

Apache Spark vs Apache MapReduce
Как известно, еще не так давно при обработке больших данных активно применялся MapReduce -- Hadoop-компонент, положивший начало Big Data-обработке. Однако сегодня можно сказать, что у этого инструмента есть 2 основные проблемы:
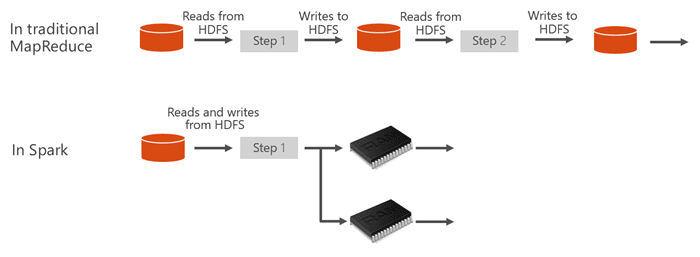
- Невысокая производительность. Модель MapReduce выполняет вычисления за 2 этапа. В первую очередь он разделяет данные на части, передавая их на кластерные узлы для обработки. Потом каждый узел производит обработку данных с отправкой результата на главный узел, где и сформировывается итоговый результат распределенных вычислений. При этом MapReduce регулярно обращается к диску, ведь именно там он сохраняет промежуточные и финальные итоги вычислений. Таким образом, модель функционирует с задержками, причем эти задержки ограничивают применение MapReduce в целях обработки потоковых данных и решения Machine learning-задач.
- Повышенная сложность. Для написания хорошего решения на MapReduce понадобится довольно высокий уровень экспертности. На практике даже относительно опытный инженер может легко допустить ошибку либо написать неэффективный алгоритм.
И вот пришел Spark...
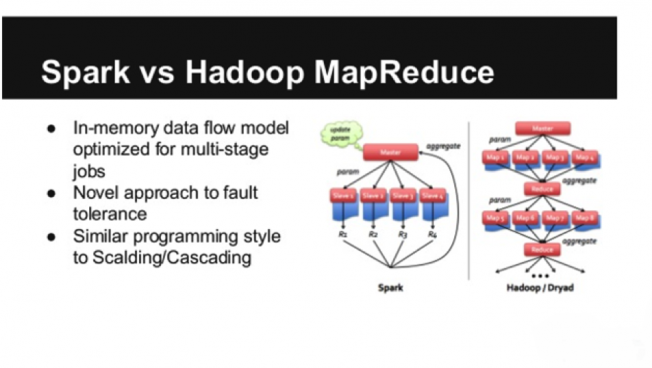
Но, как мы знаем, в 2014 появился фреймворк Spark. Он быстро стал завоевывать популярность, причем сегодня он почти вытеснил MapReduce. Собственно говоря, он и разрабатывался в целях устранения недостатков MapReduce, но, что очень важно, с сохранением преимуществ предшественника. Давайте посмотрим, каким образом Apache Spark решает проблемы MapReduce:
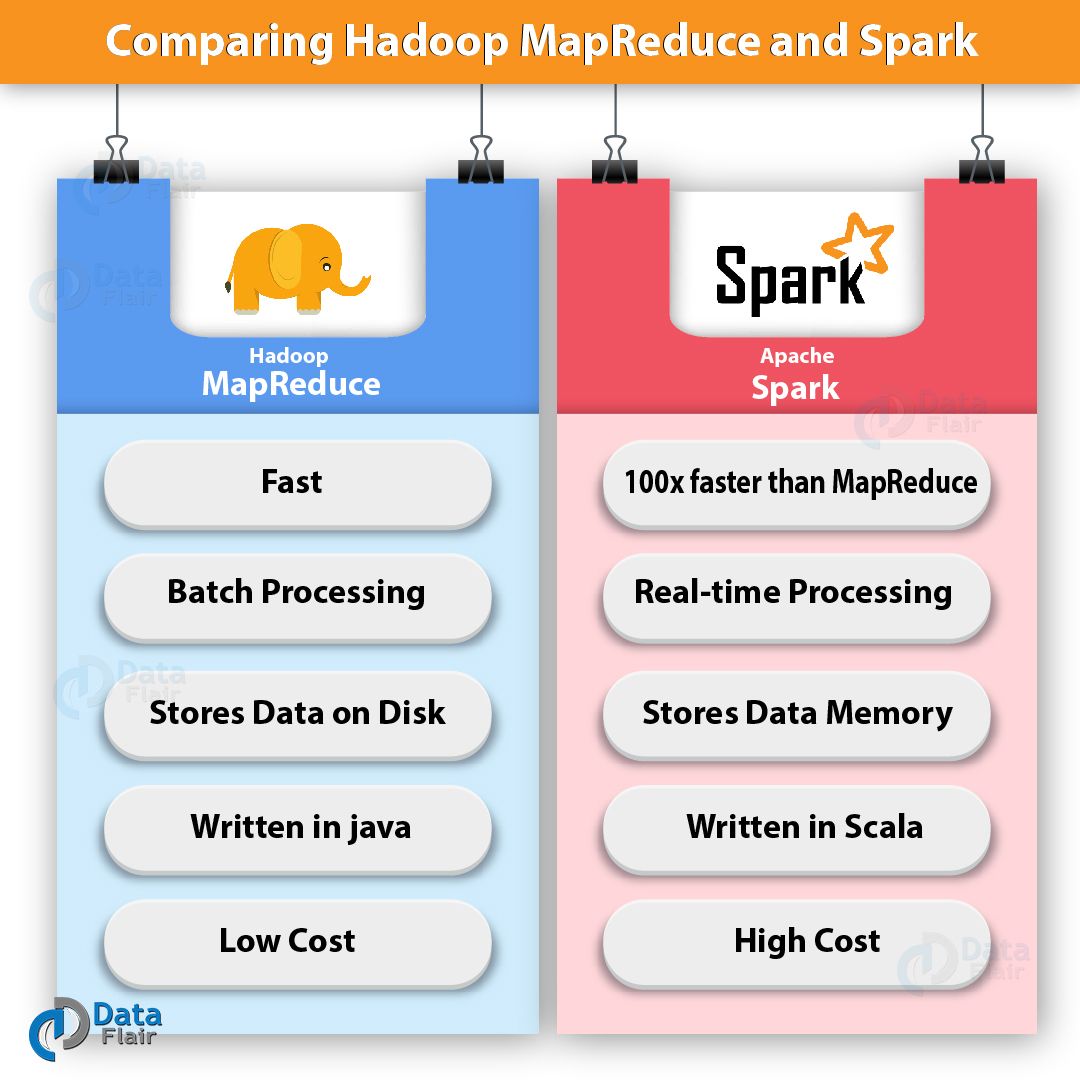
- Spark выполняет обработку данных в памяти и, по сути, почти не обращается к диску. А при возникновении ситуации, когда объем обрабатываемых данных превышает объем RAM, Spark просто сбрасывает часть обрабатываемых данных на диск. Причем во фреймворк включены различные оптимизаторы, позволяющие сокращать количество обращений к диску. Именно поэтому Spark и быстрее MapReduce в десятки раз (а иногда и в сотни!)
- В Spark существует API для различных языков программирования, в результате чего писать код заметно проще, да и сам программный код более компактен. Как правило, разработчики пишут на Spark относительно высокоуровневые инструкции, а уже то, как оптимальнее их выполнить, решает он сам, причем нередко он способен выполнить эту задачу лучше человека.
К примеру, тому же Junior Data-engineer'y вполне по силам написать код на Spark, который станет работать быстрее, чем программный код, написанный более опытным Senior Data-engineer'ом на MapReduce. Кроме того, что немаловажно, на Spark у вас будет меньше шансов совершить серьезную ошибку. Собственно говоря, даже если вы и допустите ошибку, то исправить ее тоже будет легче.
Вывод прост
Если подвести некую черту, то можно с уверенностью сказать, что на момент написания материала Hadoop MapReduce является устаревающей технологией, в то время как Apache Spark фактически стал сегодня стандартом в области обработки Big Data.
По материалам https://mcs.mail.ru/blog/.