
Сортировкой называется последовательное расположение или разбиение элементов на группы в заданном множестве. Также это способ классификации или упорядочения компонентов имеющегося списка/цепочки.
В программировании и информатике принято выделять различные методы сортировки данных. Каждый вариант имеет собственные ключевые особенности и нюансы. Далее предстоит изучить сортировку методом Хоара, а также иные концепции, помогающие упорядочить элементы множества. Основной упор будет сделан на QuickSort. Остальные приемы рассмотрены поверхностно.
Предложенная информация рассчитана на широкую публику. Она в равной степени будет полезна как обычным пользователям, так и IT-специалистам.
Ключевые компоненты сортировок
Каждая сортировка элементов оценивается (классифицируется) при помощи разнообразных параметров. Они будут меняться в зависимости от сложности алгоритма, его устойчивости, а также времени, затраченного на реализацию.
В разработке программного обеспечения и информатике выделяют следующие характеристики алгоритмов упорядочивания элементов массива:
- Время работы. Наиболее важный компонент, который оценивает худшее, среднее и лучшее время реализации. Последний параметр отражает минимальный промежуток, за который концепция реализуется на том или ином наборе данных. Им обычно выступает тривиальный массив [1, …, n]. Худшим временем называется предельное время реализации. Большинство современных способов упорядочивания имеют такие оценки как O(n log n) и O(n2).
- Память. Параметр, который указывает, сколько дополнительной памяти требуется на реализацию того или иного метода. Сюда можно включить дополнительные массивы, переменные, затраты на стек вызовов. Они бывают чаще всего O(1), O(log n) и O(n).
- Устойчивость. Устойчивая сортировка не будет менять порядок имеющихся элементов в массиве, если у них одинаковые ключи. Ключом называется поле компонента, по которому осуществляется упорядочивание.
- Количество обменов. Этот параметр важен, если планируется работать с большими объектами и цепочками. Время, затраченное на реализацию алгоритма, будет увеличиваться по мере возрастания количестве элементов в массиве.
- Детерминированность. Указывает на независимость операций присваивания, обмена и иных от предыдущих манипуляций. Все сортирующие сети выступают в качестве детерминированных.
Вся эта информация пригодится при изучении вопросов, связанных с упорядочиванием элементов массивов. Далее более подробно будет рассмотрен алгоритм QuickSort и другие методы, позволяющие сортировать компоненты множеств. Эта информация поможет быстрее классифицировать данные и массивы.
Описание метода Хоара
Быстрая сортировка (метод Хоара) – один из простейших и надежных способов упорядочивания элементов в заданной цепочке (множестве). Соответствующая концепция широко используется при сортировке. Ее среднее время работы составляет O(n log n), что является оптимальным временем реализации алгоритмов, базирующихся на сравнении.
Пользуясь методом быстрой сортировки, необходимо помнить основной ее принцип – «разделяй и властвуй». Она часто называется qsort (по имени в стандартной библиотеке C-языка). Разработан Тони Хоаром. Концепция не идеальна – она имеет на практике некоторые недостатки. Из-за этого Quick Sort используется с некоторыми доработками.
Это упорядочивание элементов в массиве сравнением. За счет данной особенности алгоритм получил возможность работать с компонентами любого типа, для которых определено отношение «меньше, чем». В эффективных реализациях подобная концепция является нестабильной, зато очень быстрой.
Принцип работы
Быстрая сортировка – это, как уже было сказано, принцип «разделяй и властвуй». Такие алгоритмы сначала делят крупный массив на два подмассива поменьше, а затем рекурсивно упорядочивают элементы в подмножествах.
Рассматриваемый прием работает быстро и реализуется в несколько этапов:
- Выбирается опора. Необходимо определить опорный элемент массива. Чаще всего им выступает самый левый или самый правый компонент множества.
- Происходит разделение элементов. Переупорядочивание массива и его компонентов осуществляется так, чтобы все составляющие меньше опорного располагались перед ним, а все элементы, которые больше «опоры» – после. Равные значения допускаются в любых направлениях. Стержень после описанных манипуляций будет занимать свое конечное положение.
- Повторение. Здесь осуществляется рекурсия описанных ранее шагов для подмассива элементов с меньшими значениями, чем у опорного. Отдельно необходимо использовать метод к подмножеству с компонентами, значения которых превосходят «опору».
Классическим случаем сортировки рекурсии служат подмассивы размером с единицу. Их никогда не требуется сортировать. Ниже можно увидеть, как выбран левый элемент на каждом этапе алгоритма в качестве опорного. Далее массив разбивается по «опоре» и повторяется в двух подмножествах, полученных вследствие дробления:
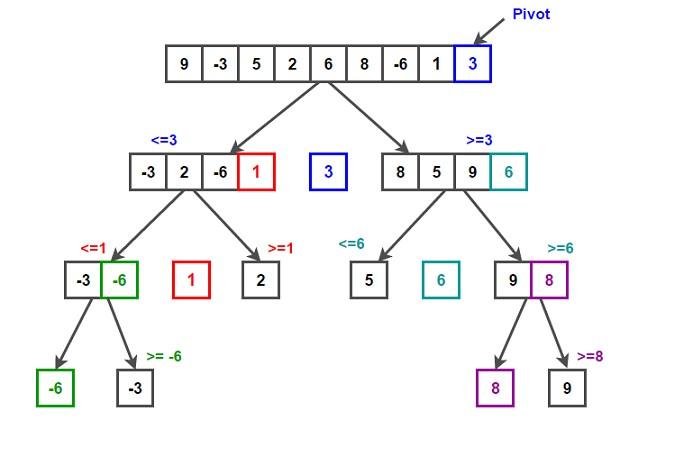
Этапы выбора опоры и разбиения могут выполняться несколькими способами. Выбор определенных схем реализации оказывает существенное влияние на производительность рассматриваемой концепции.
Ключевые особенности
Быстрая сортировка имеет множество нюансов. Первый момент – это рекурсия. Так называется ситуация, при которой функция будет вызывать сама себя, но дополнительно ей необходимо держать в памяти все предыдущие этапы. При использовании сразу нескольких рекурсий (в правой и левой частях массива) может потребоваться очень много свободной памяти. Для обхода соответствующего ограничения используются другие эффективные методы упорядочивания элементов. Они тоже будут рассмотрены.
Несмотря на то, что на реализацию «быстрого» алгоритма может потребоваться немало памяти, прием имеет множество преимуществ:
- он является одним из самых быстрых, когда заранее ничего неизвестно про массивы, с которыми предстоит иметь дело;
- алгоритм имеет простую реализацию, что позволяет с легкостью переносить его с одного языка программирования на другой;
- метод легко распараллеливается и разбивается на отдельные этапы (процессы);
- концепциях работает на данных с последовательным доступом.
Для особо крупных массивов подобный прием лучше не использовать. Для обучения и относительно небольших множеств это идеальное решение при упорядочивании данных..
Выбор опорного элемента
Правильный выбор опорного элемента быстрой сортировки значительно повышает эффективность реализации метода. Определиться с соответствующим моментом можно, руководствуясь следующими советами:
- Опорный элемент будет первым – в самых первых версиях метода Хоара. Именно так удалось обработать магнитную ленту за один проход.
- Средний элемент – тот, который физически расположен по центру (в середине) имеющегося массива.
- Медианный элемент – элемент, значение которого находится посередине между всеми значениями в заданном массиве.
Это не исчерпывающие техники выбора «опоры». Остальные концепции используются тогда, когда разработчик точно знает, с какими массивами предстоит иметь дело.
Производительность
Худшая временная сложность, которой обладает быстрая сортировка – O(n2), где n – размер ввода. Такая ситуация возникает, когда стержень оказывается самым большим или маленьким элементом массива или когда все составляющие множества равны между собой. В соответствующем случае упорядочивание станет менее сбалансированным. Это будет связано с тем, что стержень поделит массив на два подмассива размерами 0 и n-1. При повторении ситуации в каждом разделе каждый рекурсивный вызов будет обрабатывать список, который окажется на единицу меньше предыдущего множества.
В лучшем случае временная сложность алгоритма быстрой сортировки будет равна O(n log n). Ситуация возможна, когда опорная точка поделит имеющееся множество почти на две равные части. Это приведет к тому, что каждый рекурсивный вызов будет заниматься обработкой списка вдвое меньшей размерности.
Примеры
Теперь, когда понятны основные принципы реализации, можно посмотреть наглядные примеры быстрой сортировки. Они продемонстрируют использование алгоритма на нескольких известных языках программирования.
Kotlin:

C++:
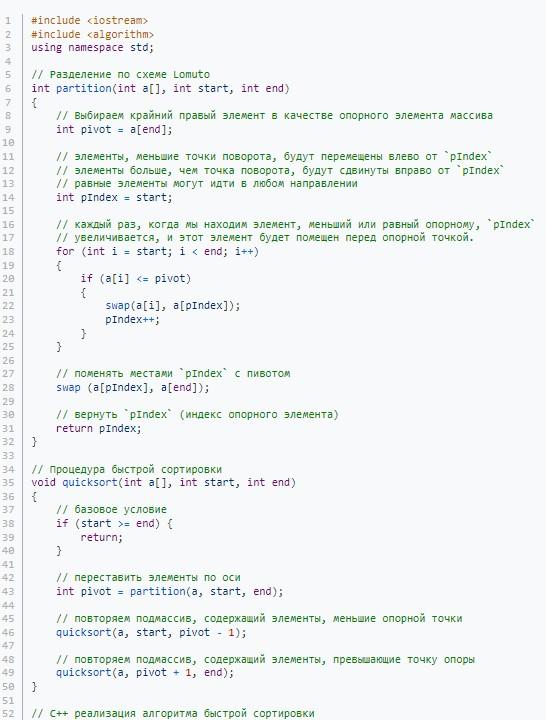
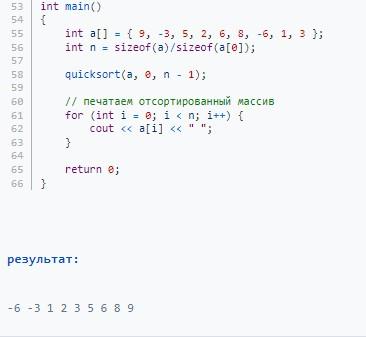
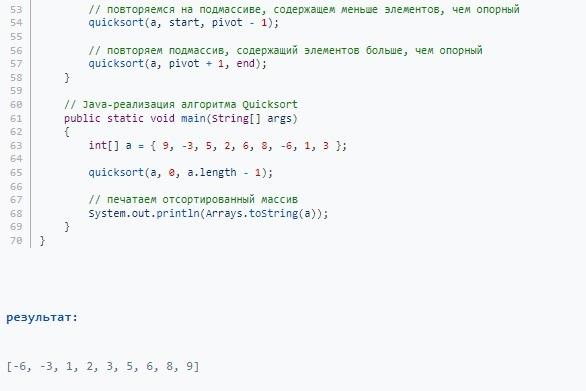
Java:

Python:
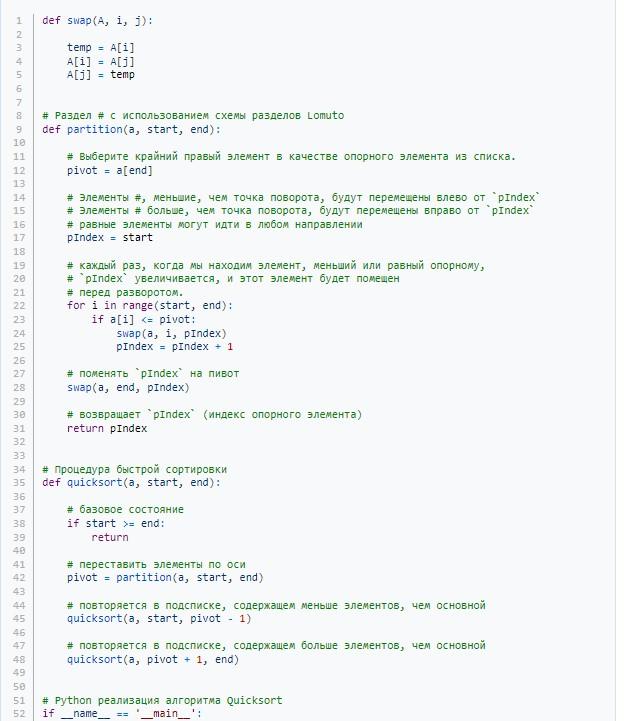
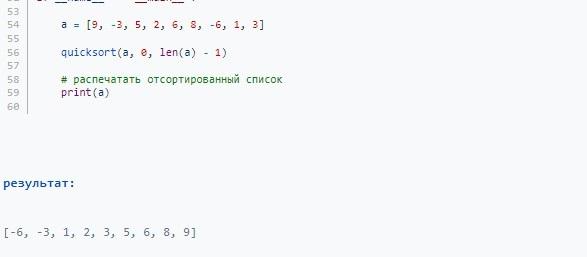
Теперь, когда самые быстрые сортировки массива изучены, можно рассмотреть несколько других методов упорядочивания компонентов множества. Основная их масса является достаточно простой в плане реализации.
Пузырьковый метод
Каждый раз, когда речь заходит об упорядочивании множеств, разработчикам предлагается начать с изучения пузырькового метода. Он является основой для большинства более сложных алгоритмов упорядочивания.
Пузырьковая сортировка базируется на последовательном сравнении значений двух соседних компонентов (попарно). Если текущее число больше следующего, элементы меняются местами. В противном случае все остается «как было». Алгоритм повторяется до тех пор, пока все множество не будет отсортировано.
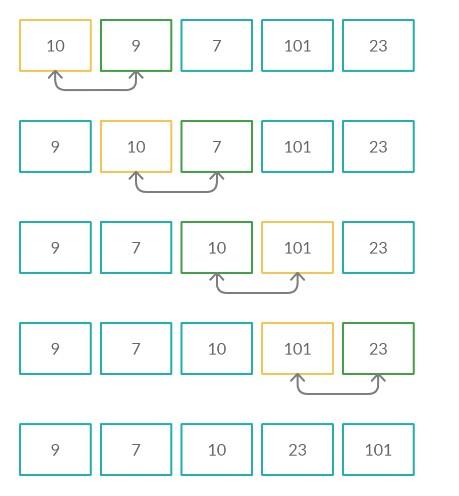


Соответствующий прием является учебным. Он легко применяется в небольших списках и цепочках данных. Имеет низкую эффективность, из-за чего на практике почти не встречается. Зато служит основой работы основной массы более быстрых и точных алгоритмов классификации информации. Примеры методов, основанных на пузырьковом, – шейкерная сортировка или «расческа».
Метод перемешивания
Следующий способ «классификации» составляющих в цепочке – это концепция перемешивания или шейкерная сортировка. Служит более совершенным вариантом пузырькового метода работы с массивами.
Она отличается от «пузырьков» тем, что классификация информации здесь осуществляется в рамках одной итерации, но сразу в обоих направлениях – слева направо и справа налево. В случае с пузырьковым алгоритмом применяется только одно направление – слева направо.


Выше – параметры концепции, а также код, который поможет реализовать «шейкерную» классификацию при разработке программного обеспечения. Общая идея:
- Массив обходится слева направо, как в «методе пузырька».
- Соседние компоненты сравниваются. Если левое значение оказывается больше правого, они меняются местами. На выходе получится, что самое большое число переместит код в конец множества.
- Массив обходится в обратном направлении. Начинается процесс с составляющей, которая находится перед последней отсортированной.
- На соответствующем этапе компоненты будут тоже сравниваться между собой и меняться местами. Это необходимо, чтобы меньшее значение всегда находилось слева.
После реализации приема наименьший компонент будет перемещен системой в самое начало имеющейся цепочки.
Расческа
Самый быстрый алгоритм сортировки массивов – qsort. Он является не единственным встречающимся на практике. Разработчики могут упорядочивать множества и числовые цепочки при помощи самых разных приемов. «Пузырек» и «коктейльный» алгоритм – не исчерпывающие подходы.
Еще один алгоритм «быстрой сортировки» – это метод «расчески». Он относится к пузырьковому подходу. Используется для устранения маленьких значений, которые располагаются в конце заданного списка («черепах»).

«Черепахи» уходят за счет того, что в месте сравнения двух соседних компонентов сравниваются составляющие на достаточно большом расстоянии. Этот промежуток будет постепенно уменьшаться. Сначала разрыв берется максимальный – на единицу меньше, чем заданное множество. Далее с каждой итерацией расстояние делится на фактор уменьшения. Это происходит до тех пор, пока разность индексов сравниваемых составляющих списка не достигнет единицы. В соответствующем случае нужно сравнить соседние элементы, как в методе «пузырька». Это последняя итерация в алгоритме.
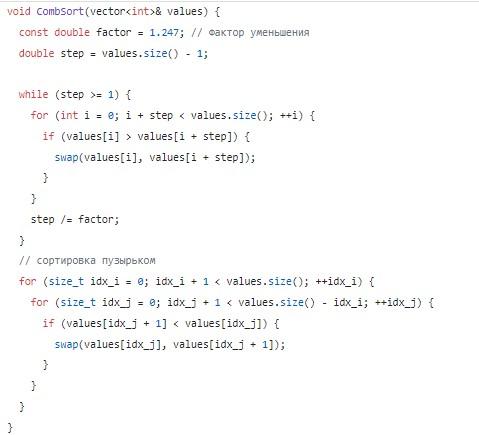
Оптимальным значением фактора уменьшения является параметр, равный 1,247.
Вставка
Выбрать самую быструю сортировку массивов бывает не так легко, ведь соответствующих методов очень много. Можно воспользоваться концепцией вставки. В ней множество будет постепенно перебираться слева направо. Каждый последующий компонент разместится так, чтобы он оказался между ближайшими составляющими списка с минимальным и максимальным значениями.

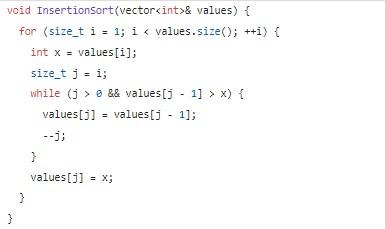
Поэтапно этот алгоритм можно представить так:
- Первый компонент множества сравнивается со вторым. По мере надобности – меняются местами. Условно соответствующие составляющие представляют собой отсортированное множество. Остальные – неотсортированное.
- Сравнивается следующий компонент заданной цепочки из неотсортированной части. Он будет вставлен в нужную позицию.
- Второй этап повторяется до тех пор, пока в неотсортированной части не закончатся числа.
Такой вариант достаточно эффективный, но вручную его реализовать проблематично. Для тех, кто только начал изучать принципы упорядочивания данных, он не подойдет.
Пирамида
Как функционирует сортировка Хоара (быстрая), понятно. И некоторые принципы упорядочивания элементов множеств тоже уже изучены. Достаточно простым и эффективным алгоритмом, помогающим расставить компоненты списка по возрастанию, является концепция пирамиды.
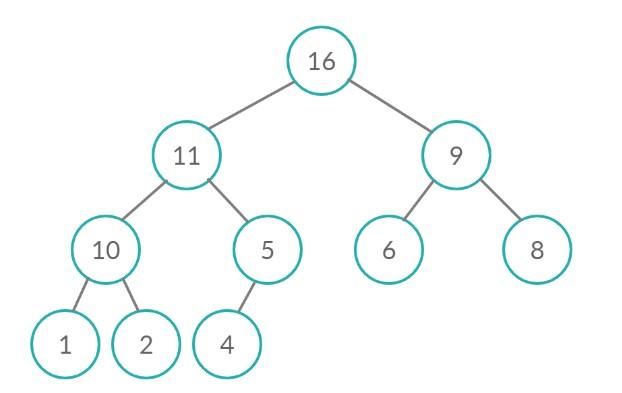

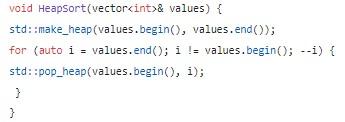
Здесь сначала ищется максимальный компонент, который перемещается в самый конец списка. Далее рекурсивно эта операция повторяется для оставшихся составляющих.
Корзинный алгоритм
Корзинная концепция (или блочная) – подход, базирующийся на разделении входного множества на несколько частей (сегментов или блоков), а также использовании других, ранее изученных алгоритмов для упорядочивания.
Работает корзинный метод так:
- Множество делится так, чтобы компоненты в каждом последующем сегменте были всегда больше, чем в предшествующем.
- Организовывается упорядочивание элементов при помощи указанных ранее концепций. Допускается рекурсия разбиением на сегменты.
- Все получившиеся блоки объединяются в один массив.


Выше – основные параметры метода и его код на Kotlin. Теперь понятно, какая сортировка самая быстрая на C и других языках. Более детально изучить этот вопрос помогут специальные дистанционные компьютерные курсы.



