
Кластеризация объектов или кластерный анализ – многомерная статическая процедура, которая отвечает за сбор информации с данными в выборке объектов. За счет нее система упорядочивает элементы в сравнительно однородные группы. Статья может быть интересна специалистам, занимающимся анализом данных, Big Data и машинным обучением.
Кластеризация (или кластерный анализ) – задача разделения (разбиения) множества объектов на группы. Они носят название кластеров (отдельных категорий, «блоков»). Внутри каждой группы располагаются только «схожие» компоненты. Элементы разных групп при кластеризации должны максимально отличаться друг от друга.
Соответствующий прием стремительно и активно применяется в программировании и разработке, машинном обучении, искусственном интеллекте и маркетинге, финансах, администрировании и других сферах жизни/работы человека.
Далее с кластерами и их «классификацией» предстоит разобраться получше. Необходимо понять, с чем программист/аналитик будет иметь дело, рассмотреть пример анализа и полученные результаты, а также изучить спектр существующих методов кластеризации.
Что это такое
Clustering analysis или кластерный анализ – своеобразный метод анализа данных, при котором объекты разделяются на группы по значимым (важным) критериям. Пример – супермаркет. В нем продукты располагаются по рядам, а каждый из них подписан как «мясо», «овощи», «заморозка», «хлеб» и так далее. Макароны не могут попасться среди «заморозки», а мясо – в конфетах. Подобное разделение – это и есть деление на кластеры.
Сегменты, которые получены после кластеризации данных, изучаются специалистами. Пример – алгоритм (algorithm) смог выделить несколько клиентских групп:
- люди, покупающие продукт 20 раз за год;
- лица, приобретающие ту или иную продукцию раз в год.
Маркетологи могут изучать каждый кластер, а затем понять, как повысить мотивацию «отстающих» покупателей на приобретение товара.
Области применения
Кластеры данных широко применяются в современной жизни. Он может встречаться в:
- Маркетинге. Технология деления на кластеры способствует сегментированию клиентов, конкурентов, а также рынка.
- Медицине. Кластеры «классифицируют» заболевания, препараты и симптоматику.
- Биологии. Разделение животных и растений.
- Социологии. Используются кластеры данных для того, чтобы делить респондентов на однородные группы лиц.
- Финансах. Банки применяются данный тип анализа для «классификации» клиентов, услуг и процессов, финансовых операций.
- Компьютерных науках. За счет работы с кластерами получается в удобной форме представлять результаты поиска сайтов, файлов и других объектов. Они способствуют более быстрому анализу Big Data и машинному обучению.
Кластеризация (cluster analysis) может встречаться везде, где требуется структурировать и систематизировать информацию. Она активно используется специалистами для работы с данными.
Цели и задачи
Задачи кластеризации – это:
- Сжатие информации. Кластеры актуальны, если исходные выборки слишком объемные. После применения соответствующего приема от каждого сегмента останется по одному типичному представителю. Количество кластеров может быть любым. Главным моментом при сжатии данных является обеспечение максимального сходства компонентов друг с другом внутри каждого «типа».
- Поиск паттернов в информационном пространстве. Кластер данных позволит добавить дополнительный признак каждому компоненты. Если в результате analysis (анализа) выяснилось, что тот или иной покупатель относится к одному сегменту потребителей, а также известно, что это – категория людей с самыми крупными расходами по средам, можно сделать вывод о том, когда именно человек совершает покупки.
- Обнаружение аномалий. При кластеризации объектов удается выделить нетипичные элементы. Такие, которые не подходят ни к одному сформированному сегменту.
- Анализ цен. Кластеры данных – это отправные точки для более глубокого ценового анализа. Способствуют грамотному ценообразованию и формированию адекватной конкурентоспособности.
- Продвижение. Рассматриваемый процесс – верный помощник любого маркетолога. На основе сегментации продукции продавцы получают возможность идентификации продуктовых наборов для повышения продаж. Сюда же можно отнести принятие мер для увеличения количества заказанных предметов каждым покупателем.
- Понимание. Важная задача кластеризации – это повышение уровня понимания «ситуации». Деление разрозненных данных на отдельные сегменты дает возможность понять, какие именно сведения собраны. Все это благоприятно сказывается на дальнейшей обработке. Пример – применять к каждой получившейся «группе» определенные методы анализа.
- Расширение. Рассматриваемая «технология» приводит к тому, что при сборе информации каких-то общих признаков больше, а каких-то – меньше. При кластеризации данных удается предположить отсутствующие признаки у других компонентов «сегмента». Пример – известно, что клиенты-мужчины проводят на сайте 15 минут в среднем. Если на сервисе появляется человек с неизвестным временем, можно предположить, что для него тоже время пребывания на веб-проекте составляет 15 минут.
Существуют различные алгоритмы кластеризации данных. Википедия указывает на то, что они применяются для самых разных ситуаций на практике. Если знать, как грамотно кластеризовать информацию, аналитик сможет быстро добиться колоссальных успехов.
Алгоритмы – классификация
Алгоритмов кластеризации данных очень много. Чтобы лучше разобраться в них, сначала необходимо рассмотреть классификацию соответствующих процессов. Она называется методами кластеризации данных. Включает в себя несколько «классов» анализа:
- Вероятностный подход. В данном случае предполагается, что каждый из имеющихся объектов относится к одному из имеющихся сегментов (классов) по умолчанию.
- Подходы с применением искусственного интеллекта. Это – одна их самых больших групп методов кластеризации с точки зрения методологии. Для изучения информации здесь используются различные технологии искусственного интеллекта.
- Иерархические подходы. Такие алгоритмы кластеризации предполагают наличие вложенных групп – кластеров различного порядка. Здесь можно выделить два algorithms – объединительные и разделяющие (агломеративные и дивизионные соответственно). В иерархических методах используется система вложенных разбиений. На выходе получится дерево кластеризации, корнем которого выступает вся выборка. Листья – это самые мелкие сегменты.
Конкретной классификации, которая помогла бы явно определить методы кластеризации, нет. Предложенный выше вариант является условным, но именно он чаще всего встречается на практике.
Обзор алгоритмов
Алгоритмов кластеризации очень много. Они могут разделяются не только по методам, но и на подгруппы. Каждый предложенный ранее «тип» кластеризации будет рассмотрен более детально.
Иерархические
Среди алгоритмов кластеризации иерархического типа выделяют два основных «класса»: восходящие и нисходящие. Второй вид алгоритма (algorithms) работают по принципу «снизу–вверх»: в самом начале все объекты размещаются в одном сегменте. Этот «блок» в процессе анализа разбивается на более мелкие разделы.
Среди восходящих алгоритмов кластеризации поддерживается другой принцип. Сначала каждый объект размещается в отдельном сегменте. «Блоки» в процессе изучения информации объединяются в более крупные. Это происходит до тех пор, пока в процессе clustering все элементы выборки не будут включены в один и тот же «раздел». Это способствует формированию вложенных разбиений. Классический пример иерархического алгоритма кластеризации данных – это дерево классификаций животных, а также растений.
Для того, чтобы вычислить расстояние между кластерами, используются два подхода: одиночные и полные связи.
Недостаток у иерархических кластеров заключается в том, что здесь поддерживается система полных разбиений. Для некоторых задач соответствующий прием может оказаться лишним.
Квадратичная ошибка
Задачей кластеризации является построение оптимального разбиение объектов на отдельные «самостоятельные» группы. Оптимальность определяется в качестве требования минимизации среднеквадратичной ошибки разбиения:

Здесь Cj – это «центр масс» кластера j (точки со средними значениями характеристик для определенного сегмента).
При использовании квадратичной ошибки в процессе кластеризации (анализа данных) необходимо помнить – Википедия описывает соответствующие концепции в качестве плоских. Наиболее распространенным вариантом здесь является метод k-средних.
Он включает в себя процесс построения заданного числа кластеров, которые должны располагаться как можно дальше друг от друга. Делится процесс на несколько этапов:
- Случайно выбирается k точек, которые выступают начальными «центрами масс» кластеров.
- Каждый объект относится к сегменту с ближайшим «центром масс».
- Производится пересчет «центра масс» сегментов согласно новому составу.
- Если критерий остановки of clustering algorithm достигнут, процедура расчетов заканчивается. В противном случае система должна снова соотносить объекты с ближайшими «центрами масс», вернувшись к шагу 2.
Википедия указывает на то, что критерием остановки работы данной концепции кластеризации объектов выбирают минимальное изменение среднеквадратической ошибки. Случается так, что остановка алгоритма произойдет на 2 шаге. Это происходит, если на нем не было объектов, которые переместились из одного сегмента в другой.
Недостаток соответствующей концепции, помогающей кластеризовать информацию, является необходимость задавать множества кластеров (clusters) для разбиения.
Нечеткие алгоритмы
Здесь наиболее популярным вариантом является метод c-средних. Он представляет собой модификацию k-средних. Работает так:
Сначала необходимо выбрать начальное нечеткое разбиение n объектов на k сегментов. Это делается при помощи матрицы принадлежности U с размером n x k.
При помощи матрицы U отыгрывать значение критерия нечеткой ошибки:
. Тут Ck – это «центр масс» нечеткого сегмента k. Он определяется по формуле:
.
- Произвести перегруппировку объектов. Это нужно для того, чтобы уменьшить значение соответствующего критерия нечеткой ошибки.
- Возвращаться ко второму шагу до тех пор, пока изменения, произошедшие в матрице U, не станут незначительными.
Данная концепция кластеров данных не подойдет тогда, когда заранее неизвестно количество сегментов классификации. Algorithm не используется в ситуациях, при которых требуется однозначно отнести каждый компонент в один кластер.
Теория графов
Алгоритм кластеризации, базирующийся на теории графов, заключается в том, что выборка компонентов представлена в виде графа G = (V, E). Его вершинами выступают объекты, а ребра имеют вес, равный «расстоянию» между компонентами.
Этот cluster analyze имеет значительное преимущество – наглядность. Он относительно простой в плане реализации. Поддерживает возможность внесения разнообразных изменений, базирующихся на геометрических соображениях.
Особой популярностью в «теории графов» при кластерах множеств пользуется выделение связанных компонент. Аналитики часто пользуются построением минимального покрывающего дерева, а также послойную кластеризацию.
Выделение связанных компонент
Задачи кластеризации понятны и конкретны. Алгоритмов реализации соответствующих процессов очень много. Еще один пример – это метод выделения связанных компонент. В нем задается входной параметр R, а в графе удаляются все ребра, для которых расстояния больше R.
Соединенными будут только самые близкие объектные пары. Смысл соответствующей концепции заключается в том, чтобы подобрать такое R, лежащее в диапазоне всех «расстояний», при котором граф распадется на несколько связанных компонент. Полученные компоненты – это и есть cluster.
Для подбора параметра R обычно используется гистограмма распределений попарных расстояний. Если пример кластеризации имеет ярко выраженную структуру информации, на гистограмме образуются два пика. Один из них будет соответствовать внутрикластерным расстояниям, второй – межкластерным. Параметр R должен быть выбран из зоны минимума между соответствующими пиками. Управлять количеством сегментов при помощи порога расстояния весьма проблематично.
Минимальное покрывающее дерево
Этот алгоритм кластеризации сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. Ниже – наглядный вариант отображения метода. Этот пример кластеризации указывает на минимальное покрывающее дерево, полученное для 9 объектов:
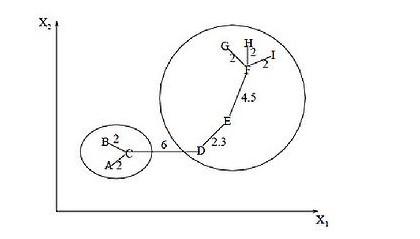
Здесь:
- Путем удаления связи CD с длиной 6 (ребро с максимальным расстоянием) удается получить несколько сегментов в имеющихся образцах.
- Сегменты – это A, B, C и D, E. F, G, H, I.
- Второй «блок» в процессе изучения может быть разделен еще на несколько за счет удаления ребра EF с длиной 4.5 единиц.
Соответствующий прием позволяет в наглядной и относительно простой форме кластеризовать информацию.
Послойный прием
С задачами кластеризации, их целями и основными концепциями уже удалось ознакомиться в общих чертах. Есть еще один алгоритм, который достаточно часто встречается в обыденной жизни и аналитике. Это – послойное деление на сегменты.
Он основывается на выделении связанных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается погром расстояния C. Пример – если соответствующий параметр равняется , то
.
Алгоритм послойного сегментирования формирует последовательность подграфов графа G. Они отражают иерархические связи между кластерами:
где Gt = (V, Et) – это граф на уровне ct,
где:
- ct – это t-ый порог расстояния;
- m – количество уровней иерархии в заданной системе;
- Go = (V, o), o – пустое множество ребер графа, которое будет получено при t0 = 1.
- Gm = G. Это граф объектов без ограничений на расстояние (длину ребер графа). Связано это с тем, что tm = 1.
Этот метод кластеризации включает в себя возможность контроля глубины иерархии получаемых сегментов. Послойная «классификация» позволяет создавать не только плоское разбиение информации, но и иерархическое.
Искусственный интеллект
Этот вариант включает в себя нечеткую кластеризацию C-средних, а также несколько других концепций. Наиболее известными выступают:
- Нейронная сеть Кохонена. Это класс нейронных сетей со слоем Кохонена. Он включает в свой состав линейные формальные нейроны.
- Генетический алгоритм. Базируется на поиске, который применяется при решении задач оптимизации и моделирования за счет случайного подбора вариации и комбинирования искомых параметров.
Другие методы с использованием искусственного интеллекта тоже есть, но они встречаются гораздо реже.
Сравнительная характеристика алгоритмов
Ниже можно увидеть таблицу, которая показывает основные сходства и различия рассмотренных ранее концепций разделения информации на сегменты:
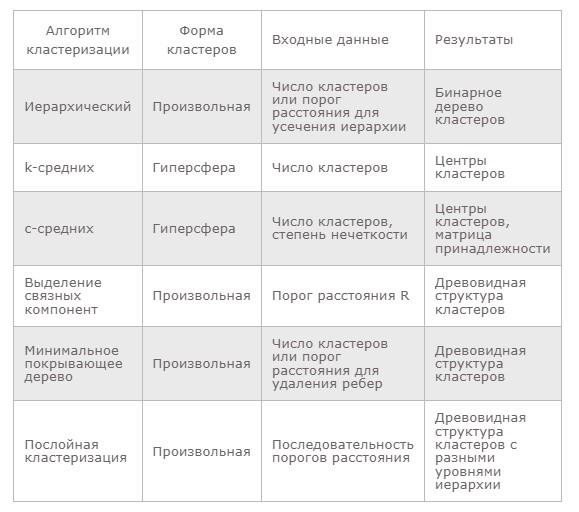
Кластеры данных рекомендуется использовать в различных сферах деятельности. Этот прием особо важен для рекламы – когда требуется направить расходы в «нужное» русло и так, чтобы добиться максимальной эффективности. Именно сегментация позволит выяснить, на что потратиться.
Самостоятельно разобраться с рассмотренной тематикой бывает проблематично, особенно если раньше человек не занимался анализом. Лучше и быстрее «с нуля» соответствующее направление помогут изучить специализированные дистанционные курсы. На них в срок до года пользователя обучат глубинному анализу информации или позволят получить инновационную IT-профессию. В конце курса ученику будет выдан электронный сертификат. С его помощью получится подтвердить приобретенные знания документально.
Прокачать свои навыки владения инструментами и технологиями работы с большими данными можно онлайн на образовательной платформе OTUS:



