
Python часто используется для машинного обучения, а также анализа данных. Для этого к языку программирования подключаются различные библиотеки: NumPy, Matplotlib, TensorFlow и так далее. Каждому, кто планирует заниматься BigData и анализом информации, рекомендуется обратить внимание на Pandas. Это функциональный инструмент для Питона, который поможет работать с данными и обрабатывать их.
Далее предстоит получше изучить библиотеку Pandas, а также один из ее важнейших компонентов – DataFrame. Предложенные ниже сведения ориентированы в большей степени на разработчиков с опытом.
Pandas – это…
The Pandas – основная библиотека Питона, предназначенная для работы с информацией и ее большими объемами. Активно применяется в аналитике и BigData. The Pandas была создана в 2008 году. С тех пор она стремительно развивается и совершенствуется. Изначально библиотека распространялась компанией AQR Capital, но через код соответствующее «программное обеспечение» получило открытый исходный код.
Сферы применения
Перед изучением Pandas Dataframe, необходимо понять, где вообще применяется рассматриваемая библиотека. Ключевых областей использования несколько:
- Аналитика информации: маркетинг, продуктовый анализ и другое. Рассматриваемый «пакет решений» для Python позволяет анализировать информацию и подготавливать ее. Некоторые процессы за счет встроенных инструментов могут быть автоматизированы.
- BigData и Data Science. При помощи Пандас разработчики и аналитики смогут подготовить, а также организовать первичный анализ BigData для дальнейшего применения в глубоком/машинном обучении.
- Статистика. В библиотеке поддерживаются ключевые статистические методы, которые позволяют оперировать информацией. Примеры – распределение значений по квинтилям, расчет средних параметров.
Большинство разработчиков, если они не углубляются в обозначенные области, могут не изучать the Python and the DataFrame Pandas. Остальным соответствующая библиотека покажется полезной, особенно если знать, как ей управлять.
Установка
Перед изучением структур информации в изучаемой библиотеке, а также способов создания for dataframe in Python, необходимо сначала установить рассматриваемый «фреймворк» на устройство. Если разработчик пользуется the Jupyter Notebook и Colab, ничего дополнительно ставить не придется. Пандас является стандартной библиотекой. Она доступна сразу после запуска Colab или Jupyter Notebook. Все, что останется разработчику – это импортировать библиотеку в имеющийся исходный код будущей программы:
import pandas as pd
PD – сокращение, которое является общепринятым у разработчиков на Питоне. Оно используется для обозначения библиотеки Пандас. Вместе с таким обозначением не придется каждый раз писать длинное «pandas» в исходном коде.
Структуры данных
The Pandas Dataframe – это одна из самых значимых структурных единиц библиотеки. Для грамотного управления и создания соответствующего объекта, каждый разработчик должен понимать структуру информации и Пандас.
Всего «фреймворк» поддерживает три вида структур данных:
- series – одномерный массив неизменного размера;
- the data frame – двумерная табличная структура с изменяемыми размерами и неоднородно типизированными столбцами;
- panel – трехмерный массив, поддерживающий изменение размерности.
Далее каждая представленная единица будет рассмотрена более подробно. Особое внимание будет уделено the data frame (датафрейм) и принципам его создания.
Series
Series (или «серии») – объект рассматриваемом библиотеки, который создан для представления одномерных структурных единиц. Они напоминают массивы, но имеют дополнительные возможности.
Структура a Series отличается of the DataFrame и является более простой. Включает в себя два массива:
- основной – тот, что содержит информацию (любого типа NumPy);
- дополнительный (the index) – включает в себя метки.
Проще всего the Series может быть представлен как столбец таблицы, включающий в себя некоторую последовательность значений. Каждый компонент имеет индекс – номер соответствующей строки.
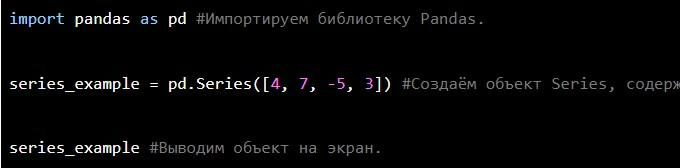
Вот так создается простой Series:
После обработки соответствующего фрагмента на экране появится следующий результат:
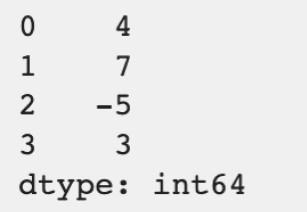
The Series будет отображаться как таблица с индексами элементов в первом столбце и с присваиваемыми значениями – во втором.
Panel
Изучая the Pandas (pd) dataframe, не нужно забывать о других структурных единицах библиотеки – без них полноценно пользоваться продуктом Питона не получится. Не самым распространенным, но встречающимся в разработке компонентом является Panel.
The Panel – это второй тип структур данных. Он является более сложным компонентом, чем Series и Pandas (pd) dataframe. Panel представляет собой панель с трехмерной структурой. Она включает в себя три оси для выполнения различных функций:
- Items – ось 0. Каждый его компонент будет соответствовать the Dataframe в нем.
- Major_axis – ось 1. Здесь наблюдается соответствие строкам каждого the Data Frame.
- Minor_axis – ось 2. Соответствует Dataframe-columns.
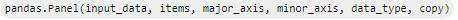
Выше можно увидеть наглядный синтаксис, при помощи которого разработчик сможет создать Panel в Пандас.
DataFrame – основной компонент
Pandas Dataframe – наиболее распространенный элемент изучаемой библиотеки. Он используется для создания основного количества баз информации. Представляет собой двумерную структуру, которая напоминает массивы. Входные данные в датафрейм оформляются как строки и столбцы.
Размер структуры Pandas Dataframe разрешено менять. Соответствующий компонент служит стандартным способом хранения информации. Он формирует базу по типу таблицы-SQL или любой другой таблицы (a table).
The Data фрейм может быть с жестко закодированными данными. Информация поддерживает импорт в CSV или TSV, а также Excel-документ, SQL-таблицу и не только.
Dataframe Data имеет следующий синтаксис:

Здесь:
- Input_data – ввод. Он может принимать списки, массивы, ряды и иные структурные дата единицы.
- Index value – значения индекса. Они будут передаваться в dataframe.
- Data type или dtype – функция, которая распознает тип используемой информации для dataframe-columns.
- Copy – копирование. Значение по умолчанию для соответствующего параметра – false (ложь, неверно).
Столбцы – это метки данных столбцов. Создавать дата фреймы можно несколькими способами. О них будет рассказано позже. Эта информация пригодится как новичкам, так и более опытным разработчикам.
Импорт информации
Изучая pandas dataframe, разработчику необходимо не только познакомиться с объектом (object) датафрейм, но и освоить принципы применения рассматриваемой библиотеки. Без соответствующих навыков программист не сможет оперировать информацией и правильно использовать ее на практике.
Изучаемый «фреймворк» поддерживает несколько способов импорта (importing) данных. Пример – считывание из словаря (a dictionary), списка или кортежа. Наиболее распространенный вариант – использование csv-документов. Они чаще всего применяются при анализе данных. Для импорта используется команда: pd.read_csv. Для оперирования импортирования the dataframe or series, поддерживаются два параметра:
- Sep. С его помощью разработчик сможет явно указать разделитель, используемый в импортированном документе. По умолчанию соответствующее значение – это символ запятой. Он используется в качестве «стандартного» разделителя в csv-документах. Sep будет особо полезен тогда, когда в исходном файле изначально применяются нестандартные разделяющие символы. Примеры – точки с запятыми или табуляция.
- Dtypes. Этот параметр дает возможность явно указать тип данный columns in csv-документ. Параметр поможет в ситуациях, когда в исходном файле автоматическое определение задействованного формата неверное. Пример – дата часто импортируется в качестве строковых переменных, несмотря на наличие отдельного типа для подобных сведений.
Стоит обратить внимание на то, что при работе в Google Colab или Jupyter Notebook для вывода Dataframe data или Series на дисплей устройства не нужно использовать команду print. Пандас умеет отображать сведения без нее. При формировании a function print(df), табличная верстка будет утрачена.
Методы для статистического анализа
A dataframe from Pandas (pd) часто используется для того, чтобы анализировать различные массивы данных. Для нормализации работы с библиотекой разработчикам приходится применять встроенные методы. Они дают возможность быстро и качественно выполнять аналитические операции.
В Pandas очень много разнообразных методов для анализа data (дата). Далее представлены наиболее распространенные из них:
| Что за метод (название) | Описание |
| Count | Подсчет всех непустых наблюдений. На выходе система передаст количество соответствующих компонентов. |
| Mean | Возврат среднего значения всех элементов |
| Sum | Сумма всех компонентов данных |
| Median | Получение медианного параметра |
| Mode | Отвечает за возврат режа всех информационных компонентов |
| Std | Стандартное отклонение |
| Min | Минимальный компонент среди всех входных информационных единиц |
| Max | Максимальный элемент среди всех входных |
| Prod | Произведение имеющихся значений данных |
| Abs | Абсолютное значение |
| Cumprod | Совокупное произведение значений |
| Cumsum | Кумулятивная сумма |
| Describe | Отображение статистической сводки всех записей за один снимок (сумма, количество, минимумы и максимумы, средние значения и так далее). |
Таблица, представленная выше, поможет быстрее анализировать in the dataframe data, а также управлять соответствующими сведениями. Это не все методы, которые используются библиотекой, но они встречаются в разработке и аналитике чаще остальных.
Как создать DataFrame – обзор методов
Структура the dataframe of PD – это rows and columns (строки и столбцы). Лучше всего представлять соответствующий компонент в виде «стандартной» таблицы, которая заполнена различными материалами. Существуют различные способы создания (creating) дата фреймов. Они могут быть сформированы на базе:
- других дата frames;
- структурные единиц типа Series;
- структурированных ndarray;
- двумерных ndarray;
- словарей, в качестве элементов которого выступают списки, одномерные массивы (array), другие словари и Series.
Далее предстоит познакомиться с (with the) различными методами формирования Pandas a Dataframe-columns и the rows. Предложенные ниже концепции являются универсальными. Они помогут разработчикам быстро ориентироваться в оптимальном решении для конкретного анализа и приложения.
Пустой фрейм
Программист может создать (creation) пустой frame. Это «стандартный» случай, для которого не потребуется никаких дополнительных знаний. Для формирования пустого информационного фрейма достаточно воспользоваться вызовом стандартного конструктора:
# Импортирование библиотеки
import pandas as pd
# Вызов конструктора
df = pd.DataFrame()
print(df)
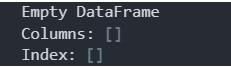
Выше – наглядный пример кода, а также результата его обработки. Create a dataframe without data (создание пустого датафрейма) – операция, которая в практических задачах используется не слишком часто. Это элементарный случай. Есть и другие методы сделать (to create) dataframe data.
Добавление столбцов
Основная единица измерения датафрейма – это the column (столбцы). Доступ к ним всегда является более прямой, чем к строкам (rows). При помощи обычной скобочной нотации обращение к столбцам осуществляется раньше, чем к строкам. Это противоречит общей практике.
Добавить новый столбец в the DataFrame можно путем присваивания ему значений, которые должен иметь столбец. Операция производится подобно работе со словарями и скобочными нотациями.:

Выше – пример, где отсутствуют значения. Из-за этого в первой строке указывается None. Фактически это – пустой фрейм.
Еще один способ добавления столбцов (dataframe-columns) является применение функции assign. Она дает возможность добавлять колонки к уже созданным. В исходный датафрейм информация не вставляется. Вместо этого система добавляет новый the Dataframe, который включает не только старые столбцы, но и новые:

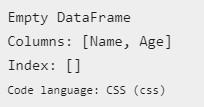
Стоит обратить внимание на то, что при назначении уже существующих dataframe-columns происходит перезапись их значений. В представленном примере из-за этого не случится ничего страшного, потому что изначально фрейм пустой.
При помощи словаря
Creates the dataframe через одномерный словарь – более распространенная ситуация. В этом случае компонентами the dict будут выступать списки и структуры Series. Сначала разработчику потребуется создать Series:

Далее потребуется построить аналогичный словарь, но базирующийся на компонентах ndarray:
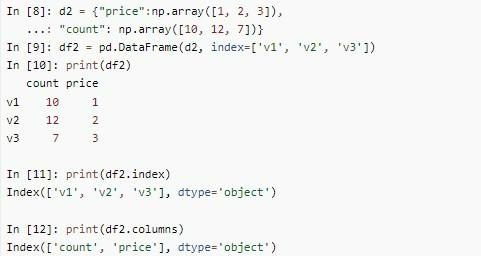
Можно заметить, что результаты будут одинаковыми. Вместо ndarray допускается использование обычного списка из Питона.
Из массива
Еще один способ формирования the Pandas dataframe – выгрузка из массива. Чтобы лучше понять соответствующий принцип, рекомендуется изучать его на наглядном примере. В качестве массива с информацией будет использоваться data.
Для формирования DataFrame потребуется вызвать конструктор и передать его в качестве параметра список data. Для этого используется DataFrame(data). Соответствующая команда будет возвращать объект Датафрейм, созданный с заданными параметрами. Его можно использовать для дальнейших операций.
Вот – массив, который состоит из трех списков, в каждом из которых по 4 значения. Они образовывают следующую таблицу:

Из него формируется ДатаФрейм. Для этого рекомендуется воспользоваться следующим фрагментом кода:

При выводе результата на экран отобразится следующая ситуация:
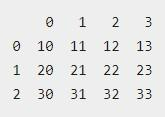
Стоит обратить внимание на следующие особенности концепции создания the dataframes:
- Каждая строка будет соответствовать каждой строке в исходном документе с массивом.
- Если нужно, чтобы каждая строка (string) в заданном множестве значений отображалась как столбец в the Pandas Dataframe, потребуется поменять столбцы и строки местами при создании рассматриваемого компонента.
- Для того, чтобы поменять столбцы и строки, используется функция transpose (df = pd.DataFrame(data).transpose().)
- Если необходимо задать собственные имена столбцов (dataframe-name), допустимо добавить новый параметр. Он называется columns и пишется в вызов конструктора. В нем останется перечислить желаемые «названия».
Запомнить все эти правила, еще один метод создания Датафреймов будет полностью понятен. Но рассмотренные приемы не являются исчерпывающими. Существуют иные методы, которые помогут create the dataframe.
Список словарей
Для создания Датафрейма из списка словарей необходимо предоставить список (list) конструктору класса через: DataFrame(list). Соответствующий вызов вернет объект ДатаФрейм, который включает в себя информацию из списка с ключами, которые выступают именами столбцов.
Вот – наглядный пример фрагмента кода с рассматриваемым решением:
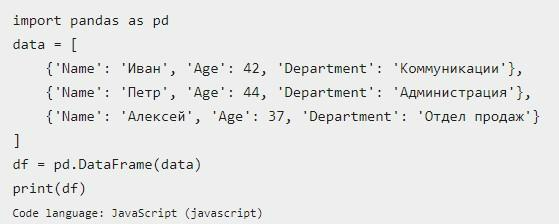
И результат обработки:
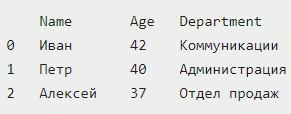
Основная проблема рассматриваемого подхода к create DataFrame при помощи списка словарей заключается в том, что разработчик должен убедиться в ключах. В каждом предложенном dict они обязательно должны быть согласованными друг с другом, а также корректными.
Целевой дата фрейм получит столько столбцов, сколько в словарях размещается уникальных ключей. Пример – ключ, который связан с именем. В одном словаре он отображается как Name, во втором – name, в третьем – NAME. В конечном итоге разработчик получит три разных колонки (регистр принимается во внимание) для информации об имени. Такая ситуация часто доставляет определенные проблемы для анализа. Множество значений в результирующем фрейме окажется None.
Массив NumPy
Иногда требуется обработать pd-dataframe-columns, которые расположены внутри массива NumPy. Для такого случая программист должен вызвать конструктор через DataFrame(array). Чтобы задать имена столбцов, они должны быть прописаны в отдельном параметре функции – columns.

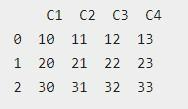
Каждая строка массива исходных данных будет полностью соответствовать DataFrame. Перед использованием соответствующего приема разработчик должен убедиться в наличии инициализированной библиотеки NumPy. При ее отсутствии – провести предварительную установку, иначе метод работать не будет.
Из CSV-документа
Работа с CSV-файлами при анализе информации и в BigData – явление, которое не удивляет разработчиков. Поэтому достаточно часто приходится формировать фреймы через заранее подготовленные документы.
CSV или Comma Separated Value представляет собой текстовый документ в виде таблицы. Его значения разделены специальными символами. По умолчанию – запятыми. Такие документы часто имеют первую строку, выступающей в виде заголовка с именами имеющихся столбцов.
Чтобы создать при помощи такого приема Pandas-dataframe-columns, можно пользоваться одной из нескольких функций:
- read_table;
- read_csv.
В соответствующих командах потребуется указать имя файла, откуда осуществляется импорт данных, а также символ-разделитель.
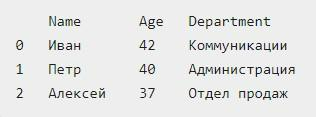
Вот – исходный текстовый документ. Он будет называться как data.csv:

Из них при помощи обоих предложенных методов будет осуществляться create dataframe. Первый подход – это применение функции read_csv. Она разработана специально для упомянутого формата текстовых документов. Поддерживает большое количество функций, но для простых документов достаточно указать только название исходного документа, а также тип используемого в нем разделителя. В рассматриваемом примере ей служит символ запятой.

В этом же случае допускается применение read_table. Она будет работать точно также, как и read_csv.
Стоит обратить внимание на то, что иногда разработчику требуется отдельно задавать подписи для pandas-dataframe-columns. В этом случае предстоит пользоваться дополнительным параметром. Он называется name и имеет такую форму записи:
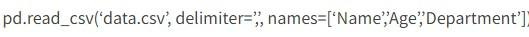
Если программисту в результирующем фрейме не требуются имена столбцов, параметры задаются как header=None.
Из буфера обмена
Иногда у аналитика или разработчика имеются данные в табличном формате, которые разделены запятыми или иными разделяющими символами. Они скопированы в буфер обмена и могут быть использованы для считывания изучаемой библиотекой.
Еще один способ формирования pandas-pd-dataframe – это копирование информации прямо из буфера обмена устройства. Отдельный документ с исходными данными формировать в этом случае не придется.
Создание фрейма из буфера позволяет динамически, а также достаточно быстро получать информационные фреймы из материалов различных источников.
Чтобы в Pandas create-dataframe из значений, которые разделены запятыми и скопированы в буфер обмена устройства, используется функция read_clipboard. Дополнительно предстоит указать разделяющий символ.
Вот – информация, которую предстоит скопировать в буфер устройства для дальнейшей обработки изучаемым методом:

Теперь остается записать в программном коде следующее:
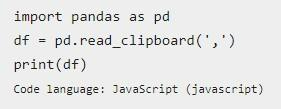
Если разделитель строк dataframe не выступает в качестве одного или нескольких пробелов, желаемый символ или строка (the strings) должны быть обязательно указаны. Для этого разработчик передает параметр функции. В круглых скобках между кавычками-черточками указывается желаемый символ-разделитель. Если функция вызывается без параметров, по умолчанию в итоговом фрейме разделителем выступает пробел.
HTML-документ или веб-страница
В Pandas DataFrame может быть сформирован еще проще – при помощи веб-страниц и HTML-документов. Для этого предстоит использовать функцию read_html. В ней разработчик указывает исходный HTML-документ или URL, который предстоит считать. Указанная команда будет искать теги, а затем формировать информационный фрейм с каждой из таблиц в исходном документе.
Read_html ищет теги:
- table;
- tr (строки);
- th (заголовки);
- td (данные).
из них для каждой таблицы будет генерироваться фрейм. Связано это с тем, что рассматриваемая функция всегда будет возвращать список со сгенерированными DataFrames.
Стоит обратить внимание на то, что для корректной реализации рассматриваемого приема требуется подключить библиотеку lxml. Она помогает не в непосредственном pandas-create-dataframe, а в обработке и разборе XML/HTML-документов в Питоне.

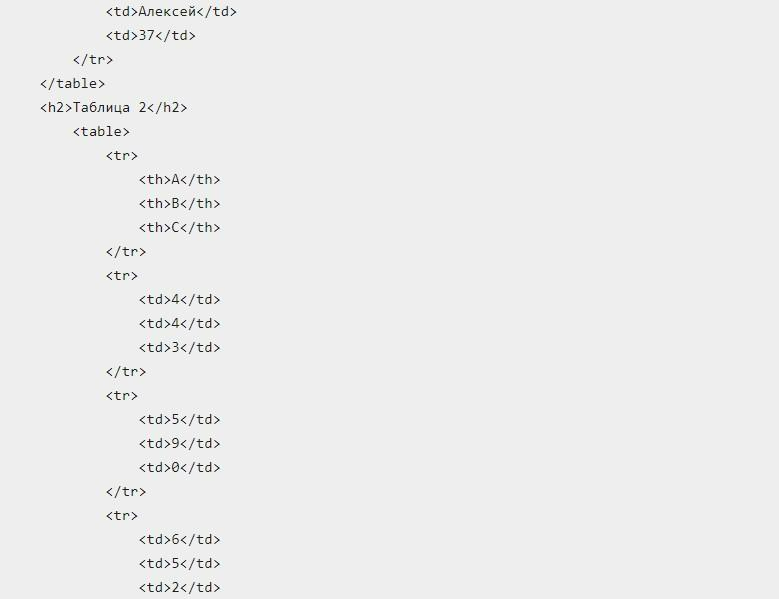

Выше – HTML-файл, с которым планируется дальнейшая работа в процессе изучения метода создания информационного фрейма. В нем поддерживаются две разные таблицы. Документ будет называться – data.html.
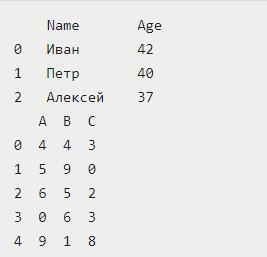
Представленный файл рекомендуется открыть в браузере, чтобы увидеть, что в нем хранится. В этом примере формируется pandas-dataframe-name с двумя объектами: по одному для каждой исходной таблицы в data.html. Далее соответствующий список должен быть выведен на дисплей:

Чтение при помощи библиотеки lxml может оказаться неудачным. В соответствующем случае будут использоваться html5lib, а также bs4. Для этого они должны быть заранее установлены на устройстве разработчика. Если необходимо выполнить чтение конкретной библиотекой, рекомендуется воспользоваться параметром flavor. В нем указывается lib, необходимая для непосредственного применения.
Из Excel
Рассматриваемый тип информационной структуры может быть охарактеризован как «таблица». Пользователи часто работают с Excel, поэтому the Pandas dataframe может быть сформирована из Excel-таблиц. Допускается работа с совместимыми электронными таблицами. Пример – созданные через пакет LibreOffice.
Для выполнения операции используется функция read_excel, в котором указывается файл, из которого необходимо считать исходные материалы. Формат предложенного далее примера – data.xlsx. Эта таблица была создана через GoogleDrive и сохранена.
Функция read_excel при считывании data for dataframe, будет использовать другую библиотеку. Она напрямую зависит от типа формата исходной таблицы. Для Excel – это openpyxl. Она должна быть установлена предварительно через pip. При работе с форматом Open Document Format, используется библиотека odf.
Когда все готово, можно формировать dataframe columns при помощи такого фрагмента кода:
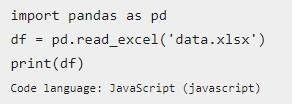
А вот – результат обработки команды:
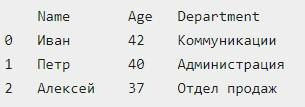
Может получиться так, что таблица, необходимая для чтения, расположена в определенной строке и столбце документа. Эта ситуация требует указания того, какие строки должны быть проигнорированы (через skiprows). Также предстоит указать, какие столбцы являются обязательными для чтения при помощи параметра usecols.
Иногда таблица, которую необходимо сформировать в виде фрейма, располагается на первом листе документа. Чтобы указать его, используется параметр sheet_name. Можно прописывать «лист поиска» как цифрой, так и непосредственным названием. Первый такой «элемент» указывается как 0.
Из JSON
Хранение информации в формате JSON является достаточно популярным методом организации данных. Его тоже допустимо использовать, чтобы сформировать pandas-dataframe-name. За операцию отвечает функция read_json. Ей передается имя исходного документа. После обработки «запроса» система создаст новый дата фрейм с желаемым спектром информации.
Вот – исходный текст документа, сохраненного в формате JSON:

Теперь остается воспользоваться упомянутой функцией:

Результат тут будет точно таким же, как и в предыдущих примерах.
Из SQL-базы
Более сложный пример формирования dataframe-data – из SQL-таблиц. Для этого могут использоваться:
- read_sql;
- запрос на создание и соединение с БД.
Для примера рекомендуется рассмотреть ситуацию, при которой поддерживаются две таблицы в БД. Они будут разными: для сотрудников и для отделов. В первом случае будут столбцы:
- код;
- имя;
- возраст;
- код отдела.
В таблице отдела отображаются столбцы: код отдела, название, местоположение. Задача – создать информационный фрейм, в котором содержатся столбцы обеих таблиц. В качестве параметра объединения служит «код отдела».

После создания БД остается сформировать несколько Pandas Dataframe. Первый вариант – прямой. Он заключается в загрузке фреймов с каждой таблицы. Для этого используется команда read_sql. В ней указываются два параметра: имя считываемой таблицы, а также строка подключения к базе данных:

Если действовать через SQL-запрос, предстоит выполнить следующее:

Read_sql дает возможность задавать запросы для получения нужных данных и их дальнейшего применения. Достаточно указать SQL-команду вместе табличного имени.
Здесь и тут можно увидеть больше наглядных примеров работы с ДатаФреймами в Пандас. А лучше изучить их с нуля помогут дистанционные компьютерные курсы.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!
Также, возможно, вам будут интересны следующие курсы:




