
Современные технологии стремительно развиваются. А вместе с тем появляются разнообразные способы создания софта. В процессе реализации поставленной задачи задействуются всевозможные элементы: односвязный список, а также операторы, переменные и так далее. Довольно популярным является некий Java. Он достоин внимания каждого уважающего себя программиста.
О языках программирования
Языком программирования считают формальные правила и их наборы, необходимые для создания софта. Своеобразный элемент, посредством которого пользователь «общается» с компьютером и приложениями. Аналогичным образом техника «разговаривает» с программным обеспечением.
У каждого языка программирования имеется лексика – функции и операторы, при помощи которых согласно синтаксисным принципам составляются всевозможные выражения. Чтобы создать приложение, нужно выбрать язык и набрать исходный код. Кодификаций очень много. Одним из самых популярных является некий Java.
Java – определение
Java – способ «общения» пользователя с компьютером. Относится к объектно-ориентированному программированию и предусматривает строгую типизацию. Многофункциональный, универсальный.
Джава используется для написания:
- Android-приложений;
- компьютерного софта;
- банковских утилит;
- научных программ;
- программного обеспечения, предназначенного для Big Data;
- веб-утилит;
- корпоративного ПО;
- строенных систем (и маленькие чипы, и спецкомпьюетры).
Среди недостатков выделяют следующие черты:
- невысокую скорость работы;
- высокие требования к памяти устройства;
- отсутствие поддержки низкоуровневого программирования;
- обновления 2019 года для бизнеса и коммерции – платные;
- составление новой утилиты отнимает большое количество времени.
Но Java может оказаться полезным. Это – объектно-ориентированная среда, функциональная и с простым синтаксисом. Надежный и независимый. Элементы, написанные на Джаве, запускаются на всех поддерживающих «языковую раскладку» девайсах.
В процессе составления кода приложения используются односвязные списки и другие составляющие синтаксиса. Этот элемент является крайне важным в программировании.
Связный список – понятие
Связным списком (linked list) называется структура данных, в которой элементы упорядочены линейным образом. Сам порядок определяется не как в массивах по номерам этих самых составляющих, а указателями. Последние входят в состав элементов списка, применяются для указания на следующий «этап».
Должен содержать две «детали»:
- голову;
- хвост.
Без этих составляющих списки линейного типа немыслимы.
Плюсы и минусы перед массивами
Корректировка связных элементов осуществляется за постоянное время (0(1)), чего нет в массивах. Может с легкостью расширяться. Для этого достаточно добавить очередной элемент.
Но перед использованием соответствующей составляющей языка важно помнить: для поиска конкретного «предмета» требуется каждый раз проходить весь список. Время доступа к искомому = O (n).
Узлы
Новый узел (new node) – это элемент линейного списка. Содержит информацию, подлежащую дальнейшему сохранению, а также указатель на следующий элемент в «перечне» или значение NULL, если рассматриваемая «часть» является последней.
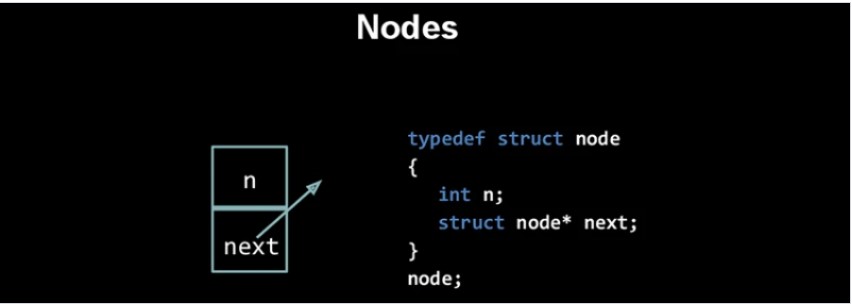
В приведенном примере описан код структуры, реализующий элемент связного списка (и всей «конструкции» тоже). Информация представляется числовыми данными.
Простыми словами: синтаксис структуры для создания собственного типа информации для инкапсуляции узлов активно используется программистом. Здесь:
- Int n – сведения, которые хочется сохранить в узле;
- struct node*next – указатель на следующую составляющую в списке;
- typedef-ed – не присваивается до выполнения соответствующих строк.
Так, сначала записывается узел struct вместо предыдущего элемента перед и внутри фигурных скобочек. В последней строчке предоставляется node для tupedef в качестве имени, используемого для очередного типа данных оставшейся части приложения.
Односвязные
Односвязные списки – такие объекты, которые включают в себя «маркеры»-указатели на следующий узел. Из точки А можно попасть лишь в точку Б. Так пользователь будет двигаться в самый конец перечня. То есть, пошагово, последовательно.
Вследствие происходит образование потоков, текущих в одном заданном направлении. Полем указателя последнего элемента служит нулевое значение. То есть, NULL.
Основные манипуляции, осуществляемые посредством ОЛС:
- инициализация;
- добавление новых элементов в перечень;
- удаление узлов и корней;
- вывод составляющих списка;
- взаимообмен нескольких «частей» перечня.
Далее будут рассмотрены все эти операции с примерами кодов для большей наглядности.
Инициализация
Операция необходима для того, чтобы создавать корневые узлы списков, у которых поля с указателями на следующие составляющие обладают нулевым значением:
struct list * init(int Z) // Z- информация в первом узле
{
struct list *lst;
// осуществление выделения необходимой памяти для дальнейшей работы
lst = (struct list*)malloc(sizeof(struct list));
lst->field = Z;
lst->ptr = NULL; // обозначение последнего узла
return(lst);
}Это – самый простой вариант развития событий. Но в процессе работы пригодятся и другие манипуляции.
Добавление
При добавлении элементов в списки функциям присваиваются следующие аргументы:
- информация для добавляемой составляющей;
- непосредственный указатель на задействованный элемент.
Проводится в несколько этапов. Сначала создается добавляемый узел и заполняются его поля информации. Затем переустанавливаются предыдущие указатели на тот, что хочется внедрить. Завершающим этапом является установка указателей добавляемого элемента туда, куда «показывал» прошлый узел.
struct list * addelem(list *lst, int number)
{
struct list *temp, *p;
temp = (struct list*)malloc(sizeof(list));
p = lst->ptr; // сохранение «маркера» на последующий «объект»
lst->ptr = temp; // указание предыдущим элементом на новый
temp->field = number; // поля данных нового элемента сохраняются в память
temp->ptr = p; // указание созданным узлом на предыдущий элемент
return(temp);Адрес добавленного узла – возвращаемое значение задействованной функции.
Удаление
При удалении элементов ОЛС функциями аргументов служат указатели на подлежащий стиранию «объект», а также «маркер» его корня. Функции возвращают указатель на элемент, который следует за удаленным.
Тоже проводится в несколько шагов:
- постановка указателя предыдущей составляющей на следующий за тем, что подлежит деинсталляции;
- высвобождение памяти устройства.
Код будет примерно следующим:
struct list * deletelem(list *lst, list *root)
{
struct list *temp;
temp = root;
while (temp->ptr != lst) // список с корня просматривается с самого начала
{ // изучение до тех пор, пока не обнаружена «часть», предшествующая lst
temp = temp->ptr;
}
temp->ptr = lst->ptr; // перестановка маркера в новое место
free(lst); // освобождение положенной части памяти
return(temp);
}В случае со стиранием корней ситуация обстоит иначе:
struct list * deletehead(list *root)
{
struct list *temp;
temp = root->ptr;
free(root); // высвобождается память корня, который удаляли
return(temp); // создание нового корня
}Функции удаления корней в списках в виде аргументов получают указатели на текущие корни перечней. Возвращаемое значение – новый корень. А именно – узел, на который указывал удаленный.
Вывод
Отобразить элемент списка можно следующим макаром:
void listprint(list *lst)
{
struct list *p;
p = lst;
do {
printf("%d ", p->field); // выводится значение, присвоенное ранее p
p = p->ptr; // осуществляется переход к следующей составляющей
} while (p != NULL);
}Аргументом в функции вывода становится указатель на корень списка, а сама функция последовательно обходит все элементы перечня с последующим их выводом (значений).
Обеспечение взаимообмена
При подобных обстоятельствах кодификация, используемая для реализации поставленной задачи будет иметь примерно следующее представление:
struct list * swap(struct list *lst1, struct list *lst2, struct list *head)
{
// Возвращение нового корня списка
struct list *prev1, *prev2, *next1, *next2;
prev1 = head;
prev2 = head;
if (prev1 == lst1)
prev1 = NULL;
else
while (prev1->ptr != lst1) // ищется элемент, который предшествует lst1
prev1 = prev1->ptr;
if (prev2 == lst2)
prev2 = NULL;
else
while (prev2->ptr != lst2) // осуществляется поиск узла, идущего перед lst2
prev2 = prev2->ptr;
next1 = lst1->ptr; // «часть», идущая после lst1
next2 = lst2->ptr; // узел после lst2
if (lst2 == next1)
{ // непосредственный обмен данными соседних элементов
lst2->ptr = lst1;
lst1->ptr = next2;
if (lst1 != head)
prev1->ptr = lst2;
}
else
if (lst1 == next2)
{
// обмен соседних узлов
lst1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst2;
}
else
{
// обмен отстоящий элементов
if (lst1 != head)
prev1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst1;
lst1->ptr = next2;
}
if (lst1 == head)
return(lst2);
if (lst2 == head)
return(lst1);
return(head);
}В этом случае работа связных списков основывается на обмене узлового характера. Аргументы функций ОЛС – это два указателя на обмениваемые узлы, а также указатели корня списка. Функция отвечает за возврат корневого «объекта» списка.
Могут рассматриваться разные ситуации:
- заменяемые «частицы» находятся по соседству;
- обрабатываемые узлы – не соседние.
Когда маркеры переустанавливаются, требуется проверка на причастность к корню списка. Если заменяемая составляющая является таковой, все нормально. В противном случае узел, предшествующий корневому, будет отсутствовать.
Двусвязные
Еще один тип связных списков – двусвязный. Он похож на обычный, но составляющие хранят ссылки не только на следующие, но и на предыдущие «частицы». Это позволяет осуществлять перемещение по списку туда-сюда. Односвязный список, в отличие от предложенного вниманию, предусматривает только движение вперед.
Каждый элемент в данном случае будет иметь несколько полей: next и prev, указатели на предыдущий/следующий составляющие соответственно.
Далее будут рассмотрены основные операции с двусвязными «перечнями». Пусть они предусматривают несколько конструкторов (Null и DoublyList), в которых возможны различные действия.
Для Null (изначально список пуст):
- data – место хранения имеющихся значений;
- next – указатель на следующую составляющую «перечня»;
- previous – маркер предыдущего элемента.
Для DoublyList:
- tail – конец списка;
- head – начало списка;
- _lenght – извлечение количества узлов в «перечне»;
- add(value) – добавление новой составляющей;
- remove(position) – отвечает за удаление;
- searchNodeAt(position) – поиск узла на заданной позиции.
Коды будут выглядеть соответственно:

И public class Doubly:

Метод добавления
Двунаправленные списки предусматривают метод добавления. Приведенный пример отвечает за реализацию нескольких сценариев. Если перечень пуст, список по голове и хвосту получает добавляемый узел. Добавляется новый элемент. Когда «перечень» уже имеет «составляющие», нужно найти конец и установить добавляемый узел как tail.next.
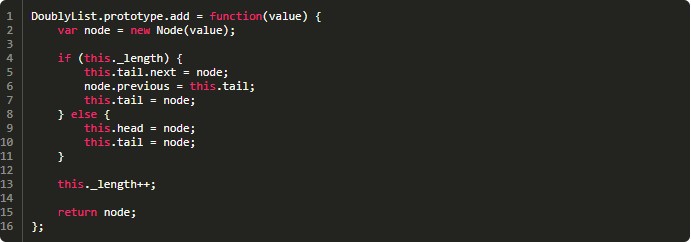
После этого задается двунаправленная обработка для нового окончания. Требуется установить в качестве tail.previous первоначальную конечную «составляющую».
Метод поиска
В данном случае действовать предстоит подобно ситуации с односвязными «перечнями»:
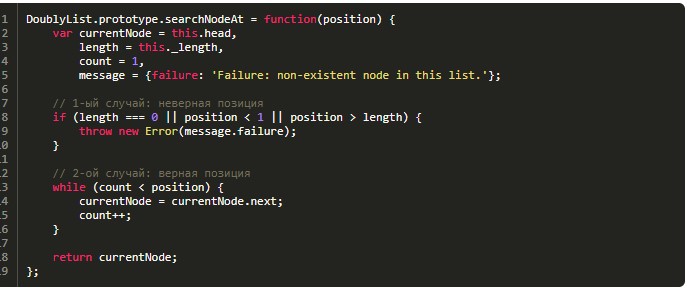
Предложенный спи сок будет обрабатываться для поиска элемента на заданной позиции.
Стирание
Это более сложный код для пользовательского понимания. Поэтому сначала стоит рассмотреть его представление:
Здесь remove(position) будет обрабатывать несколько возможных ситуаций:
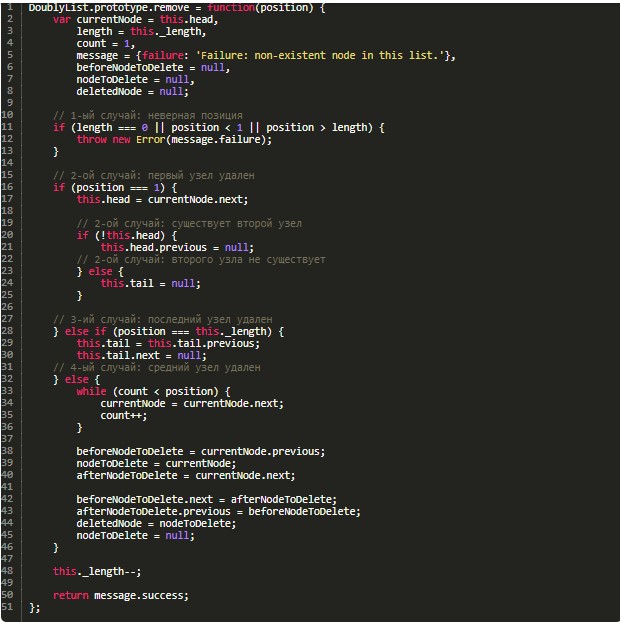
- Позиции, которая передается в качестве аргумента remove не имеет места. На экран будет выводиться сообщение об ошибке.
- Позиция, служащая аргументом remove – это первый узел списка (голова). В случае подтверждения соответствующего утверждения head становится deleteNode, после чего в качестве нового начала назначается следующий узел в «перечне». Дальше осуществляется проверка на наличие большего количества «составляющих». Если они отсутствуют, head получает null, происходит переход к части if в операторе if-else. В теле «ифа» устанавливается конец (tail) в виде null. Происходит возврат списка в исходное «положение» пустого двусвязного «перечня». Когда удаляется первый узел и остается более одного элемента, осуществляется перемещение к else, после чего устанавливается свойство previous для головы на null. Это проделывается, так как перед началом других «объектов» больше нет.
- Позиция-аргумент remove – это окончание «перечня». Хвосту присваивается deleteNode, в качестве нового окончания выступает предыдущий узел. После нового tail другие узлы отсутствуют, а он получает свойство next как null.
- Цикл while разрывается, стоит лишь currentNide указать на элемент, который находится в позиции-аргументе remove. Далее происходит переназначение beforeNodeToDelete и afterToDelete на «объект», который идет после nodeToDelete и перед ним. Ссылки убираются на удаленный узел, переназначаются на правильные. Завершается операция установкой nodeToDelete в значении deletedNode, а значением служит null.
В результате описанного алгоритма происходит уменьшение длины списка с последующим возвратом deletedNode.
Теперь понятно, каким может быть первый элемент односвязного списка или двусвязного, как он называется и используется на практике. Приведенные примеры помогают лучше ориентироваться в изученной теме. Они не являются исчерпывающими.
Односвязный список — элементарный, без «пути назад». В программах чаще всего используются их двусвязные аналоги, предоставляющие большее поле для различных манипуляций.





