
Информация для бизнеса и его продвижения – один из самых ценных ресурсов. Это привело к тому, что владельцы различных компаний стали интересоваться изобретением и приобретением специализированных инструментов для сбора и анализа данных.
Одним из подобных продуктов выступает так называемый парсер. Далее предстоит познакомиться с ними получше. Необходимо разобраться в особенностях и областях применения парсеров, их преимуществах и недостатках. Также предстоит изучить алгоритм написания первого такого инструмента на Python. В работе будет использована библиотека Beautiful Soup. Предложенная информация пригодится как программистам-новичкам, так и их более опытным коллегам.
Определение
Google характеризует парсер как программу, с помощью которой осуществляется сбор данных с различных веб-сайтов, их анализ и объединение в информационные базы в различных форматах. Подобный сервис избавляет клиентов от необходимости выполнения огромного объема однотипных задач, а также экономит время и силы.
Парсер – приложение для сбора и анализа данных. Парсинг – это сам процесс сбора информации. Он может осуществляться как вручную, так и через специальные программы.
Области применения
Парсинг, согласно Google – операция, которая применяется в любых областях, где требуется анализ и систематизация крупных информационных объемов.
Чаще всего парсинг встречается в:
- Разработке программного обеспечения. Компьютеры способны воспринимать только машинный код – набор нулей и единиц. Чтобы устройство выполняло различные операции, нужно пользоваться языками программирования. Они понятны разработчикам, но не компьютерам. Из-за этого специальные программы сначала проводят парсинг написанного приложения, затем – переводят их в бинарный машинный код для дальнейшей обработки.
- Создании сайтов. HTML и другие языки разметки по умолчанию компьютерам не понятны. Для отображения HTML-разметки в виде понятного и структурированного интерфейса сайта используются парсеры. Они встроены в браузеры. Данные приложения, согласно Google, переводят HTML-код в машинный формат. Парсинг также дает возможность обнаруживать ошибки в получившемся сайте.
- Веб-краулинге. Так называется частный случай парсинга. Google указывает, что при краулинге робот-парсер поисковой системы в ответ на пользовательский запрос будет просматривать релевантные ему страницы, а затем – выбирать наиболее подходящую по содержанию страницу. Краулеры не занимаются извлечением информации с сайтов. Они только ищут совпадения с пользовательским запросом.
- Агрегации новостей. Рассматриваемые программы используются для упорядоченной подачи новостей.
- Интернет-маркетинге. В SEO и SMM при помощи парсеров, согласно Google, осуществляется сбор и анализ данных пользователей, товарных позиций в Интернет-магазинах, метатегов, ключевых слов и иной информации. Соответствующие сведения будут использоваться для оптимизации сайтов, их продвижения в социальных сетях, а также для настройки таргетированной и контекстной рекламы.
- Мониторинге цен. Google подчеркивает, что при помощи программ-парсеров можно извлекать расценки товаров на сайтах-конкурентах для дальнейшего анализа ситуации на рынке. Эти данные также помогают формировать ценовую политику.
Google подчеркивает, что парсинг (parsing) – это очень полезная операция для бизнеса и SEO/SMM.
Принцип работы
Слово «парсинг» произошло от английского «to parse» – «по частям». Google описывает рассматриваемый процесс как синтаксический анализ любого представленного набора связанных друг с другом данных.
В общих чертах можно представить работу парсеров так:
- Сначала сканируется исходный информационный массив (HTML-коды, базы данных, текст и так далее).
- После – осуществляется поиск и выявление семантически значимых единиц по заданным параметрам. Примерами могут послужить заголовки, ссылки, абзацы с жирным выделением, пункты меню.
- Завершается процесс конвертацией полученной информации в формат, удобный для изучения человеком, а также ее систематизация в виде таблиц или отчетов.
Google отмечает – объектом парсинга может стать любая грамматически структурированная система: информация, закодированная естественным языком, математическими выражениями, языками программирования и так далее.
Используемые алгоритмы
Примером использования парсинга может послужить SEO-оптимизация сайта. В процессе работы соответствующие приложения действуют по двум алгоритмам:
- Нисходящий парсинг. Google описывает его как анализ, который осуществляется от общего к частному. Синтаксическое дерево разрастается вниз.
- Восходящий парсинг. Согласно Google, это анализ и построение синтаксического дерева, которые осуществляются снизу-вверх.
Выбор метода реализации рассматриваемой процедуры зависит от итоговой цели. Программа-парсер в случае чего должна уметь вычленять из общего массива только необходимую пользователю информацию и преобразовывать ее в удобный для решения той или иной задачи формат.
Преимущества и недостатки
Программы-парсеры, согласно Google, имеют следующие преимущества:
- возможность автоматизации процесса анализа информации;
- снижение нагрузки на сотрудников при работе с большими информационными объемами;
- экономия времени сотрудников компании на решение тех или иных задач;
- ускорение анализа большого объема данных;
- выявление ошибок на сайтах или в любых других информационных продуктах, если в приложении заданы соответствующие настройки.
Рассматриваемый инструмент – это функциональное и полезное программное обеспечение, но оно имеет некоторые недостатки. К ним можно отнести не всегда релевантный анализ данных. Этот момент напрямую зависит от возможностей выбранного для парсинга программного обеспечения. Большинство таких продуктов позволяют осуществлять детализированную настройку для обработки информации.
Написание парсера
Задумываясь над тем, как создать парсер, необходимо сначала определиться с языком программирования. Далее будет представлен код соответствующего инструмента на Python. Этот язык разработки является достаточно простым для понимания. Он поддерживает множество библиотек и фреймворков, значительно упрощающих написание программного обеспечения.
Библиотеки Python для парсинга
Google отмечает, что у Python предусматриваются разнообразные библиотеки, помогающие в создании парсеров. Их несколько, но упор будет сделан всего на одну – Beautiful Soup.
Requests
Библиотека, позволяющая выполнять HTTP-запросы при помощи Python. С ее помощью можно значительно облегчить отправку HTTP-запросов, особенно по сравнению со стандартной Python-библиотекой HTTP. Requests имеет огромную роль для скрапинга и парсинга. Это связано с тем, что для сбора информации со страницы сначала необходимо получить ее через HTTP-запрос GET.
Beautiful Soup
Beautiful Soup (далее – просто Soup) – библиотека, которая значительно упрощает сбор информации со страниц. Она поддерживает работу с любым HTML- или XML-парсером, а также предоставляет все необходимое для поиска, итерации, модификации абстрактного синтаксического дерева.
Beautiful Soup разрешено использовать вместе с html.parser. Это парсер, который, согласно Google, включен в стандартную библиотеку Python. Он позволяет парсить текстовые HTML-документы. Beautiful Soup поможет обойти DOM и извлечь из него необходимую информацию.
Selenium
Google называет Selenium современной системой автоматизированного тестирования с открытым исходным кодом. С ее помощью получится выполнять различные операции на страницах в веб-браузерах.
Selenium даст возможность поручить браузеру выполнение некоторых задач. Страницы, посещаемые данной «библиотекой», отображаются в реальном браузере. у Selenium есть все необходимое для создания собственного парсера без привлечения дополнительных инструментов.
Установка библиотек
Перед началом разработки рассматриваемого приложения необходимо сначала установить ряд Python-библиотек. К ним относятся: lxml, Beautiful Soup и Requests. Сделать это лучше всего через pip:
pip install lxml
pip install requests
pip install beautifulsoup4
Теперь все готово к полноценной разработке. Она будет вестись в несколько этапов. Такой подход, согласно Google, позволяет лучше разобраться в процедуре написания рассматриваемого приложения.
Поиск сайта для работы
Знакомство с рассматриваемой операцией рекомендуется проводить при помощи этого сайта: https://quotes.toscrape.com/. Он был создан для скрапинга и парсинга.
С помощью соответствующего сервиса можно сделать хранилище имен авторов, тегов или имеющихся цитат. Для этого достаточно изучить исходный код страницы. Это те самые данные, что будут возвращаться на посылаемый запрос. В современных браузерах посмотреть код сайта получится, если кликнуть правой кнопкой мыши на странице и выбрать пункт «Просмотр кода страницы».
На экране появится HTML-разметка. Вот ее наглядный пример:
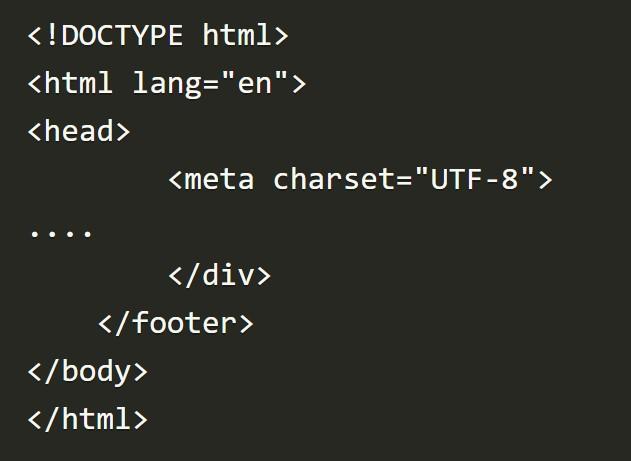
Здесь можно заметить, что разметка включает в себя массу перемешанных данных. Задачей веб-скраппинга, согласно Google, является получение доступа к тем частям страницы, которые действительно нужны для дальнейшей работы пользователя. Соответствующая операция возможна при помощи регулярных выражений, но лучше всего пользоваться библиотекой Beautiful Soup.
Создание скрипта
Теперь можно начать написание программного кода для будущего приложения-парсера. В любой IDE (пример – PyCharm) нужно добавить новый файл. Этот документ будет отвечать непосредственно за парсинг.
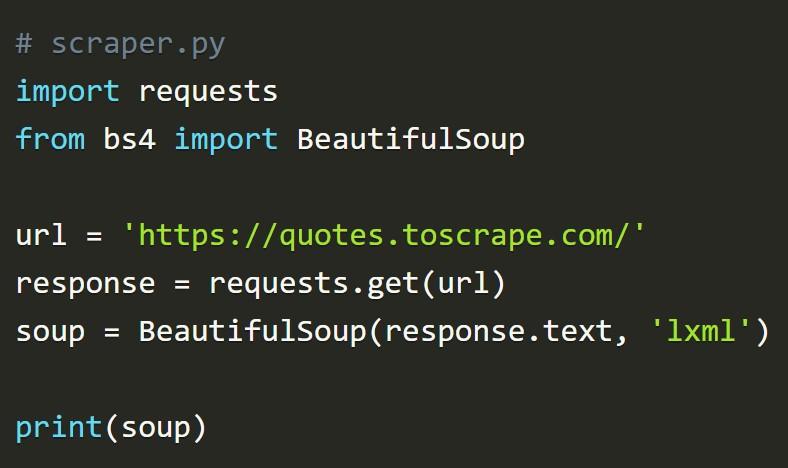
Выше можно увидеть начало будущего приложения. Google указывает, что данный фрагмент работает так:
- В верхней части файла осуществляет импорт библиотек: Requests и Beautiful Soup.
- Далее в переменной url происходит сохранение адреса страницы, с которой поступает информация.
- Url (переменная) передает функции requests.get().
- Результат передается переменной response.
- Далее используется конструктор BeautifulSoup(). Он необходим для размещения текста ответа в переменную soup.
- В качестве используемого формата выбран lxml.
- В самом конце нужно вывести переменную soup на экран.
Google описывает работу предложенного фрагмента так:
- Приложение заходит на обозначенный сайт.
- Осуществляется считывание данных.
- Программа-парсер получает исходный код.
Все это – аналогия ручного подхода, но с помощью предложенного фрагмента запуск процесса осуществляется буквально в один клик.
HTML-структура
HTML – это язык гипертекста. Он включает в себя множество разнообразных тегов. Стандартными (и основными) выступают всего три элемента:
- body;
- html;
- head.
Эти теги отвечают за организацию всего HTML-документа. В случае с парсингом и скрапингом, согласно Google, значимость имеет только body.
Ранее представленный фрагмент кода с Beautiful Soup уже получает информацию о разметке с указанного веб-адреса. Теперь необходимо сконцентрироваться только на интересующих пользователя сведениях.
Если в браузере активировать инструмент «Inspect» (сочетанием CTRL+SHIFT+I), можно увидеть, какая из частей разметки отвечает за те или иные компоненты на веб-странице. Достаточно навести курсор на определенный тег span, чтобы он подсветил соответствующую информацию. Google отмечает, что каждая цитата относится к тегу span с классом text.
Так осуществляется дешифровка данных, которые необходимо получить. Сначала требуется найти некий шаблон на заданной странице, а затем – создать код, который будет для него работать. Скрапинг позволяет извлекать все похожие разделы HTML-документа.
HTML-разметка и ее парсинг
HTML-документы включают в себя множество информации, но за счет библиотеки Beautiful Soup становится намного проще искать нужные данные. Обычно для этого достаточно написать всего одну строку кода.
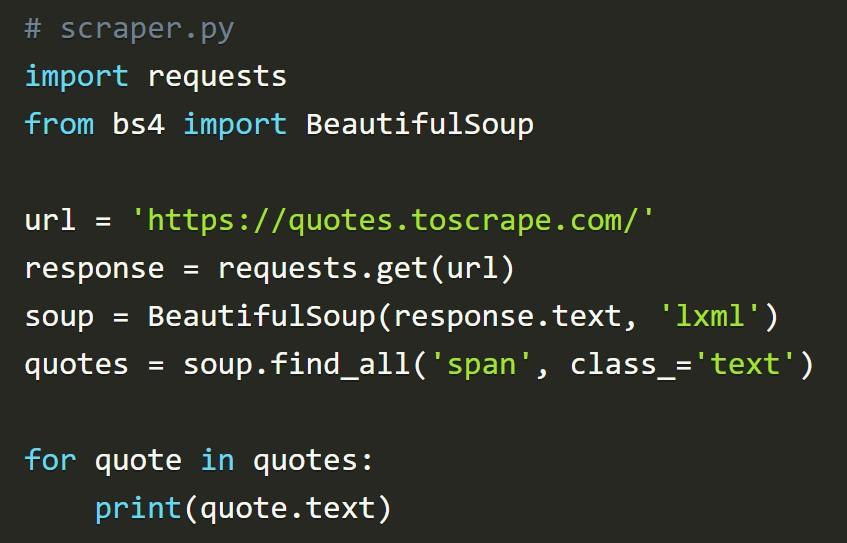
Необходимо найти все теги span с классом text. Если нужно отыскать несколько одинаковых тегов, предстоит пользоваться функцией find_all():
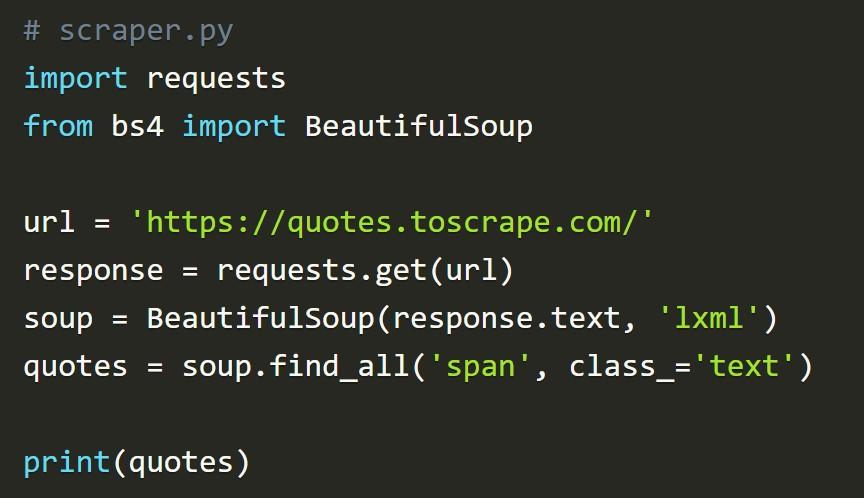
В результате работы данного фрагмента переменная quotes получит список элементов span с классом text из имеющегося HTML-файла.
Beautiful Soup и свойство text
Возвращаемая разметка – это не то, что нужно специалистам в процессе парсинга. Для получения только информации (в предложенном примере – цитат) требуется использовать свойство .text библиотеки Beautiful Soup.
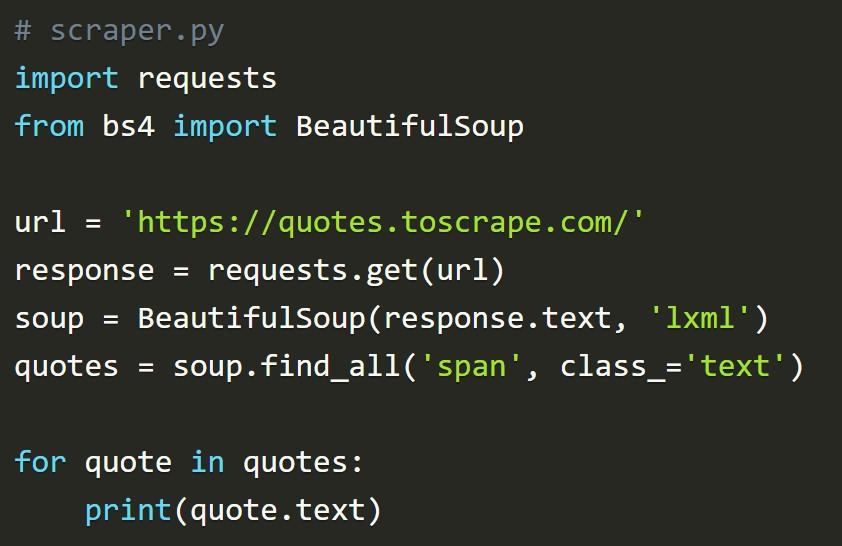
Выше представлен код, который перебивает все полученные данные и выводит только нужное человеку содержимое.
Для поиска и вывода всех авторов используется следующий код:
Здесь:
- Сначала осуществляется ручное изучение страницы. Можно обратить внимание на то, что каждый автор заключен в тег <small> с классом author.
- Использовать функцию find_all().
- Сохранить результат в переменную authors.
Рекомендуется также поменять цикл. Это поможет сразу при помощи Soup перебирать цитаты и авторов.
Завершающим этапом процесса Google называет получение всех тегов для каждой имеющейся цитаты. Здесь сначала придется получить каждый внешний блок каждой теговой коллекции. Если этого не сделать, при помощи Soup получится извлечь теги, а ассоциировать их с конкретной цитатой – нет.
После получения блока можно опуститься ниже, используя функцию find_all для соответствующего подмножества. Заключительным этапом работы с Soup станет добавление внутреннего цикла для прекращения процесса.
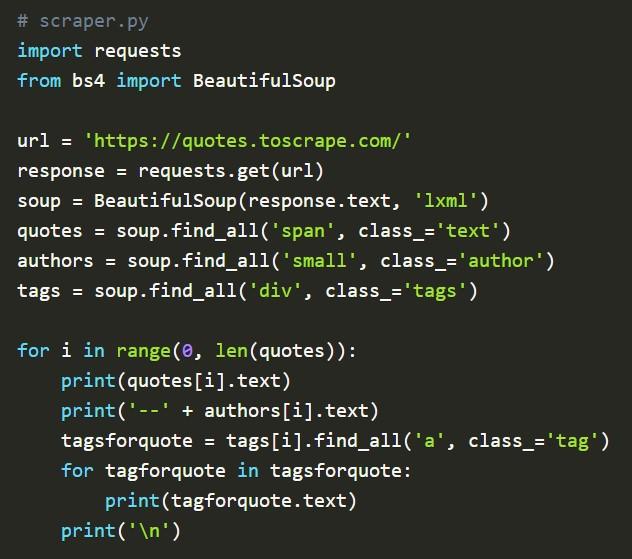
Выше можно увидеть наглядный пример того, как написать парсер при помощи Beautiful Soup. Это всего лишь один из множества вариантов. Лучше разобраться с рассматриваемой операцией, Python и Beautiful Soup помогут дистанционные компьютерные курсы.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!




