
Системное администрирование и разработка программного обеспечения – области, в которых специалисты часто должны знать об особых символах и функциях, а также процессах, происходящих в различных системах, незаметных пользовательскому глазу. Пример – использование особых символов для распознавания начала и конца строки. Обычно они не печатаются и не отображаются в тексте, но системы и программы должны «знать», где начинается и заканчивается элемент.
Для этого используются так называемые регулярные выражения. Далее предстоит поговорить о них более подробно. Необходимо выяснить, что собой представляет регулярное выражение, как и для чего оно используется, в каких областях применяется. Эта информация пригодится не только новичкам, но и более опытным разработчикам/системным администраторам.
Определение
Регулярное выражение (или regexp, regular expressions) – это формальный язык, который используется в программном обеспечении, работающем с текстом. Применяется regexp для поиска и осуществления различных операций с подстроками в тексте. Базируется на внедрении специальных метасимволов (символов джокеров или wildcard characters). Для поиска используется строка-образец (маска или шаблон), которая состоит из символов и метасимволов. Она задает правила поиска необходимой информации. Для операций с текстом будет дополнительно задана строка замены, которая может включать в себя специальные символы.
Регулярные выражения в программировании – удобный метод описания текстовых шаблонов. С их помощью удается проверять пользовательский ввод, а также искать некоторые маски. Представлены regexp своеобразными «шаблонами», которые будут использоваться для сопоставления символов в строках. Встречаются в различных языках разработки.
Пример – в JavaScript рассматриваемые шаблоны используются в методах и объектах:
- test;
- exec;
- string;
- match;
- search;
- replace;
- regexp.
Далее регулярка будет рассмотрена на примерах Python и JavaScript. Это поможет быстрее разобраться в том, как определиться конец строки, а также воспользоваться соответствующими данными для редактирования информации и совершения иных операций.
Что можно сделать при помощи regexp
Регулярка в программировании и системном администрировании – полезный компонент. При помощи регулярных выражений можно:
- проверять, что вводит пользователь для уверенности в корректности информации (пример – правильно ли человек указал телефон, IP-адрес или e-mail);
- производить замену по заданному шаблону;
- быстрее оперировать данными и управлять ими на профессиональном уровне;
- разбивать текст на небольшие куски (пример – выбирать данные из крупного лога).
Регулярка поддерживается большинством текстовых редакторов, а также языков программирования.
Синтаксис
Синтаксическая запись регулярных выражений является простой и понятной. Она включает в себя символ, который выступает в качестве разделителя (он указывается в начале и конце выражения), а также шаблон поиска и необязательные модификаторы. Выглядит форма записи regexp так:

В качестве разделителя может выступать любой символ. Обычно это «/» или «~». Главное, чтобы строка шаблона начиналась и заканчивалась одним и тем же символом. В конце regexp указываются модификаторы. Они требуются для изменения логики работы имеющихся шаблонов.
Вот наглядный пример строки на изучаемом языке: / Мы пошли гулять одни/ ugi. Здесь:
- / – начальный символ, выступающий в виде разделителя строки;
- «Мы пошли гулять одни» – поисковый шаблон;
- / – символ, указывающий на конец строки;
- ugi – модификаторы (UTF-8, global, case insensitive).
Соответствующая запись в строке будет искать текст «Мы пошли гулять одни», независимо от регистра по заданному тексту неограниченное количество раз. U – модификатор, который явно указывает на то, что текстовые данные написаны на Unicode (содержат символы, отличающиеся от латиницы). I используется для регистронезависимости во время поиска. Если написать этот символ в строке, система будет искать по шаблону информацию, независимо от типа регистра. G – модификатор, который указывает поисковику на то, что нужно идти в процессе выполнения задачи до самого конца документа. В противном случае система прекратит операции при первом обнаруженном совпадении в строке.
В программировании
Отдельное внимание regex рекомендуется уделить непосредственно в разработке программного обеспечения. В Python соответствующий компонент представляет некоторое выражение, представленное в виде последовательности команд. Составляется такая запись при помощи специальных метасимволов. Они будут изучены подробнее далее.
Стоит обратить внимание на то, что регулярные выражения (regular expressions) во время проверки (поиска) информации будет учитывать регистр. Буквы «ё» и «Ё» не входят в имеющиеся алфавитные диапазоны. Чтобы обнаружить их в строке, потребуется указывать соответствующие компоненты отдельно.
В JavaScript регулярные выражения могут быть созданы несколькими способами:
- Через литералы регулярных выражений. Они вызывают предварительную компиляцию regexp при анализе имеющегося скрипта. Если используемая «команда» часто применяется, такой вариант создания поможет увеличить производительность.
- При помощи вызова конструктора объекта символьного класса RegExp. Компиляция регулярного выражения будет осуществляться непосредственно во время исполнения скрипта. Прием особо хорош тогда, когда разработчик знает, что выражение будет изменяться. Используется данная концепция и тогда, когда шаблон неизвестен заранее. Пример – получение строки из стороннего источника или путем пользовательского ввода.
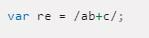

Выше можно увидеть два примера regexp соответственно. В JavaScript пользователи могут составлять шаблоны рассматриваемого компонента. Они состоят из обычных слов или комбинаций обычных и специальных символов в строке. Скобки часто используются для «запоминания». Этот знак позволяет «зафиксировать» информацию для дальнейшего использования.
Применение простых шаблонов и специальных символов
Простой шаблон используется для нахождения прямого соответствия в текстовой строке. Пример – /abc / соответствует комбинации символов в строке только тогда, когда символы abc встречаются в заданной последовательности. Это – элементарное соответствие, которое будет искать система. Набор символов, указанных в «шаблоне» не предусматривает никаких изменений. Такой поиск требуется не всегда. Обычно разработчики и системные администраторы стараются найти данные с «расширенными» параметрами.
Для этого используются специальные символы. Находить с их помощью данные удается быстрее и точнее. Пример – можно найти символы в диапазоне или без учета регистра. Запись /ab*c/ указывает на то, что искать необходимо символы, в которой за a следует ноль или более b. Символ «звездочка» указывает на ноль или более вхождений предыдущего символа в строке. Далее в используемой записи следует один символ c.
Таблицы специальных символов
Чтобы грамотно составлять регулярные выражения (regular expression), разработчику необходимо познакомиться со специальными символами. Их очень много для каждого языка. Далее будут рассмотрены основные спецсимволы в JavaScript и Python.
Для Python
Внутри «поискового шаблона» разработчик должен использовать спецсимволы для того, чтобы задавать различные параметры поиска. Вот наиболее распространенные записи:
| Символьное обозначение | Для чего используется |
| . (точка) | Соответствует любому символу, исключая новую строчку |
| [] (квадратные скобки) | Любой символ из указанных в скобках. Символьные данные разрешено задавать как перечислением, так и диапазоном через дефис. |
| [^] | Любой «знак», за исключением написанных в скобках. |
| ^ | Начало строчки |
| $ | Конец строки |
| | | Логическое или. Регулярное выражение будет искать один из нескольких вариантов. |
| \ (обратный слеш) | Экранирование. Дает возможность выражениям ориентироваться, является ли следующий за \ символ в строке обычным или специальным. |
При записи регулярных выражений часто какая-то часть заданного шаблона должна повторяться установленное количество раз. Число вхождений в синтаксисе regex задается через так называемые квантификаторы. Они всегда размещаются там, где шаблонная запись должна повториться.
| Символьная запись | Определение |
| {} (фигурные скобки) | Указывает на то, что граница слова или выражения может быть задана единичным числом или диапазоном. Цифра, указывающая на границу, указывается внутри скобок. Диапазон задается через запятую. |
| ? (вопросительный знак) | От нуля до одного вхождения |
| * (звездочка) | От нуля вхождений. «Верхняя» граница в этом диапазоне не задается. |
| + (плюс) | Одно или более вхождений. |
Заданные примеры актуальны для Python. Далее предстоит поближе познакомиться со специальными символьными записями для поиска строк и их частей в JavaScript.
В JavaScript
В случае с JavaScript пользователю предстоит задействовать аналогичные знаки для осуществления различных действий при использовании regexp. Вот то, что необходимо запомнить об их применении в JS:
| Символьная запись в строке | Описание и особенности |
| \ | может соответствовать окончанию слова – если обработка осуществляется буквально;интерпретируется буквально – если шаблон обрабатывается особым образом;требует экранирования при использовании в записи new Reg экранирующим компонентов в обычных строках. |
| ^ | Начало строки. Указывает на «момент», начиная от которого, осуществляется ввод. При установки спецсимвола многострочности (перевод строки), работает после переноса строчки. Каретки в самом начале шаблона имеет иное значение. Пример – /[^a-z\s] указывает на I в «I have 3 sisters» |
| $ | Конец ввода. Работает при переносе строки. |
| * | Соответствие предыдущему компоненту, который повторен 0 или больше раз. |
| + | Предыдущий компонент, повторенный 1 больше раз. Работает как и в Python. |
| ? | Предыдущий повторенный компонент 0 или 1 раз. При применении после квалификаторов *, +, ?, {} делает квалификатор соответствующим минимальному количеству элементов в шаблоне. |
| (…) | Соответствие с указанным в скобках компонентом. Называется такая запись «захватывающими скобками». |
| \w | Любой цифробуквенный элемент, включая подчеркивания. |
| \W | Любой компонент, который не является цифробуквенным. |
| \r | Возврат каретки |
| \n | Перевод строки |
| \f | Прогон страницы. Относится к категории управляющих символьных записей для печати. |
Здесь можно увидеть больше примеров регулярных выражений для JavaScript. Они будут одинаково хорошо работать как в Python, так и в JavaScript.
Расширенный поиск и флаги
У регулярных выражений во всех языках разработки и при системном администрировании поддерживаются опциональные флаги. С их помощью специалисты смогут задавать расширенные параметры поиска. Флаги могут использоваться самостоятельно или совместно в любом порядке. Их запись иногда – это часть регулярного выражения в сформированном запросе.
| Что за флаг (обозначение) | Краткое описание |
| g | Отвечает за глобальный поиск. Система будет проверять весь текстовых документ. |
| i | Поиск без поддержки учета регистра |
| m | Многострочный поиск |
| v | Начинает поиск от знака, который расположен на позиции свойства lastindex текущего регулярного выражения. |
Для того, чтобы использовать обозначенные флаги в шаблоне, регулярные выражения предлагают следующий синтаксис:
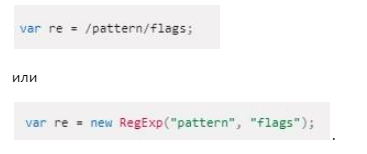
Флаги – это неотъемлемая часть регулярного выражения. Они не могут быть скорректированы позднее. Установка «уточняющих» знаков в шаблоне возможна исключительно до обработки соответствующего фрагмента.
Спецсимволы и проверка входных данных
Еще один момент, на который необходимо обратить внимание – это принцип использования спецсимволов (знаки начала строки, окончания и так далее) для проверки корректности входных данных.
Вот – пример, в котором пользователь должен ввести номер телефона. После нажатия клиентом на кнопку «Check», скрипт проверит корректность указанной комбинации. Если все верно, система сообщит об этом в виде благодарности. В противном случае появляется уведомление о том, что номер неправильный.
Внутри незахватывающих скобок (?:, регулярное выражение будет искать три цифры \d{3} или | открывающую скобку \(, после этого – три цифры и закрывающую скобку \).

Событие «Изменить» будет активировано после того, как пользователь подтвердит ввод значения регулярного выражения. Для этого потребуется нажать на клавишу «Enter».
Особенности осуществления поиска
Regexp – это инструменты для работы со строками, которые являются основной их единицей. Строка представлена рассматриваемым компонентом, а также текстом, по которому осуществляется непосредственный поиск.
Обнаруженные в тексте совпадения с заданным шаблоном – это подстроки. Пример – есть regexp м. (буква «м» и любой символ), а также строка текста «Мама мыла раму». При применении regex будут обнаружены подстроки:
- ма;
- мы;
- му.
Подстрока «Ма» будет пропущена ввиду того, что в ней используется другой регистр.
Более мелким компонентом в строке является группа. Она представляет собой часть подстроки, которая выделена специально. Группы выделяются круглыми скобками (). В Python можно сформировать на основе уже изученного примера такую строку «запроса»:

Здесь указано следующее:
- буквенный символ, выделенный группой;
- за ним – три буквенных символа, которые тоже выделены группой.
Этот шаблон представляет собой 4 буквенных символа. В строке «Мама мыла раму» будут обнаружены три совпадения. Из них система выделит две группы:
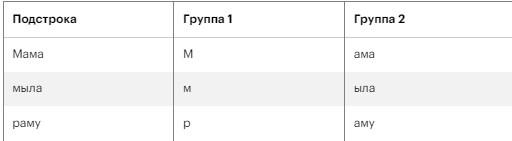
За счет такого приема удается из найденной подстроки извлечь необходимую конкретную информацию. Пример – обнаружение адреса, в котором есть: улица, номер дома и квартира. Подстрока – это «полный адрес», а в группы можно выделить отдельно каждую его структурную единицу, чтобы в будущем обращаться к соответствующим компонентам напрямую.
Группы могут получать имена. Для этого используется форма:

Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!


