
Информация бывает разного вида: графическая, текстовая, знаковая. Для ее корректного отображения в компьютерах и другом оборудовании используются кодировки. Особую значимость они представляют для символьных и текстовых данных.
Сегодня предстоит выяснить, какие существуют кодировки символов, чем они отличаются, как и для чего используются. Эта информация будет полезна не только новым пользователям ПК, но и более опытным.
Кодирование – определение
Кодирование информации – это своеобразное преобразование информации из одной формы в другую. Такую, чтобы данные было удобно обрабатывать, хранить, а также передавать посредством некоторого кода.
Кодировка символов – процесс присвоения номеров графическим символам, в особенности элементам человеческого языка. Числовые значения, которые формируют кодировку, называются «кодовыми точками». В совокупности они представляют собой кодовое пространство или карту символов.
Для кодирования букв и алфавитов используются самые разные стандарты. Они могут отличаться в зависимости от языка или операционной системы. Наиболее популярные из них:
- ASCII («Аски»);
- ISO;
- KOI-8;
- CP866/CP1251;
- Unicode.
Далее все эти кодировки будут изучены более подробно. Наиболее распространенными из них выступают первый и последний пункты.
ASCII – с чего все начиналось
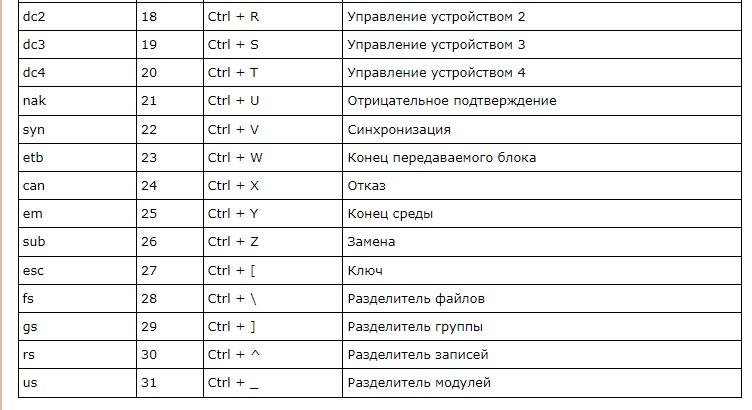
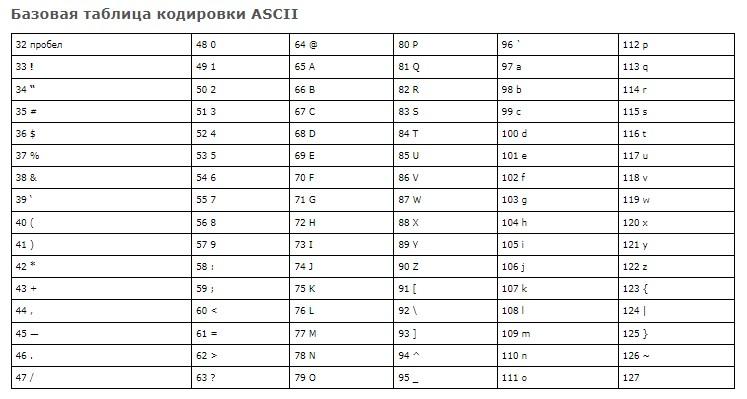
Первая группа кодировки – ASCII. Стандарт, который поддерживает английский алфавит (латиницу). Он включает в себя 128 уникальных символов, которые разделяются на:
- управляющие компоненты;
- печатные.

Соответствующий стандарт включает в себя:
- латинские буквы;
- арабские цифры;
- знаки препинания;
- служебные символы.
Первая ASCII с 7 битами была расширена до 8 битов (расширенная ASCII). В этом случае диапазон символов соответствует кодам от 0 до 255. Младшие биты (от 0 до 127) – это «классический» ASCII, старший отвечает за дополнительные 128 символов.
Стандарт ISO
ISO – это кодировка, которая представлена совокупностью 8-ми битных кодировок. В ней младшая половина – это ASCII, а старшая отвечает за символьное определение различных языков. Примеры ISO:
- 8859-0 – новые европейский стандарт;
- 8859-1 – Европа и Латинская Америка;
- 8859-5 – таблица кириллических символов;
- 8859-2 – Восточная Европа.
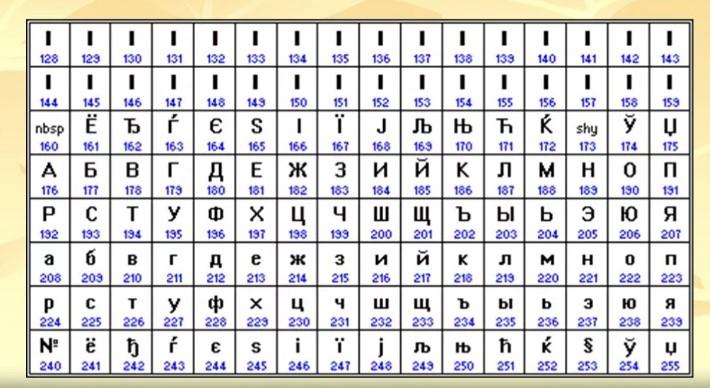
ISO 8859-5 – это одна из первых попыток введения кодировки для кириллицы. Данный стандарт до сих пор используется крупными компаниями, которые пишут программное обеспечение с поддержкой обработки кириллических символов. Их примеры: базы данных, решения OpenVMS.
CP866
Это – альтернативная кодировка от IBM. Здесь все специфические европейские элементы в верхней части таблицы были заменены на кириллицу. Псевдографические компоненты остались прежними. На общем виде программ такой подход никак не отражался.
CP866 до сих пор активно используется на практике. Он встречается в OS/2, а также в MS-DOS. На нем «шифруются» имена в файловых системах vfat и fat.
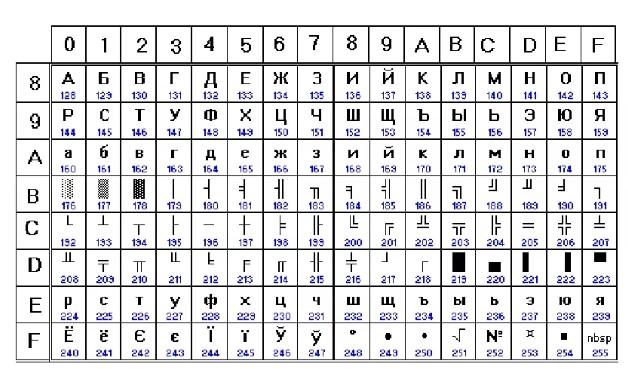
CP866 была создана в ВЦ АН СССР, для которого впервые были закуплены партии устройств IBM PC. Одним из авторов кодировки выступил некий Брябрин В.М., который написал собственную книгу «Программное обеспечение персональных ЭВМ».
Windows 1251
Windows 1251 – это «продукт», созданный компанией Microsoft. Его появление обусловлено популярностью развития графических операционных систем. Псевдографика для них стала ненужным элементом. Все это привело к появлению полноценной группы, которая по-прежнему считалась расширенной интерпретацией ASCII (где один символ теста будет закодирован всего одним байтом данных), но уже без символьной псевдографики.
Соответствующая группа относилась к так называемым ANSI-кодировкам. Они разрабатывались американским институтом стандартизации. Говоря простым языком, это кириллица для варианта с поддержкой русского алфавита. Наглядный пример – Windows 1251.

В нем нет псевдографики. Их место было отведено под недостающие:
- знаки русской типографии (за исключением ударения);
- славянские языки (украинский, белорусский и так далее).
В Windows 1251 нет совместимости с CP866. Если попытаться отобразить их между собой, на экране появится неточный текст сообщения, а бессмысленный знаковый набор (простыми словами – «кракозябры»).
Windows 1251 используется в семействе Windows. В основном встречается в операционных системах начала 90-х годов. Кириллица здесь отображается в алфавитном порядке.
KOI-8
Это достаточно старый стандарт. Он появился раньше CP866 и CP1251. Его разработчики разместили русскую кириллицу в верхней расширенной части ASCII так, чтобы позиции соответствовали их фонетическим аналогам в английском алфавите в нижней части таблицы. Это значит, что, если в тексте, написанном на KIO-8, убрать восьмой бит каждого элемента, на выходе получится читабельная информация, хоть и на английском.
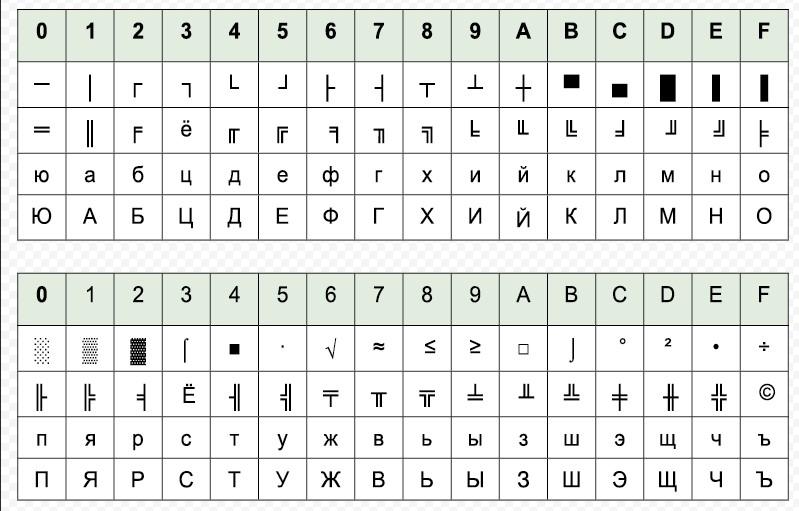
KOI-8 имеет несколько «диалектов». Он поддерживает:
- KOI8-R – для русского алфавита;
- KOI8-U – украинский.
В первом варианте также поддерживается Болгарская кириллица. С ее помощью были сформированы первые кириллизации для компьютеров. Сейчас в Болгарии активно используется Windows 1251.
КОИ8-R пользуется популярностью в интернете. Это фактический стандарт для русской кириллицы в Internet.
Unicode
Таблицы Unicode – консорциум, который выступает в качестве универсальной кодировки. Он появился из-за того, что языковые группы юго-восточной Азии невозможно уместить в одном байте информации, выделяемом для «шифрования» одного элемента в «Аски». Он имеет несколько вариантов представления:
- UTF-32;
- UTF-16;
- UTF-8.
Это – частичная реализация ISO. Сейчас в Юникоде распределены около 40 000 позиций из возможных 65 535 (это 2 байта на каждую букву). В 1998 году произошло последнее значительное изменение Unicode. Тогда была внедрена интерпретация знака «евро».
Отличительной чертой Юникода является то, что в нем позиции зарезервированы почти для всех существующих алфавитов, включая иероглифы, которыми пользовались в Древнем Египте. При помощи соответствующего вида «шифрования» допускается одновременная работа с русским и греческим, сочетая вставки на японском/китайском/азербайджанском, путем использования одного шрифта.
UTF-32
Первый вариант Unicode. Цифра в названии указывает на количество бит, используемое для кодирования одного элемента текста. 32 бита – это 4 байта данных. Столько потребуется при печати одного текстового компонента в UTF-32.
Это привело к тому, что исходный документ, переведенный из ASCII в Юникод стал весить в 4 раза больше. Такие изменения оказались неоправданными – большинству европейским стран огромное количество знаков не требовалось. Это привело к совершенствованию стандарта.
UTF-16
UTF-16 – более удобный вариант Unicode. По умолчанию именно такой вариант используется для всех элементов, используемых на компьютерах. Два байта требуются для «шифрования» одного символьного компонента.
При помощи 16 бит закодировать можно 65 536 элементов. Это – базовое пространство Unicode. Несмотря на свои преимущества, UTF-16 не принесло удовлетворения разработчикам. Особенно тем, кто писал исключительно на английском. Связано это с тем, что исходный документ у них увеличивался в 2 раза.
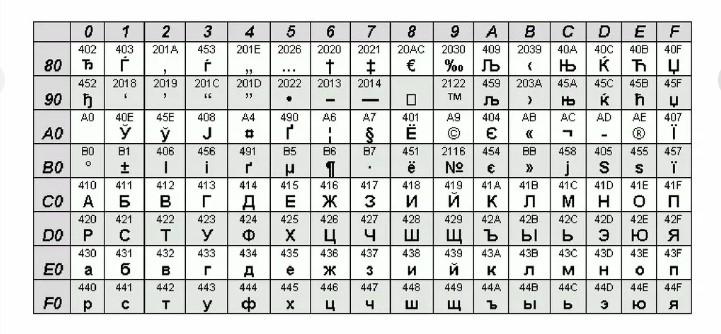
Чтобы посмотреть таблицы Unicode UTF-16 в Виндовс потребуется:
- Перейти в меню «Пуск».
- Зайти в «Программы»–«Стандартные»–«Служебные».
- Выбрать в появившемся меню «Таблица…».
- В дополнительных параметрах установить Unicode.
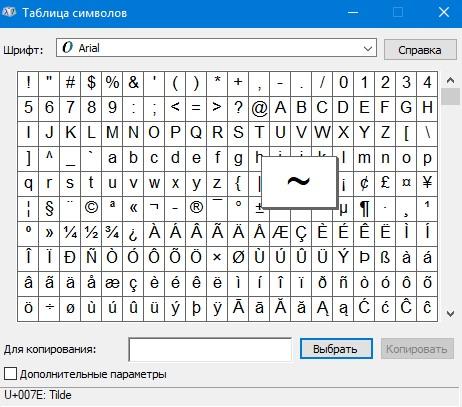
Выше – пример того, как будет выглядеть символьное отображение элемента текста и его код. Эта информация отображена в правом нижнем углу (U+007E).
UTF-8
Так называется Юникод с переменной длинной. Несмотря на восьмерку в своем названии, она все равно имеет неоднозначную длину. Каждый текстовый компонент может быть закодирован здесь в последовательность от 1 до 6 байт.
Практическое применение нашли первые 4 байта. Все, что расположено за их пределами, трудно представить. Латинские знаки в ней преобразовываются при помощи 1 байта.
Программы и приложения, которые не понимают Unicode, поддерживают отображение того, что закодировано через UTF-8. Связано это с тем, что соответствующий стандарт поддерживает базовую часть «Аски».
Кириллические компоненты в UTF-8 кодируются в 2 байта, грузинские и некоторые другие – в три.
Непонятный текст вместо русских букв – исправление
Самая распространенная ситуация при работе с текстовыми данными – это появление «кракозябр» вместо русского языка. Связано это с неправильным кодированием информации.
Чтобы редактировать текстовые документы, рекомендуется использовать Notepad++. Он позволяет программировать на различных языках разработки, а также поддерживает расширяемость через плагины.
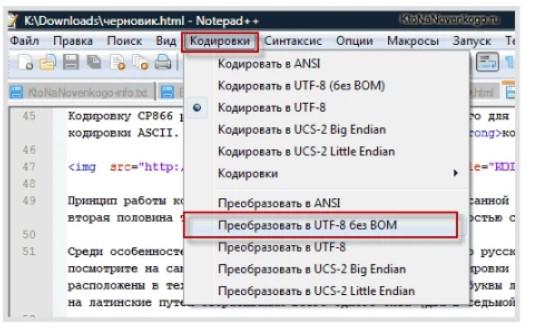
В Notepad++ имеется пункт «Кодирование». Там можно выбрать способ «шифрования» по умолчанию, а также воспользоваться преобразованием. Рекомендуется останавливаться на таблице UTF-8 без BOM. В этом случае в начало документа не вставляются три дополнительных байта.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!




