
Одним из наиболее популярных инструментов для системного анализа данных является Pandas. Давайте рассмотрим, какими особенностями обладает данная библиотека, для чего и как используется. Предложенная информацию будет полезна не только новичкам, но и опытным специалистам.
Описание
Pandas – программная библиотека, написанная на Python. Она используется для обработки и анализа данных. Работа здесь строится поверх library NumPy.
Если говорить простыми словами, Pandas – это как Excel, но мощнее. Здесь программист сможет работать с данными, объемом в тысячи и даже миллионы строк. Pandas предоставляет высокопроизводительные структуры информации, а также инструменты для их анализа.
Ключевые функции
Pandas широко используется в разработке. Она обеспечивает простоту в рамках среды Python. Используется для:
- сбора и очистки данных;
- задач, связанных с анализом информации;
- моделирования данных без переключения на специфичные для стартовой обработки языки (пример – Octave или R).
Библиотека предназначается для очистки, а также первичной оценки данных по общим показателям. Пример – среднее значение, квантили и так далее.
Pandas – это не статистический пакет, но его наборы информации применяются в виде входных в большинстве модулей анализа данных, а также при машинном обучении.
Для чего нужен проект
Pandas – это ключевая библиотека Питона, необходимая для работы с электронными материалами. Активно используется специалистами по BigDatas. Часто применяется для следующих задач:
- Аналитика. Инструмент позволяет подготовить datas к дальнейшему использованию. Он удаляет или заполняет пропуски, проводит сортировку или вносит необходимые изменения. Обычно большую часть соответствующих процессов удается автоматизировать через изучаемый проект.
- Data Science. Используется для подготовки и первичного анализа имеющихся сведений. Это необходимо для машинного/глубокого обучения.
- Статистика. В изучаемом проекте поддерживаются ключевые статистические методы. Они позволяют работать с информацией в электронном виде максимально эффективно и быстро. Пример – расчет средних значений.
Инструмент используется не только для обработки информации, но и для ее визуализации. Легко осваивается как опытными разработчиками, так и новичками.
Историческая справка
Рассматриваемый инструмент начал разрабатываться Уэсом Маккини, работающем в AQR Capital Management, в 2008 году. Он смог убедить работодателя перед увольнением разрешить опубликовать исходный код библиотеки. Так она получила открытость и свободную лицензию.
Позже, в 2012 году, к поддержке и совершенствованию продукта присоединился еще один сотрудник AQR – Чан Шэ. Он стал вторым главным разработчиком проекта. Примерно в этот момент Пандас стала набирать популярность в Python. Теперь соответствующий инструмент активно совершенствуется и дорабатывается свободными разработчиками.
Ключевые возможности
Рассматриваемый продукт для Питона обладает мощным функционалом. Он поддерживает следующие возможности:
- объекты data frame для управления индексированными массивами двумерной информации;
- встроенные средства совмещения данных, а также способы обработки сопутствующих сведений;
- инструменты, необходимые для обмена электронными материалами между структурами памяти, а также всевозможными файлами и документами;
- срезы по значениям индексов;
- расширенные возможности при индексировании;
- наличие выборки из больших объемов наборов информации;
- вставка, а также удаление столбцов в массиве;
- встроенные средства совмещения информации;
- обработка отсутствующих сведений;
- слияние и объединение имеющихся информационных наборов;
- иерархическое индексирование, при помощи которой удается обрабатывать материалы высокой размерности в структурах с меньшей размерностью;
- группировка, позволяющая выполнять трехэтапные операции типа «разделение, изменение и объединение» одновременно.
Проект поддерживает временные ряды. Он позволяет формировать временные периоды, изменять интервалы и так далее. Изначально создавался для обеспечения высокой производительности. Наиболее важные его части сформированы на C и Cython.
Начало работы
Pandas – функциональный и удобный проект для обработки данных. Далее предстоит разобраться с основами работы с ним. Для машинного обучения часто используются специальные библиотеки – Google Colab и Jupyter Notebook. Такие названия получили специализированные IDE. Они дают возможность работать с данными итеративно и пошагово. При их применении не требуется писать полноценное программное обеспечение.
Рекомендуется сначала установить IDE. В них Pandas встроен по умолчанию – ничего и никуда инициализировать не придется. Остается лишь произвести импорт в исходный код.
Если не использовать специализированные среды, разработчику потребуется Python выше версии 2.7. Импортирование Пандас происходит при помощи такой команды:
или
, где pd – это официальное сокращение Pandas.
При использовании PIP необходимо воспользоваться следующей командой:

Для импорта PD и NumPy в Python-скрипт потребуется добавить такой блок кода:
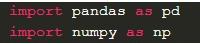
Связано это с тем, что PD зависит от NumPy. Соответствующая зависимость тоже должна быть импортирована в исходный код приложения. Теперь все готово к полноценному применению модуля при разработке программных продуктов разной сложности.
Структуры данных
Изучаемый модуль поддерживает несколько информационных структур:
- Series. Выражается одномерным массивом неизменного размера. Напоминает структуру с однородными данными.
- DataFrames. Двумерная табличная структуру. Поддерживает изменение размера. Столбцы в ней будут неоднородно типизированными.
- Panel. Трехмерный массив, который может меняться в размерах.
Других вариантов у PD нет. Далее первые две структурные единицы будут изучены более подробно. Они используются в программных кодах чаще всего.
Класс Series
Series – объект, который напоминает одномерный массив. Может включать в себя любые типы данных. Часто представлен в виде столбца таблицы с последовательностями тех или иных значений. Каждый из них будет наделен индексом – номером строки.

При обработке соответствующего кода на экране появится такая запись:

Series будет отображаться в виде таблицы с индексами компонентов. Соответствующая информация выводится в первом столбце. Второй отводится непосредственно под заданные значения.
Data Frame
DataFrame – это таблица с разными типами столбцов. Представляет собой двумерную информационную структуру. Является основным типом информации в Pandas. Вокруг DataFrame строится вся дальнейшая работа.
Соответствующий объект может быть представлен обычной таблицей (подобной той, что встречается в Excel), с любым количеством не только строк, но и столбцов. Внутри ее ячеек содержатся самые разные сведения:
- числовые;
- булевы;
- строковые и так далее.
DataFrame имеет индексы не только столбцов, но и строк. За счет подобной особенности удается сортировать и фильтровать сведения и находить нужные значения быстро и максимально комфортно.
В DataFrame поддерживается жесткое кодирование, а также импорт:
- CSV;
- TSV;
- Excel-документов;
- SQL-таблиц.
Для создания соответствующего компонента допускается использование команды:

Здесь:
- data – это создание объекта из входных сведений (NumPy, series, dict и им подобные);
- index – строковые метки;
- columns – создание подписей столбцов;
- dtype – ссылка на тип сведений, содержащихся в каждом столбце (этот параметр не является обязательным);
- copy – копирование сведений, если они предусмотрены изначально.
Создание DataFrame может производиться различными способами. Пример – формирование объекта из словаря или их списков, кортежей, файла Excel.
Вот пример кода, использующего список словарей для создания DataFrame:
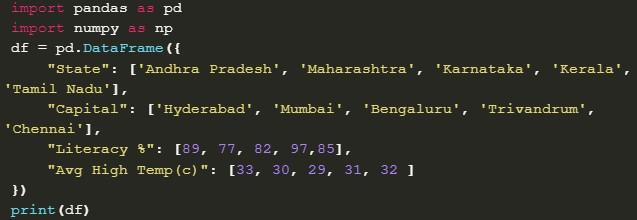
При обработке предложенного фрагмента система выведен на терминал/экран устройства следующую информацию:
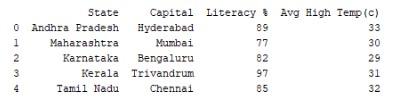
Работает код достаточно просто: сначала создается словарь, а затем в него передается в качестве аргумента метод DataFrame(). После получения тех или иных значений система выводит объект на печать в терминале.
Индекс здесь будет отображаться в самом первом левом столбце. Он имеет метки строк. Заголовки и электронные материалы – это сама таблица. При помощи настройки индексных параметров удается создавать индексированные DataFrames.
Импорт CSV
При создании DataFrame можно воспользоваться импортом файла CSV. Так называется текстовый документ. В нем запись материалов и значений ведется в каждой строке, разделяясь символом запятой.
Pandas поддерживает метод read_csv. С его помощью удается считывать содержимое CSV. Соответствующая команда поддерживает несколько параметров управления импортом:
- Sep. Он позволяет явно указывать разделители, используемые при выгрузке материалов. По умолчанию это символ запятой. Данный параметр является полезным при нестандартных разделителях в исходном документе. Пример – когда там применяются точки с запятыми или табуляция.
- Dtype. При помощи этой характеристики удается явно указывать тип, используемый в столбцах. Применяется, когда автоматически определяемый формат оказывается неверным. Пример – если дата импортируется в качестве строковой переменной.
А вот фрагмент кода, позволяющий импортировать сведения о скорости мобильного и стационарного интернета в разных странах. Здесь необходимо скачать исходный документ. После этого останется указать метод:

Чтобы увидеть DataFrame, останется вывести его на печать:

При работе в Jupiter Notebook и Google Collab для вывода DataFrame, а также Series, необходимо использовать команду print. Без нее модуль тоже сможет показать интересующие сведения. При написании print(df) будет потеряна табличная верстка.

В верхней части – названия столбцов, а слева указываются индексы. В нижней части выводится детализация о количестве столбцов и строк.
Полностью выводить табличку не обязательно. Для первого знакомства достаточно первых или последних пяти строчек. Чтобы воспользоваться соответствующими операциями, рекомендуется использование df.head() или df.tail() соответственно. В скобках указывается, сколько строчек выводить на экран. Этот параметр в Pandas по умолчанию равен 5.
Здесь можно увидеть больше информации об изученном модуле. А лучше программировать с его применением в Python помогут специализированные дистанционные компьютерные курсы.
Интересуют курсы по системному анализу и не только? Огромный выбор обучающих онлайн-программ по востребованным IT-направлениям есть в Otus!




