
Python – это один из наиболее популярных в 21 веке языков. Он применяется в самых разных областях: от веб-программирования до создания сложных систем управления оборудованием.
В процессе разработки программного обеспечения приходится много работать со строками, а также символами, использовать кодировки. На первых порах данный процесс может показаться сложным. Представленная далее информация позволит разобраться с The Unicode в Питоне, научит переводить символы в UTF-8.
Python – особенности
The Python – высокоуровневый язык, обладающим общим назначением. Он имеет строгую динамическую типизацию, а также автоматическое управление памятью. Ориентирован на производительность программиста, повышение читаемости и качества исходного кода. Обеспечивает высокий уровень переносимости приложений.
The Python – это объектно-ориентированный язык. Перед изучением особенностей кодировки и работы со строками, необходимо понимать, с каким ЯП предстоит иметь дело. Питон интерпретируемый, имеет минималистичный синтаксис ядра.
Используется при:
- веб-разработке;
- создании бизнес-приложений;
- мобильной разработке;
- программировании основных программ для операционных систем (на компьютерах).
В игровой индустрии он выступает в качестве своеобразного дополнения. Небольшие проекты на нем запустить можно, крупные – проблематично из-за особенностей языка.
Преимущества
Прежде чем писать код to the Python, необходимо рассмотреть его преимущества и недостатки. Эта информация пригодится при работе со строками и кодировкой.
К преимуществам относят:
- простой и понятный синтаксис;
- высокую читаемость исходного программного кода;
- большое количество встроенных инструментов;
- хорошую поддержку масштабируемости;
- дружелюбное сообщество – получить помощь по вопросам разработки удается очень быстро;
- внушительную коллекцию дополнений;
- интерпретируемость.
The Python с легкостью осваивается новичками в области разработки программного обеспечения. У него есть собственная система оповещения об ошибках, благодаря которой удается отлаживать the program. Найти место, в котором возник сбой, а также понять, почему поведение приложения некорректное, не составляет никакого труда.
Недостатки
The programming – процесс, успех которого во многом зависит от выбранного языка разработки. У Питона выделяются следующие недостатки:
- нерациональное распределение памяти устройства – потребляется больше положенного;
- медлительность – особо заметно на примере крупных проектов;
- строгую привязку к системным библиотекам.
Несмотря на свои недостатки, the Python ложится в основу to серверной части программного обеспечения. Им пользуются крупных компании вроде Google и Pinterest.
Терминология для разработчика
Изучать любой ЯП нужно, зная the terms в программировании. Вот ключевые понятия, помогающие разобраться в программном коде быстрее:
- Алгоритм – последовательность команд или их набор, предназначенные для выполнения задачи/достижения определенной цели.
- API – интерфейс прикладного программирования. Представлен правилами, процедурами и протоколами для создания приложений. Способствует более простой коммуникации to иными программами и службами.
- Аргумент – значение, передаваемое to the функцию.
- Символ – простейшая единица информации в коде. Выражается буквенной записью или одним символьным значением.
- Объект – связь переменных, а также констант и иных структур данных, которые могут быть выбраны и обработаны совместно.
- Класс – связанные объекты с общими свойствами. Обеспечивают гибкость разработки.
- Константа – значение, которое никогда не меняется. Оно сохраняется единым в процессе выполнения исходного кода.
- Тип данных – классификация информации определенного типа.
- Массив – список или группа схожих типов значений, сгруппированные заранее.
- Исключение – непредвиденное, аномальное поведение в процессе the working program.
- Фреймворк – готовый блок кода, используемый for the helping programmer. Используется разработчиком для решения схожих задач.
- Петля (цикл) – инструкции, которые повторяют одно и то же действие несколько раз. Происходит это до тех пор, пока условие не будет выполнено. Также возможно получение команды to stop.
- Итерация – один проход через данный набор операций/инструкций.
- Ключевое слово – слово или выражение, зарезервированное the language. Используются ключевые слова для обеспечения определенных функций, операций, алгоритмов.
- Оператор – the term, указываемый to the object, который умеет управлять различными операндами.
- Операнд – объект, которым удается манипулировать посредством специальных операторов.
- Переменная – именованная область для хранения the information в исходном коде. Простейшее место в памяти устройства, названное именем.
- Указатель – переменная, содержащая конкретный адрес in the memory. Своеобразное местоположение.
Все это – основная терминология, без запоминания и понимания которой изучение the Python и других ЯП станет проблематичным.
Unicode – это…
Unicode – стандарт кодирования символов. Он включает в себя практически все мировые письменные языки. Сейчас особо распространен в интернете. Он был заложен в 1991 году.
Состоит их двух частей:
- универсального символьного набора;
- семейства кодировок (UTF).
Универсальный символьный набор предоставляет to Unicode допустимые по стандарту символы, присваивает каждому из низ неотрицательное число. Соответствующие значения чаще всего записываются в шестнадцатеричной форме с префиксом U+. Семейство кодировок необходимо для определения способов преобразования кодов символов с целью последующей передачи в поток или to files.
Здесь стоит запомнить следующие особенности:
- в рамках стандарта предусматриваются более 138 000 различных символов;
- каждый символ обладает названием и кодом (так называемым номером);
- все коды включают в себя латинские буквы и шестнадцатеричные цифры.
В Unicode символы представлены кодовыми точками – целыми числами в диапазоне от 0 до 0x10FFF. Символы на экране выражаются при помощи глифов. Пример – для прописной «А» глиф – это два диагональных штриха и один горизонтальный. Детали напрямую зависят от используемого шрифта.
При работе с Питоном беспокоиться за определение правильного глифа не нужно – графический пользовательский интерфейс отлично справляется с этой задачей.
Кодировка
Unicode строка – это последовательность символов (кодовых точек), представляющих собой цифры и буквы (числовые значения от 0 to 0x10FFF). Она представляет в памяти устройства в виде набора кодовых единиц, которые отображаются в байты. Unicode использует для хранения символа 8-бит.
Кодировка – это преобразование строки Unicode to bytes (в байты). В Python используется UTF-8. Далее предстоит разобраться с ее особенностями, а также с непосредственным переводом in codes.
ASCII
ASCII (American standard code for information interchange) – это специальная таблица (кодировка, набор), включающая в себя распространенные печатные и непечатные символы. В ней происходит сопоставление записям их числовой интерпретации. ASCII появилась в 1963 году.
Данная таблица необходима для определения кодов символов:
- управляющих элементов;
- десятичных цифр;
- латинского и национальных алфавитов;
- знаков препинания.
Знать о работе ASCII нужно всем, кто в Python 3 планирует заниматься кодировкой. Данный элемент позволяет грамотно отображать на дисплее те или иные записи.
UTF-8 – определение
UTF-8 – наиболее используемая кодировка при разработке программного обеспечения в the Python. Это – формат преобразования Unicode. В соответствующей записи «8» указывает на то, что при кодировании применяются только 8-битные значения. Связано это с наличием кодировок UTF-16, а также UTF-32, которые используются в программировании реже.
При работе с UTF-8 необходимо запомнить следующие правила:
- если используемая кодовая точка меньше 128, она будет представлена соответствующим байтовым значением;
- если кодовая точка больше 128, происходит ее преобразование to последовательности двух, трех или четырех байтов, где каждый байт располагается между 128 и 255.
UTF-8 обладает следующими полезными свойствами:
- можно с ее помощью обработать любую кодовую точку Unicode;
- строка Unicode после преобразования может быть обработана функциями C, а также отправляться через протоколы;
- строчка текста ASCII – это допустимый текст UTF-8;
- компактность;
- при повреждении или утрате байтов поддерживается определение начала следующей кодовой точки с повторной синхронизацией.
UTF-8 представляет собой байтовую кодировку. Она указывает на то, что символ будет представлен определенной последовательностью из одного или нескольких байтов. За счет такой концепции удается избежать проблем с порядков следования.
Что нужно помнить перед кодировкой
Кодирование информации – процесс, требующий осторожности. Неграмотная реализация приводит или к ошибкам, или к некорректному отображению информации на экране, поэтому программисту необходимо запомнить следующее:
- Если происходит кодирование to bytes при помощи UTF-8, то перекодировать соответствующую строку из байт потребуется через эту же кодировку. Некоторые кодировки совместимы, но обычно их совместное применение приводит к утрате данных.
- При написании кодов рекомендуется использование Unicode. Это оптимальный вариант to UTF-8 из-за применения «по умолчанию» в основной массе функций и методов.
- Декодирование байтов строки лучше осуществлять после их получения, кодирование – непосредственно перед отправкой.
В программном коде рекомендуется работать с «обычными» типами данных – строками, числами и списками. Это связано с тем, что большая часть методов в Питоне не поддерживает использование байтовых строк, либо функционируют так, что предсказать вероятное поведение проблематично.
Строки и методы
В the Python 3 все символы, а также документы будут автоматически переводиться в UTF-8. Это позволяет свести вероятность некорректного отображения к нулю. Но в данной версии языка есть специальные строковые методы. Они не теряют своей актуальности. Связано это с тем, что программист сможет указывать разные необходимые кодировки to application.
Модуль string – это наиболее простой и удобный инструмент, разделяющий символы ASCII на группы с последующим преобразованием в строки-константы. Строки можно создавать при помощи метода decode из bytes.
Перед углубленным изучением имеющихся методов необходимо запомнить следующее:
- тип str в the Python 3.0 включает в себя символы Unicode;
- можно включить символ Юникода to строковый литерал за счет кодировки по умолчанию в виде UTF-8;
- допускается использование Unicode-символов в идентификаторах;
- если не получается ввести определенный символ или хочется сохранить его только в формате ASCII, допускается использование escape-последовательностей в строковых литералах.
Кодирование задается в виде строк, содержащих имена кодировок. Односимвольные Unicode-строки могут быть созданы через встроенную функцию chr. Она принимает целые числа, а затем возвращает to Unicode string = 1, содержащую соответствующую кодовую точку. Обратная функция – это ord. Она принимает строку Юникода и возвращает значение кодовой точки.
Основные методы
В the Python множество методов, поддерживающих работу с кодированием информации. Таблица ниже поможет ознакомиться с наиболее популярными из них:
| Название | Характеристика |
| Decode и incode | Методы, отвечающие за кодирование и декодирование строки в нужном формате. |
| ASCII | Функция, которая приводит string to ASCII. |
| Chr, ord | Взаимообратные операции. Первая демонстрирует Unicode-символ соответствующий to введенному числовому значению. Вторая вернет числовой аналог конкретной символьной записи. |
| Hex, bin, int, oct | Функции, позволяющие переводить числа to различные системы счисления. |
| Bytes | Работает так же, как и метод encode. Отличается расширенными возможностями. |
| Str | Перевод байтовых строк в обычные с использованием указанной ранее кодировки. |
| Unicodedata | Модуль, умеющий работать с базами данных всех Unicode-элементов. |
Особое внимание уделим encode и decode, а также изучим несколько наглядных примеров каждого предложенного в таблице метода.
Encode
Метод Encode() используется for the входных строк. Они имеются у каждого объекта. Позволяют закодировать информацию to заданный «формат».
Форма представления метода: input_string.encode (encoding, errors).
Соответствующая запись будет обрабатывать input.string при помощи encoding. Здесь errors отвечает за поведение, согласно которому необходимо действовать при невыполнении кодирования. Encode() приводит to byte-последовательности.

Результатом станет объект <class ‘bytes’>.
Тип кодирования, которому необходимо следовать при работе с кодом, задается при помощи параметра encoding.
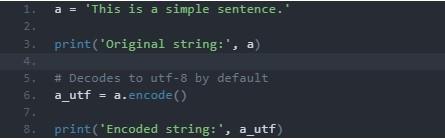
Результат обработки приведет to следующий результат:

Здесь входная строка была закодирована to UTF-8. Она имеет префикс b, указывающий на преобразование в поток байтов. Это сделано для удобства считывания.
Обработка ошибок
Обработка ошибок при работе с кодированием информации в Python – важный аспект, которому новички не уделяют должного внимания. Отвечает за поведение приложения при неудачном преобразовании имеющихся данных. За этот момент в the Python отвечает параметр errors.
| Тип ошибки | Как действовать |
| Strict | Параметр по умолчанию. Он вызывает UnicodeDecodeError. |
| Ignore | Игнорирование некодированного Юникода. |
| Replace | Необходим для того, чтобы изменить все некодируемые символы. Они будут приведены к вопросительному знаку (?) |
| Backslashreplace | Отвечает за вставку to escape-последовательность обратной собой черты. Она появляется вместо некодируемых элементов in the Unicode. |
Выше – таблица с наиболее распространенными значениями error. А вот элементарный пример кода. Он поможет изучить принципы работы с encode. Здесь во входной строке не все символы кодируются:


После обработки заданного кода на экране отобразится результат, показанный выше. Здесь предстоит перевести string to SCII с игнорированием некодируемого компонента.
При возникновении ошибки кодирования интерпретатор выведет на экран один из вариантов:
- UnicodeError – общее исключение;
- UnicodeDecodeError – появляется тогда, когда в кодировке отсутствует обрабатываемая кодовая позиция;
- UnicodeEncodeError – исключение, возникающее, когда обрабатываемый символ является незнакомым для заданной кодировки.
Все это поможет лучше усвоить работу encode и decode to the Python.
Декодирование
Для декодирования байтового потока in the Python используется функция decode(). Она работает по аналогии с encode, но в обратном порядке.
Формат записи: 
Этот фрагмент кода наглядно показывает принцип функционирования decode() в Питоне:
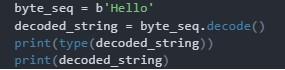
При обработке соответствующего запроса произойдет вывод на дисплей следующей записи:
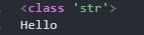
Параметр decoding отвечает за определение типа кодирования, из которого производится декодирование байтовой последовательности. Параметр errors указывает на поведение при сбоях. Здесь используются те же методы, что и в encode.
Литералы в строках Python
Использование конструктора str() – не единственный вариант использования текстовых данных в программном коде. Иногда объект соответствующего типа вводится напрямую:

В приложении, написанном на Питоне, при помощи Unicode можно напечатать символы, отсутствующие на клавиатуре. Они копируются и вставляются непосредственно в оболочку интерпретатора.

Выше – наглядный пример того, как это выглядит в коде. Один литерал может быть записан при помощи Unicode в the Python несколькими способами: сочетаниями клавиш или прямым вводом необходимого элемента в нужном месте.

Выше – таблица, показывающая все способы задания символьных записей через экранирующие последовательности.
Наглядные примеры
Ранее было сказано о методах работы со строками в Python. Далее будут рассмотрены примеры для каждого случая.

Это – способ перевода заданного текстового значения str to ASCII. Экранирование русского слова связывается с отсутствием для него стандартного знакового набора в ASCII. У него нет 1-байтового представления.
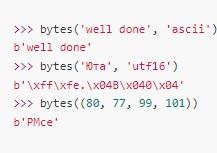
А вот – метод bytes. Он будет преобразовывать в одноименный объект не только строки и числа, но и последовательности числовых знаний. В них каждый элемент – это тот или иной символ.

Это – наглядный пример использования встроенного модуля Unicodedata. Он позволяет уточнить имя любого Юникод-символа, а затем отобразить его по имени.
Регулярные выражения
Регулярные выражения, которые поддерживаются модулем re, могут быть приведены to bytes или strings. Часть последовательностей специальных символов (\d или \w) обладают разными значениями. Они меняются в зависимости от формы представления шаблона – байтами или строками. Пример – \d соответствует категории символов в диапазоне от 0 to 9 включительно, но в строках – любому символьному значению, находящемуся в пределах категории Nd.

Выше – пример работы с числом 57. Оно будет записано арабскими и тайскими цифрами. При запуске \d+ сопоставит тайские цифры и выведет их на печать. Если ранее был указан флаг re.ASCII для compile(), \d+ получит соответствие подстроке «57».
С основами кодирования разобраться удалось. Этот видео-урок поможет новичкам быстрее разобраться в соответствующей теме. Теперь изучим несколько принципов работы со строками в Питоне, которые могут пригодиться разработчику.
Сворачивание регистра
Сворачивание регистра – способ унификации текста в любой форме представления к каноничной. Пример – приведение всей строки to нижний регистр. Над текстов будут проведены некоторые дополнительные преобразования. В Python 3.3 есть метод str.casefold, который помогает работать со сворачиванием регистра. Если обрабатываемый текст содержит исключительно символы из кодировки latin1, результат его применения окажется точно таким же, как и в случае с str.lower().

Здесь метод не просто привес текст к нижнему регистру, но и использовал преобразование для специфического символа из немецкого алфавита.
Нормализация
Нормализация – приведение имеющегося текста к единому представлению на дисплее устройства.

Внешне данные записи выглядят идентично. Если попытаться перевести имена соответствующих символов подобно интерпретатору the Python, результат окажется нестандартным.
В Питоне имеется встроенный модуль, содержащий сведения о символьных значениях Unicode, их имена, являются ли они цифрами и так далее. Методы по типу str.isdigit будут брать информацию именно из соответствующей «базы». Речь идет о Unicodedata, рассмотренном ранее.

При обработке данного фрагмента произойдет вывод следующего результата:
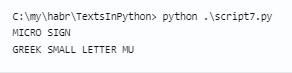
Здесь интерпретатор рассматривает введенные значения в качестве двух разных, несмотря на их одинаковое графическое отображение to Unicode. Символьные значение подобной формы носят название канонических эквивалентов. Приложения их считывают одинаково, а интерпретаторы – нет.
Нормализация реализована через функцию unicodedata.normalize. Первый аргумент – это форма нормализации. Она определяет, эквивалентны ли две строки Unicode по отношению друг к другу. Всего существуют 4 формы представления:
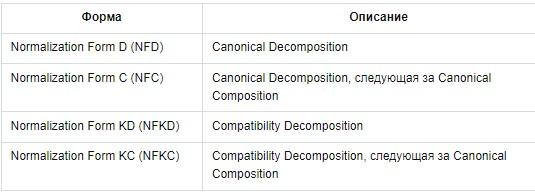
Здесь каждый вариант изучен более подробно. Алгоритмы нормализации пригодятся при поиске валидных документов или непосредственного индексирования текста.
Как лучше разобраться с кодированием
Кодирование информации, а также работа с Unicode и UTF-8 в Python новичкам кажется сложной задачей, особенно если предстоит использование больших объемов данных. В Сети полно полезных сведений, литературы, уроков и упражнений по рассмотренному в статье направлению. Но разобраться в них бывает достаточно проблематично.
Чтобы encode, decode и другие методы Питона не доставляли хлопот, рекомендуется закончить компьютерные онлайн курсы. Пример – от образовательного центра OTUS. Все занятия здесь проводятся в виде вебинаров, посмотреть их можно в любое время.
Преимущества дистанционных курсов:
- быстрое обучение основам выбранного языка и обучение кодированию информации с нуля;
- сжатые сроки – до 12 месяцев;
- постоянное кураторство опытными специалистами и интересные домашние задания;
- совместимость с обыденной жизнью – такая форма обучения подходит даже при наличии полноценного трудового дня и семьи;
- помощь в формировании портфолио и постоянная практика.
В конце обучения ученики получают не только полезные знания и навыки, но и их документальное подтверждение – электронный сертификат.





