
Цель статьи — рассказать о важности классических структур данных в контексте работы компьютерных программ. Мы кратко затронем основы структуризации данных, а также рассмотрим особенности применения некоторых наиболее популярных структур и их функциональные характеристики.
Одна из важных составляющих хранения цифровой информации в памяти персонального компьютера заключается в наличии возможности преобразования этой информации в формат, максимально подходящий для компьютера. Не менее важно определить и структуру данных, которая будет пригодна для используемой информации, то есть речь идет о структуре данных, которая предоставит разработчику весь необходимый набор возможностей по работе с данными.
Давайте, для примера, посмотрим на кольцевой список:

На картинке выше мы видим структуру данных, под которой понимается конкретный способ представления информации, благодаря чему совокупность отдельно взятых компонентов формируют нечто единое целое. Это целое обусловлено наличием взаимосвязей между компонентами. Так как элементы скомпонованы по правилам и имеют логическую связь друг с другом, их можно эффективно обрабатывать, а все потому, что общая используемая структура предоставляет набор возможностей по функциональному управлению. Это, по сути, основы взаимодействия, благодаря которым можно достичь высоких результатов в решении тех либо иных задач.
Однако не каждый объект можно представить в произвольной форме — иногда для объекта существует лишь один единственно подходящий метод интерпретации, а это значит, что знание существующих структур данных — очень важная составляющая успеха, если ваша цель — писать качественные программные приложения, то есть стать действительно хорошим разработчиком. Таким образом, очень часто тому, кто пишет программы, приходится выбирать между разными способами возможного хранения информации, и конечная цель этого выбора очевидна — создание работоспособного продукта.
Если абстрагироваться от вычислительной техники, то можно сказать, что информация структурируется не только для того, чтобы ее обработал компьютер. Достаточно вспомнить любую книгу, содержимое которой вне зависимости от стиля оформления разбито на параграфы, главы, страницы, содержание и т. п., то есть пользователь получает в свое распоряжение некий структурированный объект, оснащенный вполне себе понятным «интерфейсом». Если рассмотреть этот вопрос еще более широко, то есть глобально, то мы увидим, что более-менее понятная структура есть и у каждого живого существа, ведь без наличия оной вряд ли органический организм смог бы жить.

Возвращаясь к базовым основам информатике, упомянем и простые структуры, которые состоят из целых составляющих, не делимых на составные части. На практике они встраиваются непосредственно в функциональные языки программирования. Такие структуры еще именуют типами данных. Однако эти способы хранения информации лучше всего сразу изучать с конкретным языком программирования.
Наибольший интерес представляют интегрированные структуры данных:
— массивы;
— связные списки;
— очереди;
— стеки;
— деревья, включая бинарные (двоичные) деревья;
— графы (более сложный аналог деревьев).
Кратко поговорим о некоторых наиболее популярных.
Массивы
Имеют фиксированный и упорядоченный набор однотипных элементов. Доступ к любому элементу массива дан ных достигается с помощью индекса (по номеру и имени). Число индексов определяет размерность. Одномерный массив — это вектор, двумерный — матрица. Если хотите получить нужный элемент, укажите для вектора один индекс, а для матрицы укажите два индекса.
В различных языках программирования особенности обработки массивов могут отличаться, однако общая суть, то есть основы и базовые принципы, не меняются. К примеру, во время применения следует помнить, что нумерация элементов осуществляется поочередно, причем чаще всего нумерация начинается с нуля.

Мы сейчас описали классический статический массив — его определяет однородность хранимых в нем данных. Если же условие однородности не выполняется, массив называют гетерогенным.
Также существуют динамические массивы. Их определяет непостоянство размеров, в результате чего по мере отработки программы размер массива меняется. Наличие этой функции повышает гибкость использования, однако за все нужно платить: динамические массивы теряют в быстродействии, да и сам процесс усложняется, поэтому за кратчайшее время их уже не обработаешь.
Если кратко, то массив массиву рознь, так как возможны разные реализации и особенности применения.
Списки
Списки – абстрактные типы данных, реализующие упорядоченный набор значений. Какими действиями они отличаются от массивов? Да хотя бы такими, что последние позволяют осуществлять доступ к своим элементам произвольно, тогда как в случае со списками действия по доступу производятся последовательно.
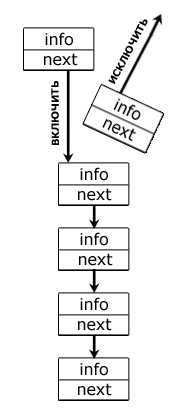
У списков бывают разные реализации, одна из основных — связный список. Он представляет конечное множество упорядоченных элементов, которые связаны друг с другом определенным образом — с помощью указателей. Каждый компонент содержит поле с информацией и указатель на последующий элемент. Произвольный доступ к элементу в списке, как уже было сказано выше, отсутствует.
Ниже — односвязный список:

Односвязная реализация этой структуры данных не очень удобна, так как из одной точки вы сможете попасть лишь в следующую, передвигаясь в конец. Если же кроме указателя на последующий элемент, существует указатель и на предыдущий, то речь идет уже о двусвязном списке:

Наличие возможности движения и вперед, и назад весьма полезна при выполнении ряда действий и операций, но мы опять же подходим к тому, что ничто не дается просто так: дополнительные указатели требуют большего объема памяти.
Указывая в самом начале статьи кольцевой список, мы не сказали, что это подвид обычного классического списка. Чтобы получить кольцевой список из односвязного, надо всего лишь добавить всего один указатель в последний компонент, причем таким образом, чтобы он ссылался на первый. Аналогично и для двусвязного, но уже понадобятся 2 указателя: на первый и последний элементы.

Стек
Характерная черта — доступ к компонентам осуществляется только с одного конца — с вершины стека, то есть стек функционирует по принципу LIFO (last in — first out). Для повышения удобства представления стека обычно используются такие аналогии, как стопка книг или кирпичей. Вряд ли вы сможете достать нижний кирпич, не сняв верхние.
Очередь
Очередь составлена и функционирует по принципу FIFO (First In, First Out). Добавление возможно лишь в конец этой структуры, а извлечение осуществляется только с начала.

Используемые ссылки:
— https://kvodo.ru/osnovnye-struktury-dannyh.html.




