
В процессе работы с информационными технологиями, разработки программного обеспечения, а также системного администрирования специалистам приходится сталкиваться с весьма сложными понятиями и операциями. Одним из наиболее важных моментов при обработке данных является кодирование. Этот момент дополняется операцией декодирования, без которой не получится понять, «что написано» в документе или файле.
Далее предстоит более подробно рассмотреть вопросы, связанные с кодированием информации, кодировками в операционных системах и декодированием. Опубликованные сведения подойдут в равной мере как новичкам, так и более опытным специалистам. Они ориентированы на широкую публику. Покажутся полезными администраторам, разработчикам и «рядовым» пользователям в равной степени.
Кодирование и декодирование – определения
Кодирование – процедура, помогающая преобразовывать символы, сигналы и данные из привычной человеку формы в вид, «понятный» электронному оборудованию. Прием, благодаря которому можно подготовить информацию для дальнейшей обработки, передачи, хранения и иных манипуляций.
При кодировании символов на выходе будут получаться записи, состоящие из нулей и единиц. Данный прием используется в двоичных системах.
Исторически сложилось так, что каждый элемент, отображаемый на экране, может быть выражен несколькими способами. За соответствующий момент отвечают таблицы. Они зависят от типа используемой на устройстве операционной системы.
Декодирование – процедура, помогающая «расшифровать» понятный устройству код и представить его в ясной и привычной пользователю форме. Выполняется соответствующий прием в основном при помощи специальных приложений. Они называются декодировщиками. Небольшой текст можно «расшифровать» самостоятельно, зная особенности и принципы кодирования данных.
Ключевые термины и определения
Если пользователю хочется выяснить, как происходит преобразование символов в «понятный» компьютеру вид и обратно, сначала необходимо запомнить несколько определений. Они помогут быстрее разобраться в рассматриваемой области:
- Кодирование – трансформация информации из одной формы в другую, более удобную для оперирования, хранения и обработки.
- Системы кодирования – комплекс правил и закономерностей, обозначения символов/электронных материалов в виде того или иного формата кода.
- Код – система знаков и иных компонентов, необходимых для передачи информации. В основном представлены 0 и 1.
- Двоичный код – метод хранения и отображения символов с применением всех двух знаков: нулей и единиц. Применяется преимущественно в вычислительной технике и ЭВМ.
- Бит – элемент кодирования информации. В двоичной системе – 0 или 1.
- Декодирование – обратное кодированию преобразование символов. При помощи такого приема пользователи смогут «расшифровать» написанное устройством и отобразить результат в «привычной» форме.
- Символ – минимальная единица текстов с семантическим значением.
- Символьный набор – набор, в которым каждый элемент соответствует своему уникальному идентификатору.
- Кодовая точка – любое значение, которое допускается символьной таблицей.
- Единица кодирования – «размер слова» схемы кодирования (8-бит, 16-бит и так далее).
Указанные термины пригодятся всем, кто заинтересован в символьных преобразованиях. Главное – разобраться с видами кодировок и их особенностями.
История возникновения
Кодирование и декодирование появилось относительно недавно. В 1960-х годах ЭВМ столкнулись с такой особенностью как несовместимость. Подобные неполадки возникали не только на разном оборудовании, но и на машинах одного предприятия-производителя. Соответствующий момент сказался на универсальности. Для каждой отдельно взятой задачи из раза в раз требовалось создавать отдельную таблицу символов. С ее помощью – осуществлять ввод и вывод информации.
Еще в 1958 году начали выпускаться первые компьютерные системы. В те времена они включали в себя сети с несколькими устройствами. Пример – SAGE. Она использовалась для объединения станций Канады и США. Результаты расчетов в ней разрешалось задействовать на любом оборудовании, подключенном к этой самой сети. Для достижения описанного результата были сформированы первые единые таблицы символов (кодов).
Уже в 1962 году IBM начала развивать универсальные компьютеры. В 1965 году в свет вышла System/360. Она включила в себя 6 моделей из совместимых модулей. Каждый имел свою производительность и стоимость, благодаря чему потребители получили свободу выбора. ЭВМ стали вливаться в обыденную жизнь. Это привело к тому, что разработка программного обеспечения потребовала единых стандартов распознавания символов.
Разновидности
Символы можно «зашифровывать» несколькими способами. Все зависит от того, какой операционной системой на данный момент пользуется клиент. Если на двух устройствах задействованы разные таблицы символов, существует вероятность появления при декодировании непонятных графических интерпретаций – «кракозябр».
Основными кодировками в IT в 21 веке выступают следующие варианты:
- ASCII;
- Unicode (UTF-8 /16/32);
- KOI8-R;
- CP866;
- Windows 251.
В современных компьютерах чаще всего используются ASCII и Юникод (UTF-8 /16). С ними проще всего работать. Данные наборы символов умеют распознавать практически все алфавиты, включая русские буквы (кириллицу).
ASCII – базовый тип
Далее каждый «набор символов» будет изучен более подробно. Особое внимание будет уделено кодировке UTF. ASCII – это «базовый набор символов». Он используется при работе основной массы устройств. Здесь первые 128 символов – наиболее распространенные. Они поддерживают:
- арабские буквы;
- знаки препинания;
- служебные элементы;
- латинские буквы.
При использовании ASCII задействован всего один байт. Такой подход привел к тому, что у упомянутого набора символов появились более «обширные» версии. Классическая форма представления ASCII не предусматривают работу с русскими символами, а также с кириллицей.
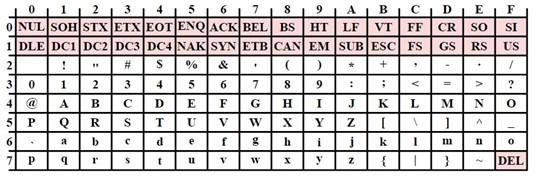
Выше – стандартные элементы ASCII. Они значительно отличаются от UTF-8 и других символьных наборов.
Расширенные ASCII
ASCII – это основа всех кодировок, которые известны в 21 веке. В «классической» ее форме поддерживаются 128 элементов. В расширенной – 256. Такой подход позволил добавлять новые алфавиты и символьные записи для отображения на экранах в будущем.
Первый вариант расширенного ASCII – CP866. Она поддерживает латиницу и кириллицу. Верхняя часть совпадает с ASCII, нижняя – дает перспективы «шифрования» кириллицы и некоторых специальных компонентов. Таких, которых нет на клавиатуре.
Еще один расширенный вариант – KOI8-R. Не стоит путать его с UTF-8. Второй расширенный вариант ASCII поддерживает «трансформацию» символов одним байтов. В KOI8-R буквы русского языка расположены не «по алфавиту». Здесь они размещаются по созвучию с кириллицей.
Windows 1251
Развитие систем «шифрования» символов напрямую связывается с совершенствованием графических компонентов в операционных системах. Необходимость в псевдографике пропала. Это привело к тому, что возникли группы, ранее выступающие в виде расширенных ASCII, но с большим уровнем совершенности. В них отсутствовали псевдографические компоненты. Они стали называться ANSI. Позже появился Юникод и UTF 8.
Наиболее распространенный вариант ANSI – это Windows 1251. Он:
- вместо псевдографики предлагает недостающие кириллические компоненты и русскую топографику;
- не имеет знака ударения;
- первые 32 составляющие – это операции, пробел и перевод строки;
- до 127 компонента будут располагаться: латинский алфавит, цифры, знаки математических действий и препинания;
- оставшиеся «пространства» отводятся для национальных алфавитов.
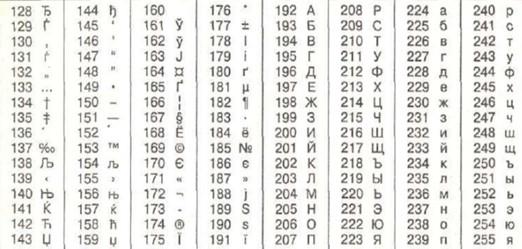
Выше – часть Windows 1251. Соответствующий фрагмент отображает кириллические компоненты и другие составляющие.
Unicode
Юникод – символьная таблица, которая пользуется огромным спросом в современных компьютерах. Именно здесь встречается UTF-8 и другие варианты отображения данных. Unicode выступает универсальным средством «трансформации» электронных материалов. В основном распространен в Сети. Основан в 1991 году. Unicode – официальный стандарт, который включает в себя практически все знаки существующих на письме языков.
Юникод – многоязычный стандарт. Он опирается на ASCII. Включает в себя не только кириллицу, но и азиатские иероглифы. Поддерживает несколько стандартов, среди которых обязательно выделяется UTF-8.
UTF-32
Самый первый вариант кодировки – UTF 32. Для того, чтобы закодировать один компонент, здесь используются 32 бита (или 4 байта). Соответствующее явление привело к увеличению «веса» одного элемента по сравнению с ASCII в 4 раза.
В UTF-32 все компоненты поддерживают непосредственную индексацию. Пользователь сможет по номеру отыскать именно тот элемент, который его заинтересовал. Такой прием привел к тому, что замена символьных данных стала ускоряться.
UTF-16
До появления UTF-8 Юникод предложил пользователям еще один стандарт – UTF-16. Он является более совершенным, чем «предшественник». Выступает в качестве базового пространства для всех печатных компонентов. Кириллица здесь тоже поддерживается, как и другие алфавиты.
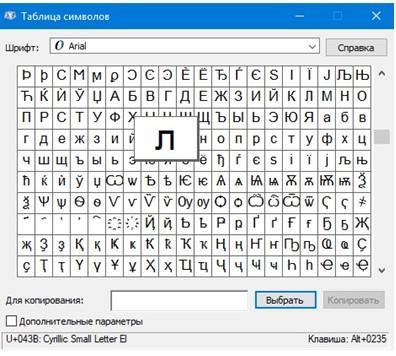
Соответствующий стандарт предлагает отображение не 0 и 1, а в 16-ричной системе счислений. Посмотреть отображение компонента в Юникоде при помощи UTF-16 можно за счет раздела «Таблица символов» в Windows. Она располагается в меню «Служебные».
В отличие от UTF-8 и других стандартов, UTF-16 позволяет работать с 65 536 компонентами. Это – базовое значение для Юникода. В расширенном пространстве поддерживаются до миллиона дополнительных записей.
По сравнению с ASCII-стандартом, исходный документ при «трансформации» будет увеличиваться не в 4, а уже в 2 раза. Явление связано с тем, что для одного кодового компонента требуется 2 байта или 16 бит.
UTF8
Кодировка UTF совершенствуется. На данный момент Юникод поддерживает новый стандарт. Он называется UTF-8. Соответствующий «сборник» тоже поддерживает кириллические символы. Несмотря на то, что в названии стандарта UTF-8 стоит 8-ка, длина получившейся записи меняется. Она может быть от 1 до 6 байт. В основном UTF-8 использует компоненты, поддерживающие «объем» до 4 байт. Латиница «зашифровывается» здесь точно также, как в ASCII – 1 байтом.
UTF-8 поддерживает 2 байта для русских букв, для грузинских – 3. Соответствующий стандарт допускает печать не только букв. В UTF-8 поддерживаются смайлики. Этот стандарт хорошо обрабатывается даже системами, которые не ориентированы изначально на Юникод.
На данный момент UTF-8 широко распространена в веб-пространствах. Она активно применяется в UNIX-подобных операционных системах. UTF-8 появился в 1992 году, в самом начале сентября. В Windows он имеет идентификатор 65001.
Как шифровать
UTF-8 encoding – процедура не самая простая. Сначала необходимо выяснить, как «зашифровать» запись в рассматриваемом стандарте. Операция включает в себя несколько этапов:
- Определение количества байтов, необходимых для «шифрования». Номер элемента берется из стандарта Юникода:
.
- Установить старшие биты первого октета в соответствие с необходимым количеством октетов на первом этапе: 0xxxxx – 1 октет, 110 – два, 1110 – три, 11110 – четыре октета.
- Установить значащие биты октетов в соответствие с номером символа Юникода, представленном в двоичной форме. Заполнение производится с младших битов в UTF-8. Свободные биты первого октета заполняются нулями.
Если в процессе работы с UTF-8 требуется больше одного октета, в октетах 2–4 два старших бита устанавливаются как 10xxxxxx). За счет данного приема удается с легкостью определить первый октет в потоке.
Как декодировать
Для организации encoding UTF-8 используются специальные программы – декодировщики. Они могут быть написаны на разных языках программирования или представляться в качестве веб-страничек.
Вот – наглядный пример подобного проекта в Интернете. Воспользоваться им легко:
- Под надпись «Декодер онлайн» в левой части установить значение выпадающего списка на UTF-8.
- Слева – указать, в какую форму представления преобразовывается исходный текст.
- Вставить в пустую область в левой части данные, необходимые для преобразования с UTF-8.
- Нажать на кнопку «Расшифровать».
Результат преобразования с UTF-8 появится в окне, расположенном справа.
Возможные ошибки
Рассматриваемый стандарт поддерживает не каждую последовательность байтов. Декодеры UTF-8 должны понимать и адекватно устранять такие ошибки как:
- недопустимые байты;
- отсутствие нужного количества байтов в записи для продолжения 10xxxxxx;
- байт продолжения без начального;
- обработка строки посреди элемента;
- неэкономное и нерациональное «шифрование» – использование 3 байтов вместо возможных 2-х.
Чтобы лучше разбираться в кодировании по самым разным стандартам, а также освоить написание дешифровщиков, рекомендуется записаться на дистанционные компьютерные курсы. На них научат с нуля работать с информацией в IT, а также разрабатывать собственные программные продукты.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!

