
Вся информация в компьютерах и технике представлена в зашифрованной форме. Она непонятна человеку, но хорошо распознается различными устройствами. Кодировки могут быть разными: текста, видео, изображений и так далее.
Сегодня нужно познакомиться с кодированием символов. Предстоит выяснить, что это вообще за процедура такая, зачем она нужна, какие особенности имеет. Также нужно ознакомиться с UTF-8.
Опубликованная информация рассчитана на широкий читательский круг. Она подойдет как школьникам и обычным ПК-пользователям, так и IT-специалистам. В конце станет ясно, какие варианты символьного шифрования существуют, а также для чего они применяются.
Кодирование – это…
Кодирование символов – это процесс, в ходе которого графические символы получают свои собственные номера. Такой вариант «шифрования» характерен символам человеческого языка. Он дает возможность выполнять с алфавитом разнообразные действия:
- хранить;
- преобразовывать;
- передавать.
Изучая основы кодирования текстовой информации, необходимо помнить о нескольких ключевых определениях.
К ним относят:
- кодовые точки – числовые значения, которые составляют кодировку символов;
- кодовое пространство (карта символов) – совокупность кодовых точек.
Обычно код символа имеет размер 8 бит. Кодовая страница способна включать в себя 256 символов. Это привело к тому, что сейчас техника использует разнообразные кодировки. Каждая из них позволяет зашифровать разное количество элементов и имеет свои собственные преимущества и недостатки.
Популярные кодировки
Сегодня можно встретить несколько стандартов шифрования текста в компьютерах и другой технике. Наиболее распространенными вариантами являются:
- ASCII (или Аски). Это американский стандарт для информационного обмена. С его помощью можно представить: десятичные цифры, управляющие системные знаки и знаки препинания, латинский и национальный алфавит. Изначально такое шифрование было 7-битным, но позже оно было расширено до 8-бит. Русский алфавит такой стандарт не обрабатывает.
- Windows -1251. Первая разработка для Windows, которая позволила работать с русским алфавитом.
- Unicode. Стандарт кодирования, который позволяет представлять в технике почти все существующие языки.
На последнем варианте шифрования стоит остановиться поподробнее. Именно к нему относится UTF-8.
Unicode
Unicode (Юникод) – стандарт шифрования текстовой информации, который был представлен в 1991 году. Он появился благодаря некоммерческой организации «Консорциум Юникода».
С помощью соответствующего стандарта удается закодировать огромное количество символов из разных письменностей, включая китайские и японские иероглифы, математические символы, буквы греческого алфавита, латиницу, кириллицу и так далее. Переключаться между различными кодовыми страницами в случае с Unicode не придется.
У Юникода есть несколько стандартов:
- UTF-32;
- UTF-16;
- UTF-8.
Каждый из них имеет свои ключевые особенности. Сейчас наиболее популярным становится стандарт UTF-8.
UTF-32
UTF-32 – первая реализация стандарта Юникод. Цифра в его названии – это количество бит, необходимых для шифрования одного символа/знака. А значит, для кодирования нужно 4 байта.
UTF-32 является более совершенным стандартом, чем ASCII. При его использовании изначальный вес файла увеличивался в 4 раза. Стандарт начал устаревать. Его сменил UTF-16.
UTF-16
UTF-16 – разработка Юникода, которая по умолчанию используется для всей компьютерной техники. Для шифрования одного элемента используются 16 бит или 2 байта.
С помощью UTF-16 удалось шифровать 65 536 символов. Именно они формируют базовое пространство всего Unicode. Размер документа с соответствующей схемой кодирования увеличился в 2 раза при преобразовании с ASCII, а не в 4. Несмотря на это, соответствующий вариант все равно не устроил специалистов.
Обычно проблемы возникали у тех, кто пишет и разговаривает на английском. Если для русского языка UTF-16 подходил очень хорошо, то в случае с англоязычными документами приходилось мириться с увеличением исходного файла в 2 раза.
Сейчас UTF-16 можно встретить в Windows. Посмотреть данную кодировку предлагается так:
- Открыть меню «Пуск» и переключиться на службу «Служебные».
- Выбрать пункт «Таблица символов».
- В дополнительных параметрах отображения выставить Unicode.
Теперь можно выделить тот или иной элемент, а затем посмотреть пункт UTF-16. Около него будет запись, с помощью которого шифруется тот или иной символ.
Конечная разработка данного стандарта позволила кодировать около 1 миллиона элементов. Несмотря на это, пришлось снова преобразовывать Юникод. Так, чтобы размер исходных документов после преобразований устраивал пользователей.
Новый стандарт Unicode
UTF-8 пришел на смену UTF-16. Данный вариант шифрования является не только новым, но и распространенным. Он позволяет компактно хранить и передавать символы Юникода. У него переменное количество байт. Оно может составлять от 1 до 4.
UTF-8 полностью совместим с 7-битной Аски. Сейчас он активно используется при веб-разработке, а также в UNIX-подобных операционных системах. Появился UTF-8 в 1992 году.
Если сравнивать этот стандарт с предыдущим в Юникоде, то он имеет больший выигрыш при использовании текста на латинице. Данное явление связано с тем, что латинские буквы без диакритических знаков, цифры и наиболее распространенные знаки препинания будут шифроваться всего одним байтом. Соответствующие коды полностью совпадают с аналогичными символами в ASCII.
Как закодировать текст
UTF-8 позволяет шифровать текст в несколько шагов. Соответствующий принцип стандартизирован в RFC 3629.
Согласно соответствующему документу, для шифрования информации в UTF-8 необходимо:
- Определить, сколько байт (октетов) нужно для шифрования одного элемента. Символьный номер берется из Unicode-стандарта.
- Установить старшие биты октета в соответствие количеству необходимых байт для шифрования, определенных на предыдущем этапе. Для этого используются различные записи: 0xxxxxxx – для одного октета, 110xxxxx – для двух октетов, 1100xxxx – для трех байт, 1110xxx – при использовании 4-х октетов.
- При необходимости выделения более одного байта для шифрования в UTF-8 в 2-4 октета два старших бита представлены всегда равными 10xxxxxx. С помощью соответствующего приема получается легко выделить первый бит в потоке.
- Установить соответствие значащих битов октетов с номерами символов в Юникоде, представленных в двоичной интерпретации. Заполнять данные нужно с младших битов символьного номера. Они подставляются в младшие биты последнего октета. Свободные биты первого бита заполняются нулями.
На практике UTF-8 вручную для шифрования и дешифрования текста не используется. Обычно для этого применяются специализированные программы и конвертеры.
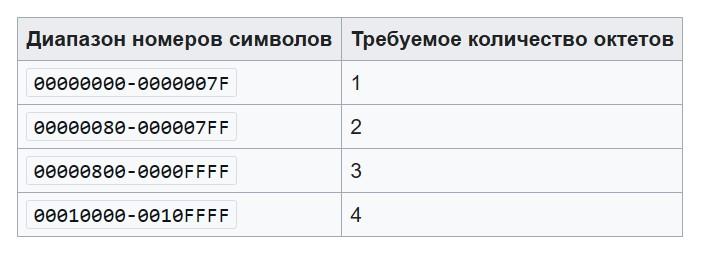
Выше – таблица, помогающая выполнить первый этап в представленном алгоритме. Она способствует определению октетов и дальнейшим необходимым манипуляциям.
Сравнение с Windows-1251
UTF-8 и Windows-1251 часто встречаются в Windows OS. Если отличие соответствующего варианта кодирования от UTF-32/16 понятно, то с Windows -1251 все не так просто.
UTF-8 является многобайтовой «системой», причем переменной длины. Для шифрования одного элемента могут использоваться как 1, так и 6 байт. В отличие от UTF-8, Windows-1251 является однобайтовой.
Основным отличием представленных методов кодирования является используемый символьный набор. В UTF-8 для работы доступно их гораздо большее количество. В Windows-1251 допустимо использовать 255 элементов.
Также Юникод используется в веб-разработке: на сайтах и в приложениях. Windows-1251 для этого не подходит.
Теперь понятно, что собой представляет UTF-8, а также какие методы кодирования текста используется в компьютерах. Лучше разбираться в них помогут дистанционные компьютерные курсы.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!




