
Статистика и математика – научные области, которые пригодятся каждому разработчику. Они позволяют не только мыслить логически, но и решать огромное количество бизнес-задач.
В данной статье будет рассказано о линейных регрессиях. Они достаточно часто встречаются в эконометрике. Познания в соответствующей области помогут разобраться в наиболее вероятных характеристиках факторов, а также случайных ошибок модели.
Определение
Линейная регрессия – это используемая в статистике регрессионная модель одной переменной y от другой или нескольких иных переменных x с линейной функцией зависимости.
Регрессионные модели понять не слишком трудно, если стараться разобраться в направлении поэтапно. Сначала рассмотрим две непрерывные функции (переменные):
- x = (x1, x2, x3,…,xn);
- y = (y1, y2, y3,…,yn.).
Нужно разместить соответствующие точки на двумерной графике рассеяния. Это поможет получить линейное соотношение. Такое наблюдается, если данные аппроксимируются прямой линией.
Если y зависит от x, а корректировки в y вызваны изменениями в x, удастся определить линию регрессии (такой вариант носит название регрессии y на x), которая лучшим образом опишет прямолинейное соотношение между этими двумя переменными.
Классическая регрессия – это способ выбора из семейства функций той, что минимизирует функцию потерь. Последняя будет подчеркивать степень отклонения пробной функции от заданных в точках значений.
Возможные допущения
Классическая модель линейной регрессии представлена зависимостью одной величины от другой. Самый простой ее вариант предусматривает следующие условия:
- имеющиеся значения зависимой переменной будут определяться безошибочно;
- модель обладает всего двумя параметрами – они предварительно задаются;
- ошибки распределения стремятся к нулю, обладают постоянным отклонением;
- значения имеющихся параметров не могут быть заранее известны – их удается подобрать.
Параметры могут выбирать вручную. Для этого чаще всего используют специализированное программное обеспечение. Но есть и формулы, помогающие произвести необходимые расчеты вручную.
Особенности вычислений
Классическая модель регрессионного характера несет в себе ту или иную функцию. Если соответствующая запись выступает линейной, то и регрессия будет аналогичной. Ее вычисление заключается в том, чтобы подобрать выборку вследствие проведения анализа вычислений, данные в которой отвечают определенным требованиям.
К соответствующим критериям относят следующие моменты:
- адекватность результатов;
- статистические гипотезы в параметрах модели;
- оптимальные точечные и интервальные оценки.
Эти моменты необходимо учитывать при проведении тех или иных расчетов. Но перед тем, как углубляться в соответствующий вопрос, рекомендуется рассмотреть иные важные моменты изучаемой модели.
Регрессионная линия
Математическое уравнение, которое будет оценивать линию простой (парной) линейной регрессии будет иметь форму представления: Y = a+bx, где:
- x – независимая переменная (предиктор);
- Y – зависимая переменная (отклика);
- a – свободный член линии оценки (своеобразное пересечение, значение Y при x = 0);
- b – градиент оцененной линии (угловой коэффициент), величина, на которую в среднем происходит увеличение Y при «росте» x на единицу.
Стоит обратить внимание на то, что a и b – это коэффициенты регрессии оцененной линии. Но чаще всего соответствующее понятие используется только для b (углового коэффициента).
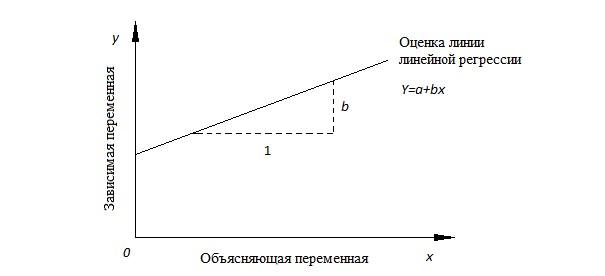
Выше – пример того, какой вид имеет линейная регрессия. Ее можно расширить за счет включения в функции очередных независимых переменных. Такая ситуация имеет несколько иное название. Регрессия окажется множественной.
Метод наименьших квадратов
Для того, чтобы определить коэффициенты a и b, можно использовать специализированные программы и приложения. Но математики и статисты должны уметь обходиться самостоятельными расчетами.
Для того, чтобы добиться желаемого результата, можно использовать выборку наблюдений, где a и b – это выборочные оценки генеральных параметров α и β. Они определяют линию регрессионного компонента в совокупности. Этот прием имеет название «метод наименьших квадратов» или МНК.
Подборка оценивается, рассматривая остатки. То есть, вертикальное расстояние каждой точки от линии. Лучшая подгонка – это та, в которой сумма квадратов остатков оказывается минимальной.

Выше – пример соответствующих расчетов. Он поможет лучше понять принцип работы метода наименьших квадратов.
Несколько слов о предположениях
Linear model регрес сии предусматривает, что для каждой рассматриваемой величины x остаток будет равняться y и предсказанного Y. Каждый из них бывает как положительным, так и отрицательным.
Остатки используют для того, чтобы проверить некоторые предложения. Они заложены в основе рассматриваемой регрессионной единицы:
- Между x и y есть соотношение линейного характера. Для любых пар (x;y) информация должна аппроксимировать прямую линию. Если перенести остатки на график двумерного типа, точки должны распределяться случайно. Никаких систематических картин здесь не будет.
- Остатки нормально распределяются с нулевым средним значением.
- У остатков наблюдается постоянная дисперсия относительно всех предсказанных величин y. При нанесении остатков против предсказанных Y от y вид «графика» укажет на случайное рассеяние точек. Соответствующее допущение невозможно, если с увеличением Y график рассеяния будет увеличиваться/уменьшаться.
Если «гипотезы» сомнительны, можно преобразовать x или y, затем рассчитать новую регрессию. Так, чтобы соответствующие допущения были удовлетворены. Пример – логарифмические преобразования.
О выбросах и точках влияния
«Влиятельное» наблюдение, если оно пропущено, корректирует оценки параметров модели (угловых коэффициентов, свободных членов). Выброс (наблюдение, противоречащее большей части значений в имеющемся наборе информации) бывает «влиятельным» наблюдением, может обнаруживаться без проблем визуально. Это возможно при построении двумерной диаграммы рассеяния или так называемого графика остатков.
Для выбросов и «влиятельных» наблюдений (точек) необходимо использовать вид модели с их включением и без них. Обратить внимание придется на изменение оценок (регрессионных коэффициентов).
Когда проводится анализ, не рекомендуется отбрасывать выбросы и точки влияния сразу. Подобная ситуация может исказить полученные итоговые результаты. Сначала необходимо выяснить, откуда появились соответствующие выбросы. Далее – проанализировать их.
Гипотеза
При работе с линейной регрессией нужно провести проверку нулевой гипотезы. Она заключается в том, что генеральный угловой коэффициент линии регрессии β = 0. Если угловой коэффициент линии равен нулю, то между x и y отсутствует линейное соотношение. Это значит, что изменения в x никак не отражаются на y.
Для того, чтобы проверить нулевую гипотезу, нужно использовать такой алгоритм:
- Вычистить статистику критерия. Это – b|SE(b). Она будет подчиняться t-распределению с (n-2) степенями свободы.
- SE(b) – это стандартная ошибка коэффициента под названием b.
- Воспользоваться формулами:
.
Если значимость P< 0,005, целесообразно говорить о том, что нулевая гипотеза отклоняется. Можно провести расчеты 95% доверительного интервала для генерального углового коэффициента β. Он будет равен: b±t0,05SE(b), где t0,05 – это процентная точка t-распределения со степенью свободы равной (n-2). Это дает вероятность двустороннего критерия 0,05. Полученный интервал несет в себе генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок (больше или равно 100) можно аппроксимировать t0,05 значением 1,96. Статистика критерия стремится к нормальному распределению.
Оценка качества
Если остаточная вариация имеющегося линейного соотношения как можно больше, то большая часть y объясняется регрессией. Точки здесь будут лежать близко к ее графику. То есть, линия хорошо соответствует имеющейся информации.
Коэффициент детерминации – это доля общей дисперсии y. Выражается процентным соотношением. Обозначение – R2. В парных регрессиях это – r2, называемый квадратом коэффициента корреляции). Он позволяет оценивать качество заданного уравнения субъективным методом.
Разность (100-R2) – это процент дисперсии. Он никак не объясняется через регрессию. Формального теста для оценивания R2 нет. Из-за этого приходится опираться на субъективные суждения, которые помогают определить качество подгонки регрессионных линий.
Здесь можно посмотреть, как грамотно использовать линейные «уравнения» рассмотренного типа для тех или иных задач. Наглядные примеры помогут понять, насколько соответствующий компонент важен в аналитике. А вот – видео-урок по линейным «зависимостям».
Секрет быстрого изучения
Для того, чтобы лучше понимать изученную тему, можно внимательно просмотреть статистику и математический анализ. Но лучше всего воспользоваться дистанционными специализированными онлайн курсами.
Там научат не только основам матанализа, но и непосредственной разработке программного обеспечения с нуля. Пользователи получают уникальную возможность приобретения навыков работы с графикой, анимацией, программными кодами и даже BigData. В конце будет выдан электронный сертификат, подтверждающий соответствующий спектр навыков и знаний.





