
Хранение данных может быть организовано разными способами. Один из вариантов – использовать двоичное дерево. Соответствующий прием позволяет обойти ограничения, действующие в линейной структуризации информации. В последней не поддерживается возможность быстрого поиска компонентов одновременно. У бинарных деревьев соответствующая «опция» есть.
Сегодня предстоит изучить двоичные древа получше. Необходимо выяснить, что они собой представляют, для каких целей используются. Также предстоит изучить основные составляющие деревьев.
Определение
Дерево – это структура данных, которая представляет собой древовидную структуру в виде некоторого набора связанных между собой узлов.
Бинарное дерево – конечное множество элементов, которое или пусто, или содержит в себе элемент (корень), связанный с двумя разными бинарными древами. Это – левое и правое поддерево. Каждый элемент здесь выступает в качестве узла. Связи между ними – это ветви.
Бинарные деревья – иерархические структуры данных. В них каждый узел может иметь не более двух потомков (детей). Обычно первый компонент выступает в качестве «родителя», а «дети» – это правые и левые наследниками. Такая информационная структура является упорядоченным ориентированным деревом.
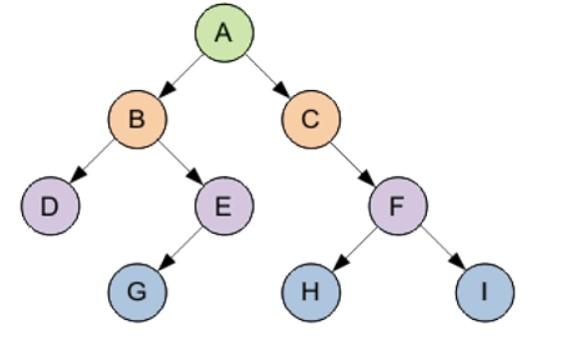
Выше можно увидеть графическую интерпретацию рассматриваемого компонента. Здесь:
- A – корень;
- B – корень левого поддерева;
- C – корень правого поддерева.
Корень всего древа располагается на уровне с минимальным значением.
Связанные определения
На примере ранее представленного бинарного дерева стоит познакомиться с несколькими связанными с этим элементом терминами. Они помогут лучше разобраться в двоичных информационных структурах и работать с ними.
Так, узел D в ранее представленном примере расположен непосредственно под узлом B. Он называется потомком. Если D размещается на уровне i, то B – на уровне i-1. B выступит в качестве предка D.
Глубиной или высотой древа называется максимальный уровень элемента рассматриваемой структуры. Если элемент не имеет потомков, он будет называться листом или терминальным узлом. Остальные составляющие – внутренние узлы (узлы ветвления).
Степень узла – это число потомков внутреннего узла. Максимальная степень всех имеющихся в структуре узлов – степень двоичного дерева. Длина пути – это количество веток, которое необходимо пройти в направлении от корня к узлу. Корень обладает нулевой длиной пути, узел на уровне i – длину, равную i.
Области применения
Иерархические структуры (деревья) широко используются. Они пригодятся тогда, когда в точке вычислительного процесса необходимо принять одно из двух возможных решений. В реальной жизни оно встречается повсеместно.
Наиболее распространенной задачей, решаемой через деревья, является выполнение операции p с каждым элементом древа. В качестве p рассматривается параметр более общей задачи посещения всех компонентов структуры или задачи обхода имеющегося дерева.
Виды
Двоичное дерево можно построить для принятия оптимального решения из заданного спектра. Оно может быть нескольких видов:
- Завершенное. У него каждый уровень, кроме последнего, является полностью заполненным. Заполнение последнего уровня производится в направлении слева направо.
- Полное. Такие бинарные деревья предусматривают у каждого узла два или ноль дочерних компонентов.
Оба подвида древовидных структур активно используются на практике. Они носят названия деревьев поиска и бинарных куч. Далее эти структуры будут рассмотрены более детально.
Древо поиска
Двоичное дерево поиска значительно отличается от обычных древ, упомянутых ранее. Они будут хранить информацию в отсортированном виде. Соответствующая операция организована по следующим принципам:
- значения в узлах левого дочернего поддерева меньше значения «родителя»;
- значения в узлах правого дочернего поддерева больше значения «родителя»;
- каждый дочерний узел – это тоже двоичное древо поиска.
За счет такой концепции хранения данных поиск информации занимает O(logN). Это намного меньше, чем при хранении информации в виде списков – O(N).
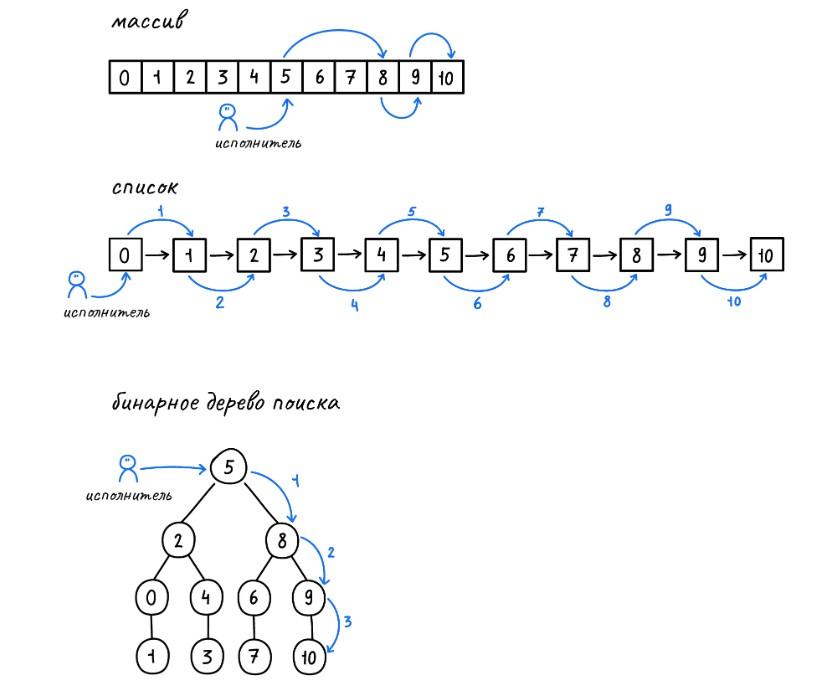
Выше – наглядная интерпретация двоичного древа поиска и пример массива, с которым предстоит работать. Поиск здесь осуществляется при помощи метода половинного деления – дихотомии. Выше можно заметить, что аналогичная операция и на массиве, и на дереве поиска будет выполняться за 3 шага. В списке подобная операция отнимет 10 шагов.
Реализация в коде
Строить рассматриваемую структуру предлагается не только графически или от руки, но и в виде программного кода. Она встречается в Java, Python и других языках программирования. Перед ее построением необходимо помнить о таких правилах как:
- дочерних узлов у дерева должно быть не больше двух штук;
- дочерние узлы должны быть бинарными древами;
- дочерние узлы называются правыми и левыми – в зависимости от их расположения.
В указанных условиях изучаемый компонент будет иметь следующую интерпретацию в программном коде:

А вот так – на Java и Python соответственно:


Теперь необходимо расширить имеющийся класс и реализовать в нем операции для взаимодействия с проектируемым классом.
Операции над древами поиска
Над двоичными деревьями поиска допустимо выполнять разнообразные операции. К ним можно отнести:
- поиск;
- вставку узла;
- удаление узла;
- выполнение обхода дерева.
Каждая представленная операция имеет свои ключевые особенности. Все перечисленные манипуляции предстоит изучить более подробно.
Поиск
Если искомое значение древа поиска меньше узлового значения, оно может размещаться только в левом поддереве. Если необходимый параметр больше узлового, оно расположено только в правом поддереве. Все это приводит к возможности использования рекурсивного подхода и операции поиска так:



Выше представлена не только структура, но и реализация поиска на Java и Python соответственно. Остальные операции над древами будут тоже базироваться на применении упомянутых языков разработки соответственно.
Вставка
Все значения дерева, которые меньше текущего узлового, допустимы для размещения только в левом поддереве. Те, что больше, – в правом. Для вставки нового узлового параметра требуется проверить текущий на отсутствие пустоты. Далее возможны два варианта развития событий:
- Если узловой параметр не пустой, его значение сравнивается со вставляемым. В зависимости от полученного результата проводится проверка правого или левого поддеревьев.
- Если узловой параметр пуст, создается новый. Он заполняется ссылкой на текущий узел в качестве родительского компонента.
Вставка пользуется рекурсивным подходом подобно поиску. Вот так выглядит этот алгоритм на JavaScript, а также на Java и Python соответственно:



Другие операции над двоичными деревьями поиска и их компонентами тоже возможны. Речь идет об удалении элементов и обходе древа.
Удаление
Для удаления компонента в связанном списке требуется отыскать его, а также ссылку на следующий компонент перенести в поле ссылки на предыдущем. Если нужно удалить корневой узел или промежуточные вершины с сохранением общей структуры древа, предстоит выбрать один из нескольких методов.
А именно:
- найти и удалить максимальный компонент левого поддерева. Его значение должно будет использоваться в качестве корневого или промежуточного узла дерева;
- найти и удалить минимальный элемент правого поддерева. Соответствующий параметр выступит корнем или промежуточным узлом дерева.
Оба варианта работают достаточно эффективно. Ниже – пример, для которого будет реализовано непосредственное удаление.
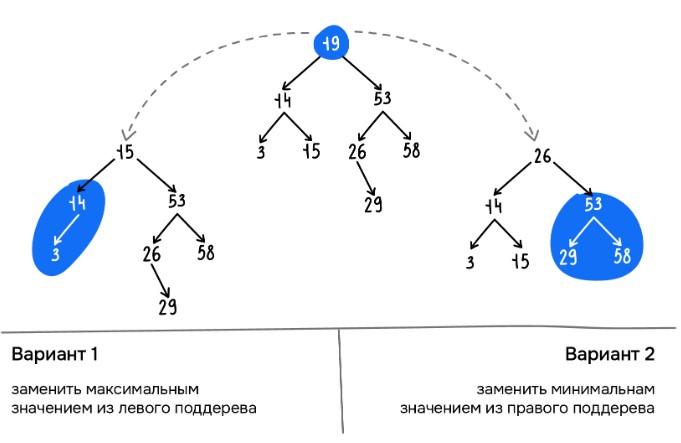
А вот примеры кодов, позволяющие реализовать второй подход на JS, Java и Python соответственно:



Первый вариант будет практически таким же. Только придется столкнуться с исключением – обходить в дереве нужно будет правое поддерево, а затем искать максимальное узловое значение вместо минимального.
Обход
Обход – специфическая, но очень важная операция. Так называется последовательное единоразовое посещение всех вершин древа. Обходы совершаются несколькими способами:
- Прямо. В этом случае направление обхода: корень–левое поддерево–правое поддерево.
- Централизованно. Предстоит сначала обойти левое поддерево, затем – корень, а потом уже – правое поддерево.
- Обратно. Обход осуществляется от левого поддерева к правому, а затем – к корню.
Такие операции носят название поиска в глубину. На каждом шаге итератор будет стараться продвинуться вниз по дереву вертикально перед тем, как перейти к родственному узлу – узлу на том же уровне. Также есть поиск в ширину. Это когда обход дерева по уровням производится от корня и далее.

Поиск в глубину может проводиться при помощи рекурсии или стеков. А в ширину – только за счет использования очереди:


На Java это выглядит так:


А так – на Python:

Что такое бинарное дерево, ясно. Лучше работать с ними на языках программирования помогут дистанционные компьютерные курсы.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!


