
Pandas – специальная программная библиотека, оснащенная открытым исходным кодом. Предназначается для разработки на Python и широко используется при обработке и анализе данных.
Данный модуль поддерживает несколько типов данных:
- DataFrame;
- Series;
- Panel.
Последний используется редко, поэтому ему уделять внимание не будем. Далее предстоит разобраться с операциями с DataFrame. Пример – добавление колонок.
Где используется модуль
Но перед непосредственной работой с упомянутым модулем, необходимо выяснить, когда и где он пригодится. Пандас используется при:
- Аналитике данных. Библиотека позволяет подготовить информацию для дальнейшей обработки. Она поможет удалить или заполнить пропуски, организовать сортировку или внести те или иные изменения.
- Data Science. С его помощью можно подготовить и первично проанализировать информацию. Все это помогает машинному и глубокому обучению.
- Статистике. У Pandas (PD) присутствует поддержка ключевых статистических методов. Они используются для более быстрой и эффективной обработки информации. Пример – расчет средних значений.
Pandas – инструмент, который используется для грамотной и быстрой визуализации имеющихся материалов. В основном базируется на столбцах и строках.
Типы данных
Пандас поддерживает три типа данных – одномерные массивы неизменного размера, двумерные табличные структуры и трехмерные массивы.
Наиболее распространенным вариантом является DataFrame. Разработчикам также предстоит часто иметь дело с Series. Эти информационные структуры поддерживают различные операции, реализации которых отнимают минимум времени. Далее предстоит выяснить, как вывести на дисплей устройства столбец таблицы.
Series – описание
Класс Series – объект, напоминающий одномерный массив. Он включает в себя совершенно любые типы информации. Представляет собой столбец таблицы с некой заданной последовательностью значений. Каждый «пункт» здесь имеет так называемый индекс – строковый номер.

Выше – фрагмент кода, который демонстрирует создание объекта Series.

А вот – результат, который появится на экране. Самый левый столбец — это индексы. Справа от них будут выводиться присвоенные значения.
DataFrame – что это
Dataframe – основной объект в Pandas. Вокруг него строится вся дальнейшая работа модуля. DataFrame представляет собой таблицу с разными типами столбцов. Является стандартным способом хранения информации в электронной форме. Напоминает таблицы SQL, а также Excel и БД.
Внутри ячеек могут размещать различные данные:
- булевы;
- строки;
- числа и другие.
DataFrame поддерживают индексирование не только столбцов, но и строк. Это помогает сортировать и фильтровать информацию, а также быстро искать те или иные значения.
Рассматриваемый объект модуля поддерживает как жесткое кодирование, так и импорт информации. Он распознает форматы:
- таблиц SQL;
- TSV;
- таблиц Excel;
- CSV.
Добавить в код DataFrame можно при помощи записи:
.
В данной форме:
- data – создает объект из входных данных;
- index – указывает на строковые метки;
- columns – имя столбца (подпись);
- dtype – ссылка на информационный тип, который содержится в каждом столбце (указывать его не обязательно);
- copy – копирование информации.
Получить DataFrame можно несколькими способами. Пример – формирование посредством кортежей или списков словарей.
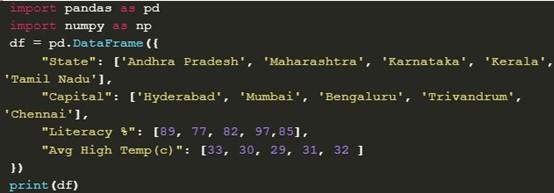
Этот код выведет на экран такую запись:
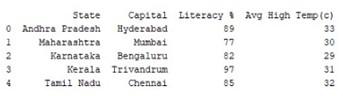
Принцип работы приведенного примера прост – сначала создается словарь, в него передается в виде аргумента метод DataFrame. Далее присваиваются значения, которые система выводит на печать.
Индексами служит самый левый столбец – это строковые метки. Заголовки и указанные сведения формируют самую таблицу. За счет индексных параметров получается формировать индексированные DataFrames.
Импортирование CSV
Для формирования DataFrame можно использовать готовый CSV-документ. Импорт из него – распространенный способ создания объекта в Pandas.
CSV – это текстовый файл. В нем записи данных и имеющихся значений производятся в каждой строке. Здесь присутствует разделитель по умолчанию. Это – символ запятой.
Для считывания CSV-документов в Пандас используется специальный метод – read_csv(). Он поддерживает сразу два параметра:
- Sep. Устанавливает разделители, используемые во время выгрузки объемов информации. Параметр может быть полезен, если в исходном файле CSV установлены нестандартные разделители: табуляция или точки с запятыми.
- Dtype. Позволяет явно указать тип данных, используемых в столбцах. Помогает тогда, когда автоматически определяемый системой тип оказывается неверным.
С формированием DataFrame разобраться удалось. Теперь необходимо выяснить, как добавлять в него столбцы.
Работа со столбцами
В контексте данных строка – это утверждение или точка информации. Столбцы будут отражать свойства или атрибуты имеющихся утверждений. Простым языком: каждая строчка – это дом. Столбцы будут заключать в себе сведения о строении:
- год постройки;
- стоимость;
- количество комнат;
- сколько санузлов и спален на территории;
- количество этажей и так далее.
Добавление и удаление столбцов – базовые операции при проведении анализа данных. Далее будут представлены существующие способы обеспечения новых столбцов в DataFrame Pandas.
Сначала необходимо создать «базу» — фрейм информации, который будет использоваться в предложенных примерах. Это поможет сделать следующий фрагмент кода:

Если запросить вывод результата, на экране появится следующая надпись:

Все предлагаемые далее примеры будут опираться на соответствующих исходный материал.
Простой подход
Вот пример элементарного пути создания нового столбца в DataFrame:
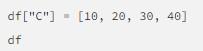
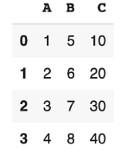
Здесь предстоит запомнить следующее:
- Названия столбцов указываются подобному тому, как происходит его выбор во фрейме.
- После этого соответствующему массиву присваиваются значения.
- Новый столбец DataFrame выводится последним. Он получает самый высокий индекс.
Данный прием позволяет добавить сразу несколько элементов в таблицу. Тогда названия (наименования) необходимо перечислить списком. Значения будут дверными. Это необходимо для совместимости с количеством строк и непосредственными столбцами.
Вот – наглядный пример добавления трех колонок в уже имеющуюся таблицу Пандас, заполненных случайными числами в пределах от 0 до 10:

Если вывести результат на терминал/экран, получится следующая ситуация:
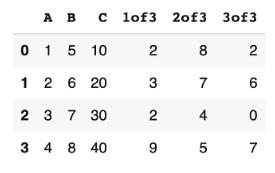
А вот эта запись удаляет колонки из заданного массива:
Df.drop ([“1of3”, “2of3”, “3of3”], axis = 1, inplace = true)
Соответствующий фрагмент кода позволит избавиться от элементов, которые ранее решили добавить в исходный пример.
По индексу
Pandas позволит вставить новую колонку в таблицу по заданному индексу. Для настройки расположения необходимо активировать функцию вставки – insert.

Этот фрагмент кода добавляет одну колонку около A. На экране появится таблица следующего типа:

При использовании функций insert необходимо указать три параметра:
- индекс;
- названия колонок;
- значения, которые требуется присвоить.
Индексные параметры начинаются с 0, поэтому в предложенном примере стоит 1.
Метки
Еще один подход – это добавление колонок при помощи меток. За данный прием отвечает функция as loc:

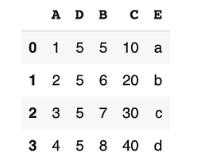
Для выбора строк и колонок необходимо указать те или иные метки. Чтобы выбрать все строчки, потребуется поставить двоеточие. Там, где необходимо вставить колонку, указываются метки элементов, которые выбираются. Столбца E в этой таблице Pandas нет. Это приводит к формированию новой колонки.
Специальная функция
Вставить в таблицу DataFrame новую колонку поможет специальная функция. Она называется assign. Реализация выглядит так:
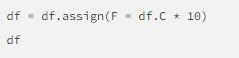
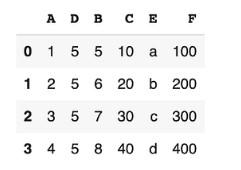
В функции assign указываются:
- имена колонок;
- какие значения присвоить.
Значения будут получены путем использования другой колонки во фрейме. Подобный прием поддерживается и предыдущими концепциями.
Assign и Insert – разница
Рассматривая вставку колонок в таблицы Пандас, можно пользоваться двумя схожими функциями – assign и insert. Они выполняют одну и ту же операцию, но принцип их реализации значительно отличается друг от друга:
- Функция вставки (insert) будет работать на месте. Это значит, что все изменения (включая добавление новой колонки) сохранятся во фрейме.
- Функция назначения (assign) реализовывается иначе. Она будет возвращать измененный фрейм. Исходный объект остается в своем первоначальном виде.
При работе с insert изменения будут отображаться на устройстве при обработке имеющегося фрагмента кода по умолчанию. В случае с assign для этого предстоит сначала явно назначить скорректированную таблицу.
Удаление
Отдельно стоит рассмотреть удаление колонок. Для этого в Pandas предусматривается метод drop(). Колонки в нем стираются путем удаления элементов с указанными названиями (именами).

Вот – фрагмент кода, который позволит избавиться от колонок. При выводе результата на экран будет видно, что пропущенных пространств нет. Соответствующий значения будут отбрасываться. Связано это с тем, что ось устанавливается на 1. Все изменения проведены в исходном фрейме, из-за того, что inplace = True.
Вот так выглядел DataFrame до удаления компонентов:
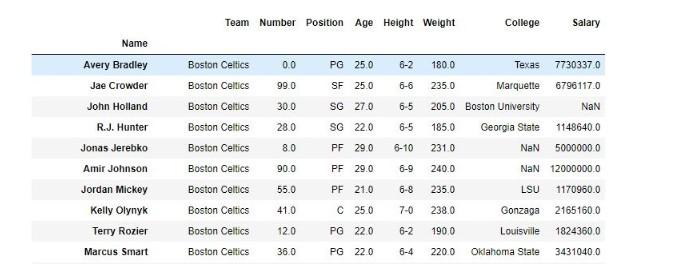
А вот такой вид он приобрел после обработки заданного кода:
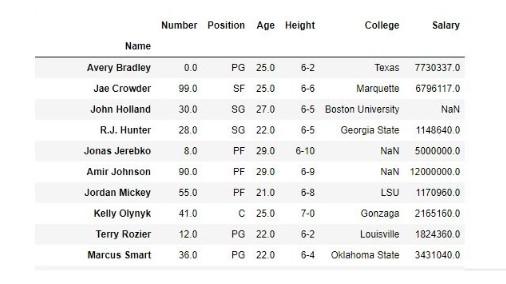
Есть еще одна элементарная операция, с которой должен быть знаком каждый разработчик Python, использующий модуль Pandas.
Выбор
Последнее рассматриваемое действие с DataFrame – это выбор. Доступ к столбцам может быть получен путем их вызова по присвоенным именам:

При обработке кода DataFrame на экране появится такая таблица:
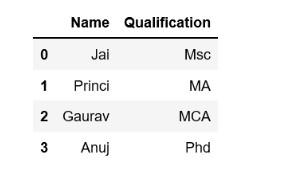
Ее первоначальный вид задан так:
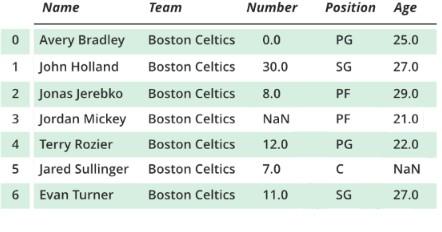
Все представленные операции являются базовыми. Они позволяют работать не только с DataFrame, но и с Series. Использование соответствующих структур будет совпадать.
Быстрое изучение
Чтобы лучше разобраться с Pandas, а также научиться выполнять операции с различными структурными единицами, рекомендуется закончить специализированные компьютерные дистанционные курсы.
На них пользователей научат работать с Pandas и его встроенными возможностями. Можно выбрать сразу одно или несколько направлений по Python, если этого хочет ученик. Все занятия организовываются дистанционно, а пропущенные уроки доступны для просмотра в записи.
На протяжении всего обучения гарантируется кураторство опытными специалистами, интересная практика, а также домашние задания. В конце будет выдан электронный сертификат, подтверждающий полученные знания по выбранному направлению.
Интересуют курсы по системному анализу и не только? Огромный выбор обучающих онлайн-программ по востребованным IT-направлениям есть в Otus!




