
Следующая часть статьи посвящена нескольким базам данных и их работе в Питоне. Начало здесь.
Как подружить Python с БД – ключевые моменты
Для начала стоит рассмотреть структуру (схему) используемого в дальнейших примерах «хранилища электронных материалов».
Пусть БЛ состоит из четырех табличек:
- users;
- posts;
- comments;
- likes.
Точная структура для Python показана на картинке ниже. Она пригодится при непосредственной обработке информации.
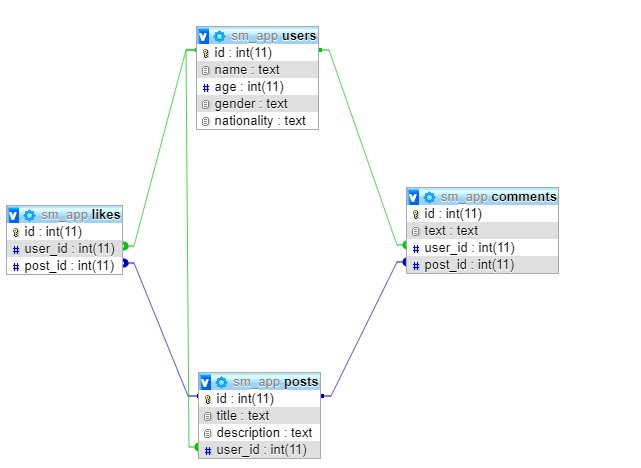
Здесь стоит обратить внимание на следующие моменты:
- Пользователи и публикации – имеют тип связи «один ко многим».
- Каждый клиент имеет право оставлять множество комментариев.
- У поста может быть несколько комментов.
- Лайки обладают идентичными характеристиками, что и комментарии.
Если разработчик не понимает структуру имеющихся данных, он не сможет грамотно составить приложение, которое работает с соответствующей БД.
Подключение
Перед тем, как начать работу с данными в Python (их «хранилищами»), требуется осуществить предварительное подключение оных. SQLite работает с Питоном по умолчанию. Для MySQL потребуется дополнительная библиотека под названием PyMySQL. Она представляет собой набор кодов, которые подходят для работы с MySQL в Питоне от версии 3.0. Если разработка ведется на более старых вариациях ЯП, библиотека не пригодится.
Дальнейшие примеры будут приведены на основе SQLite, MySQL и PostgreSQL. Именно такая последовательность рассматривается для всех операций и манипуляций.
SQLite – самый простой вариант. Подключиться к ней можно только через средства Python без дополнений. По умолчанию ЯП имеет модуль sqlite3 для обработки электронных материалов.
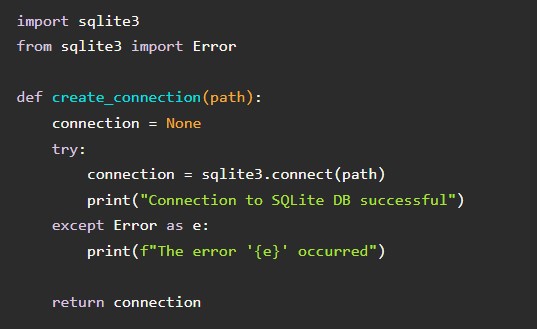
А вот скрипт, который поможет установить соединение с SQLite:

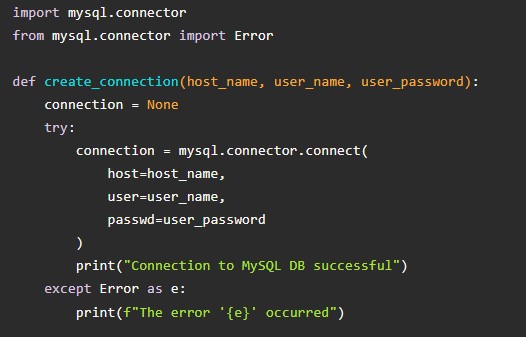
В случае с MySQL операции происходят чуть иначе. Они требуют:
- скачивания и инициализации драйверов mysql-connector-python.
- установки соединения с сервером;
- выполнения запроса.

Картинка выше показывает принцип загрузки необходимого модуля для Python. Далее – код, отвечающий за подключение к серверу MySQL, а также за возврат объекта подключения:

Для PorstgreSQL нужно действовать так же, как и в случае с MySQL – сначала скачать модуль драйверов и инициализировать его:
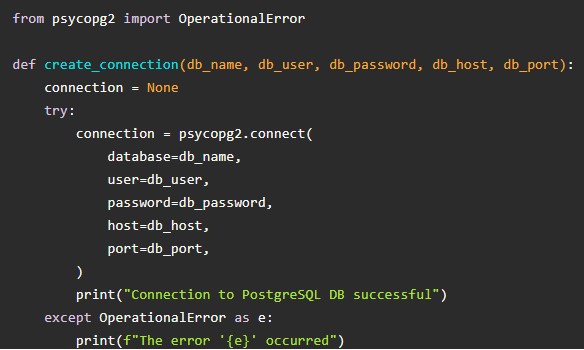


Выше представлены функции для определения хранилища информации, а также непосредственного подключения.
Создание таблиц
Чтобы создавать таблицы, нужно использовать метод cursor.execute().
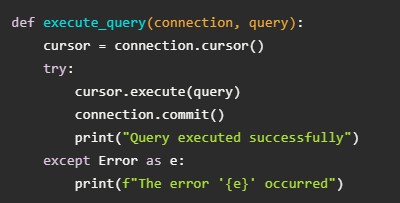
Далее нужно сформировать передаваемый запрос. Он будет носить название query:
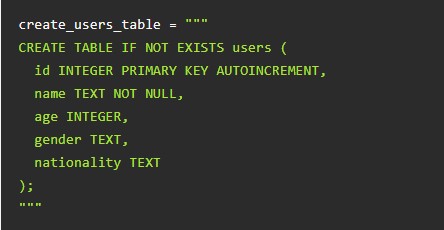
А вот запрос, который заставит табличку появиться:

Чтобы создать posts, потребуется код:
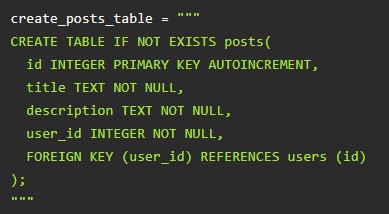
Для комментов и лайков:
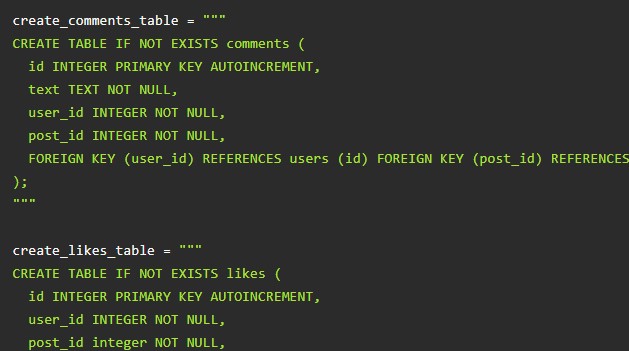
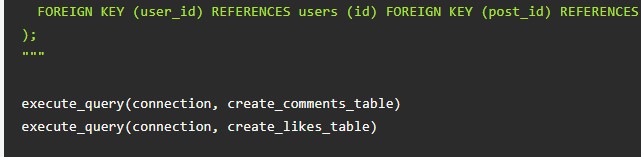
Это – примеры для SQLite. По данной ссылке можно увидеть кодификации для MySQL и PostgreSQL. Далее в основе будет заложен именно SQLite
Вставка записей
Здесь можно воспользоваться следующими особенностями:
- Можно использовать функцию, что и для создания табличек – execute_query().
- Чтобы воспользоваться таким приемом, нужно сначала сохранить запрос insert into в виде строки.
- Далее – осуществить передачу объекта connection и строку (запрос) в execute_query.
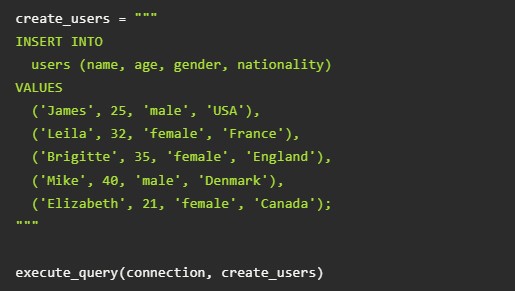
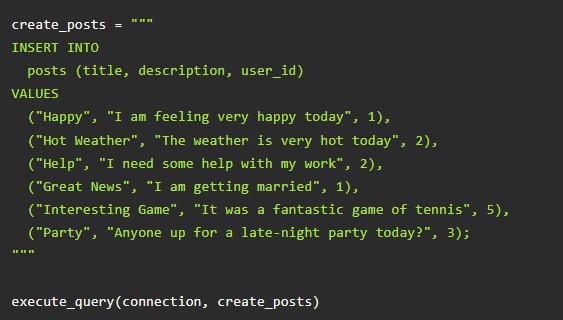
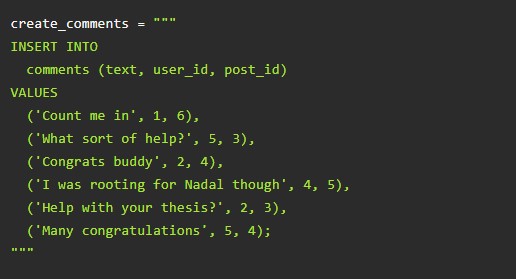
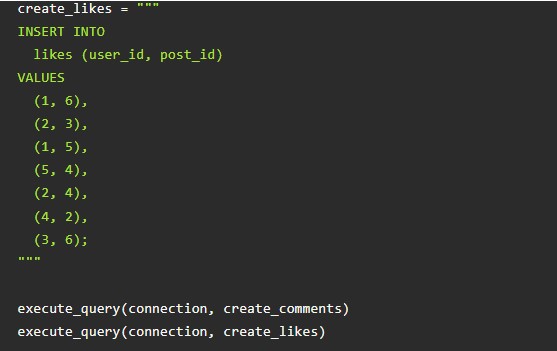
Выше – примеры добавления электронных материалов для всех составляющих «хранилища».
Извлечение из записей
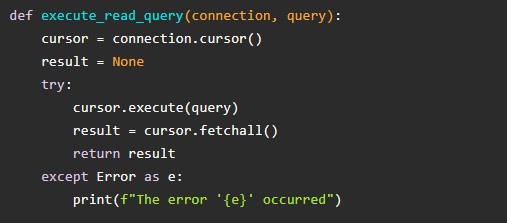
А вот еще одна важная возможность. Она помогает выбирать записи и использовать их. В SQLite применяется cursor.execute(). Но после этого придется обратиться к методу fetchall(). Он будет возвращать список кортежей, где каждый «элемент» соответствует строке в извлеченных записях. Вот пример функции для упрощения реализации поставленной задачи:
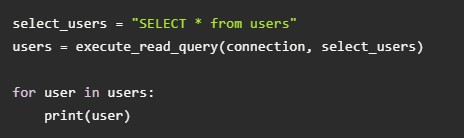
Теперь можно выбрать все записи из таблички users. Для этого подойдет оператор Select:
Для постов этот элемент кода будет иметь аналог:
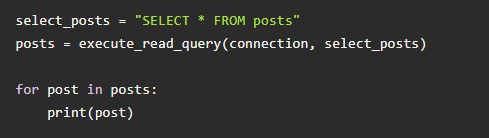
В Python есть возможность формирования более сложных запросов. В этом поможет команда join. С ее помощью удается извлечь сведения из связанных таблиц. Вот идентификаторы и имена пользователей и их посты:
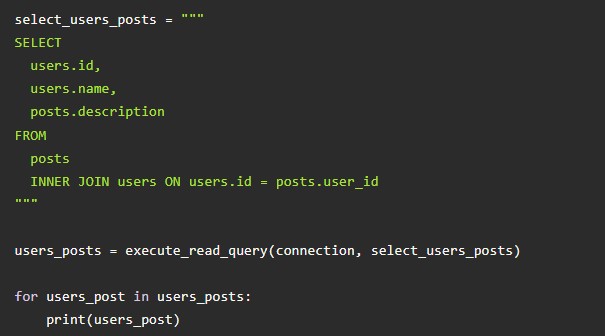
А можно воспользоваться Select-запросом, который будет возвращать текст поста и общее количество собственных лайков. Для этого на помощь придет Where:
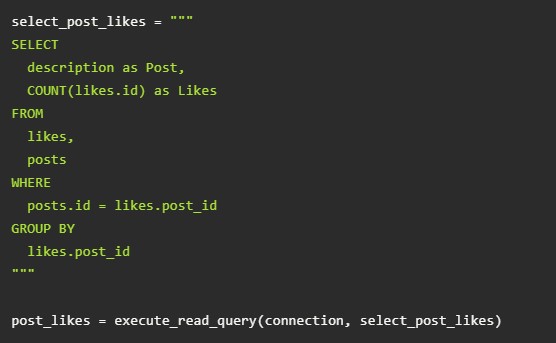

Обновление
Стоит обратить внимание на еще одну важную операцию. Речь идет об обновлении. Тут нужно учитывать следующие моменты:
- Можно применять execute_query().
- Пример позволит обновить текст сообщения с id под номером 2.
- Сначала нужно написать описание для Select.
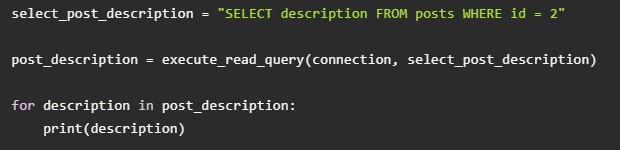
- А вот скрипт, который обновит описание:
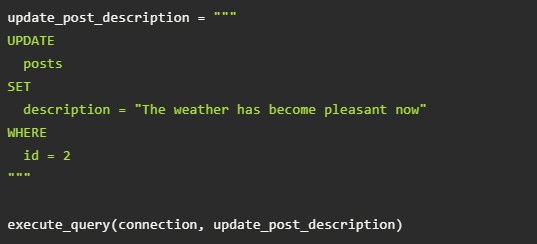
Завершающий этап – это выполнение Select-запроса. Данный алгоритм приведет к обновлению необходимой записи.
Удаление
Для удаления информации нужно использовать команду Delete. В примере, приведенном ниже, происходит стирание комментария с id = 5:

Библиотеки для анализа данных
У Python довольно мощный функционал. Дополнить его можно через специализированные библиотеки. При любом программировании это – полезный прием, облегчающий процедуру коддинга.
Форматирование и очистка
Первый тип библиотек помогают форматировать и очищать данные. Он значительно упрощает соответствующие задачи, делая их максимально понятными даже новичку:
- Dora. Нужна для разведенного анализа данных. Автоматизирует ключевые части соответствующего процесса.
- DataCleaner. Проект, принимающий на вход материалы в DataFrame, а затем выбирает некорректные и исправленные значения.
- PrettyPandas. Помогает приводить датайфреймы в удобный вид. Для этого применяется pandas Style API.
- Tabulate. Выводит читабельной форме списки списков, списки, а также иные структуры. Умеет работать с массивами NumPy.
- Scrubadub. Инструмент обработки конфиденциальных данных в Python.
- Arrow. Оптимизирует работу со временем, которая является проблемой для нативной разработки в выбранном ЯП.
- Beautifier. Упрощает контактирование с электронными ящиками и URL-адресами.
- Ftfy. Библиотека, превращающая плохие строки Unicode в хорошие.
Все это – только начало. Но данных библиотек хватит для весьма качественной разработки программного обеспечения на Python.
Визуализация
У Питона есть специализированные библиотеки практически для всех способов отображения электронных сведений. Далее предложены 10 универсальных вариантов. Это – непревзойденные лидеры как для новичков, так и для опытных разрабов:
- Matplotlib. Один из стандартов визуализации. Для презентаций подойдет не лучшим образом из-за стиля 90-х годов.
- Seaborn. Своеобразная «обертка» Matplotlib. У нее есть ряд улучшений, которые сказались на эстетике.
- Ggplot. Работа базируется на графиках. Сложные персонализированные структуры здесь создать проблематично, а вот элементарные и небольшие – запросто.
- Bokeh. Имеет поддержку выгрузки элементов JSON, в HTML и интерактивные веб-утилиты. Умеет передавать материалы в режиме реального времени. Предусматривает потоковый метод обработки.
- PyGal. Простая библиотека, которая умеет выгружать материалы в SVG. Результаты удается встроить в веб-контент.
- Plotly. Обладает адаптацией для интерактивных веб-утилит. Позволяет создавать контурные графики, дендограммы, трехмерные чертежи.
- Geoplotlib. Нужна для того, чтобы работать с картами. Чтобы запустить оную, требуется Pyglet.
- Gleam. Превращает результаты анализа в интерактивные утилиты на Питоне через его скрипты. Не требует специальных навыков и знаний HTML или CSS.
- Missingno. Служит для отображения полноты электронных материалов. Помогает тогда, когда библиотеки очистки вводных от пропущенных полей не дают желаемого результата.
- Leather. Представляет чертежную библиотеку для Python. Позволяет создавать графики «здесь и сейчас». Подходит для любых типов данных.
Работа с БД и обработка информации в Питоне – это не так трудно. А освоить соответствующее направление с нуля помогут специализированные онлайн курсы.





