинга в Cloud.ru. Одним из направлений мониторинга и работы нашей команды является обеспечение сбора логов с элементов инфраструктуры компании и их длительного хранения. На момент начала обучения на курсе, хранение логов в компании осуществлялось на 18 кластерах Elasticsearch, о которых я рассказывал на Big Monitoring Meetup 9. Все кластеры работали на устаревшей версии 7.9, а перейти на более свежую версию, по сумме обстоятельств, мы не могли. Поэтому приняли решение перейти с Elasticsearch на Opensearch.
Кластеров у нас много, а в перспективе будет еще больше. Запускать новые и расширять существующие нужно быстро. В рамках учебного проекта я разработал решение по автоматизации развертывания стека Opensearch на виртуальных машинах с Ubuntu 20.04.
При разработке нужно было учесть важное условие — описание конфигурации всех кластеров должно храниться в одном месте, чтобы можно было разворачивать/обновлять/вносить изменения коммитом в одном репозитории.
Особенности Opensearch
Поскольку Opensearch — это форк Elasticsearch 7.10, особых отличий в работе кластера нет. Для проведения теста можно было поднять однонодовый кластер, но я сразу использовал рекомендованную производителем конфигурацию — от трёх нод.
Ноды это хранилище данных и основа стека. Также частью стека являются фронтенд — для удобного поиска по индексами, и коллекторы — при необходимости предобработки и работы в распределенной инфраструктуре.
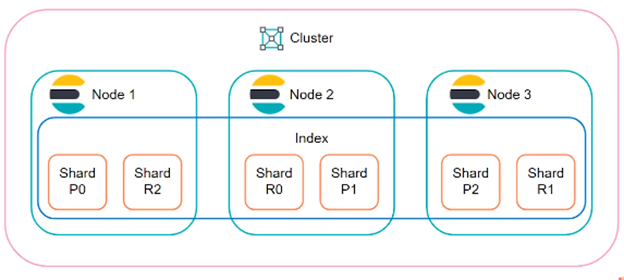
События из журналов систем и оборудования отправляются в кластер и складываются в индексы. Индексы имеют один основной шард и от нуля до нескольких его реплик. Количество реплик зависит от количества нод. Кластер сам распределяет шарды таким образом, чтобы на одной ноде в один момент времени не находились основной шард и его реплика. За счет этого обеспечивается надежность хранения, а шардирование ускоряет выполнение поисковых запросов.
Описание решения
Чтобы развернуть 18 однотипных кластеров сейчас, N-е количество в будущем и поддерживать их дальше, я решил использовать Ansible. Для нод написал роль opensearch, для фронтенда роль opensearch_dashboards. Также подготовил описание кластеров в соседнем репозитории.
В ролях предусмотрел тестирование с помощью molecule. При этом разворачиваются три ноды, кластер инициализируется дефолтными параметрами, проверяется возможность авторизации и возврат статуса.
Аналогично для фронтенда: всё запускается в контейнерах, а если не выполнять шаг destroy, то можно получить полноценную инсталляцию, походить по интерфейсу и попробовать настройки.
Из-за отсутствия DNS в некоторых сегментах инфраструктуры в инвентаре мы используем параметр ansible_host с IP-адресом. С molecule в контейнерах такой возможности нет — адреса выдаются произвольно и сетевой доступ осуществляется по именам. А мне для конфигурации каждой ноды нужно было собрать массив IP-адресов всех нод.
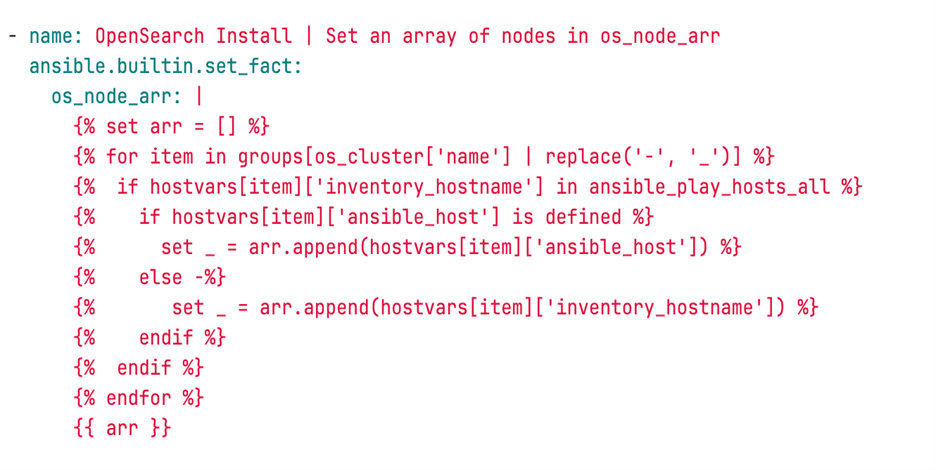
Чтобы роли работали и в тесте, и на виртуальных машинах, я написал код с формированием списка хостов в зависимости от значения ansible_host. Нативными командами ansible реализовать не получилось, поэтому я написал код на jinja2.
Основой для применения ролей служит инвентарь — он описан в файле opensearch_cluster/inventory/hosts и содержит только имена и адреса целевых машин. Сами роли применяются к группам, описание которых можно увидеть в файле opensearch_cluster/inventory/logsearch.yml.
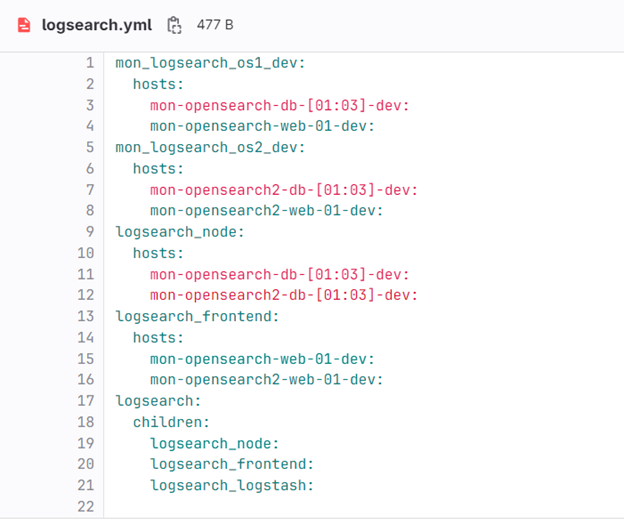
Соответственно, для нод это группа logsearch_node, для фронта logsearch_frontend. И группа logsearch_logstash заложена на перспективу использования инвентаря для коллектора logstash.
Общие сертификаты безопасности я вынес в групповые переменные и в будущем планирую перенести их в корпоративный Vault.
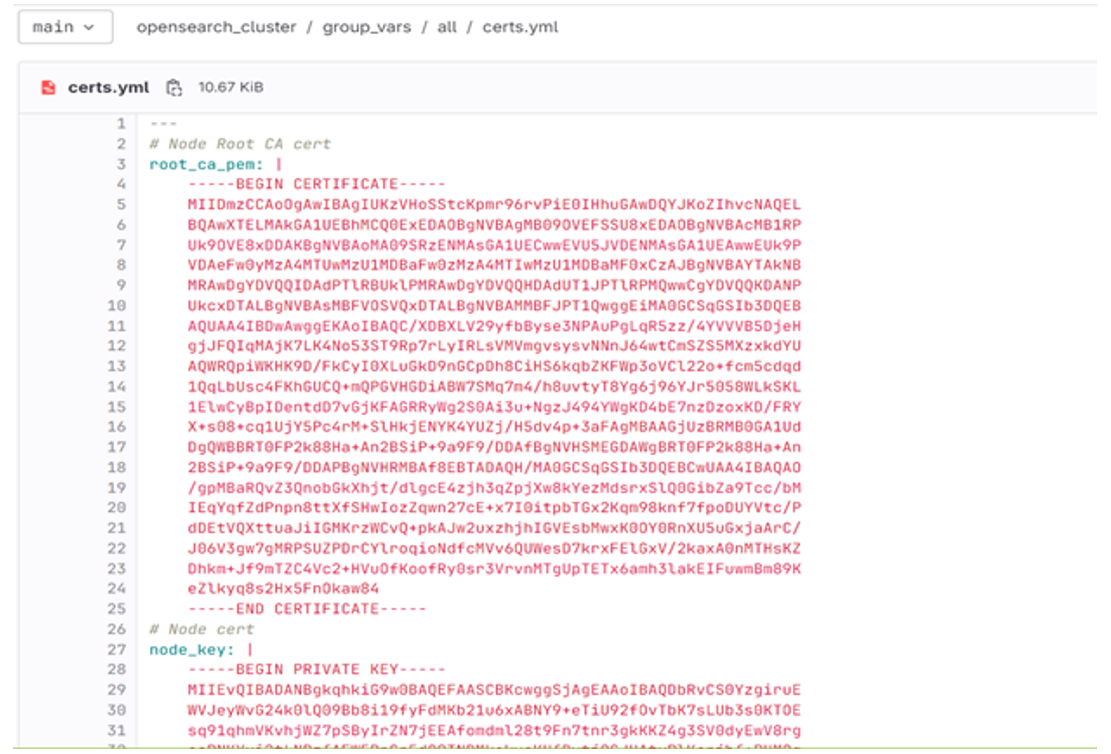
В отдельном файле в словаре clusters описаны параметры каждого кластера. Поле type для возможности развертывания как opensearch, так и elasticsearch. Сертификаты берутся из общих переменных, при этом для каждого кластера можно переопределить свой. Куски для конфигурационных файлов internal_users.yml и roles_mapping.yml описаны в виде plain text.
Все зависимости я свёл в requirements.yml, а средствами Gitlab CI/CD настроил выполнение плейбука при коммите изменений репозитория в основную ветку.
SLA решения
Архитекторы Cloud.ru определили для кластера SLA в 97%. Для себя я установил SLO в 98%. С помощью ресурса uptime.is проценты превращаются в допустимые периоды простоя
Daily: 28m 48s
Weekly: 3h 21m 36s
Monthly: 14h 29m 23s
Quarterly: 1d 19h 28m 8.8s
Yearly: 7d 5h 52m 35s
По факту Opensearch очень стабильный готовый продукт. Вывести из строя может только падение операционной системы или несоблюдение рекомендаций разработчиков.
Но эта стабильность не отменяет обязательного мониторинга. Я определил несколько ключевых метрик (SLI):
- Health status — доступность кластера и его способность принимать новые данные;
- Indexing rate — скорость поступления событий;
- Indexing latency — задержка записи событий;
- Failed get operations — ошибки поисковых запросов;
- Storage utilization — величина использования хранилища кластера;
- Product Index size — размер индексов каждого продукта источника;
- Estimated time to 15% free space — прогнозное время до достижения 15% остатка хранилища.
Для сбора метрик использовал Zabbix и немного доработанный шаблон Elasticsearch, а визуализацию настроил средствами Grafana.
С помощью шаблонных наименований хостов (naming convention) получилось сделать динамический шаблон, который отображает SLI по каждому кластеру. С помощью метрики Estimated time организовал capacity management.
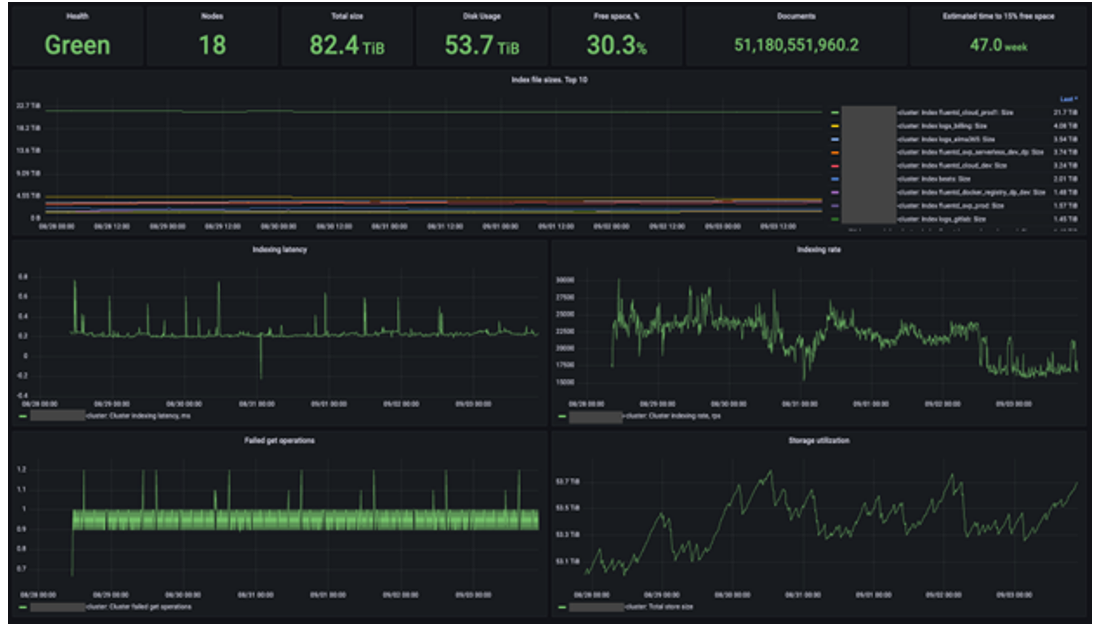
По размерам индексов продуктов сделал фрейм с Top 10 и графиками изменения. Продукты — это системы или комплексы, например, корпоративный кластер Confluence или Gitlab, или кластер K8s для облачных сервисов. Продукт включает в себя множество источников событий, и каждый в любой момент может значительно увеличить количество генерируемых событий.
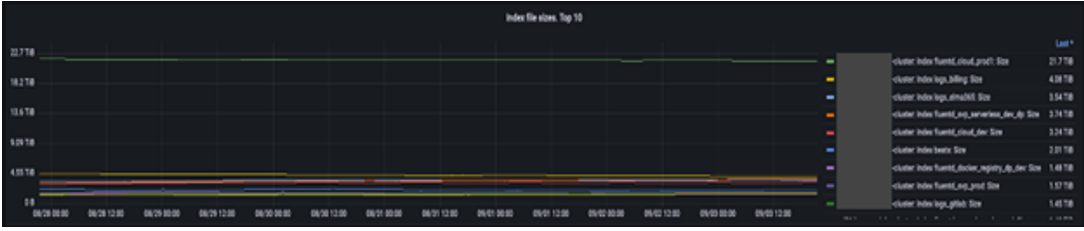
Мы не применяем жёстких ограничений и не фильтруем события — так можно потерять действительно важные данные. Что отправить в хранилище — решает команда каждого продукта.
Поскольку хранилище не бесконечное, важно отслеживать, какой продукт и сколько места занимает. Для этого мы создали Logging budget: теперь события от каждого продукта попадают в отдельный индекс и можно сразу увидеть, сколько места в байтах они занимают. При резком росте значения команда-владелец разбирается в причинах.
Планы
Я планирую развивать проект дальше: перенести все секреты и сертификаты в Vault, разработать и подключить роль logstash, собрать логи всех элементов проекта в один индекс и настроить предупреждения по аварийным событиям. Также предстоит договориться с командами разработки внутренних продуктов о формате событий приложений (contract), чтобы избежать ошибок несовпадения типов данных при индексировании.
Хотите знать об SRE больше? Добро пожаловать на специализированный курс в Otus!




