

C++ vs Python: сравнение скорости
Если вы Data scientist, у вас есть множество причин любить «Пайтон». Но почему же многие ученые, работающие с обработкой и анализом данными, в дополнение к Python интересуются еще и C++? Ответ прост — скорость.
Давайте сравним скорость Python и C++ на простом примере, используя для обоих языков одинаковый алгоритм. Рассмотрим задачу из биоинформатики, связанную с генерацией всех возможных k-мер ДНК для фиксированного значения k. Для начала сделаем небольшое теоретическое отступление.
Два слова про k-меры ДНК
Как известно, ДНК представляет собой длинную цепь нуклеотидов. Данные нуклеотиды бывают 4-х типов: A, C, G и T. У Homo Sapiens порядка 3 млрд пар нуклеотидов. Вот как выглядит, к примеру, часть человеческого ДНК:

Для получения из него k-мер следует разбить строку на части:

Эти последовательности, состоящие из 4-х символов, называют k-мерами, причем их длина равняется четырем (4-меры).
В чем заключается задача?
Будут сгенерированы все возможные 13-меры. С точки зрения математики, речь идет о перестановке с проблемой замены. Таким образом, мы имеем 4 в 13-й степени вариантов 13-меров (67 108 864).
Сравниваем скорость С++ и Python
Как уже было сказано выше, воспользуемся одним и тем же алгоритмом для обоих языков. Код написан аналогично и максимально просто, без сложных структур данных и сторонних библиотек.
Вот что у нас получилось на Python:
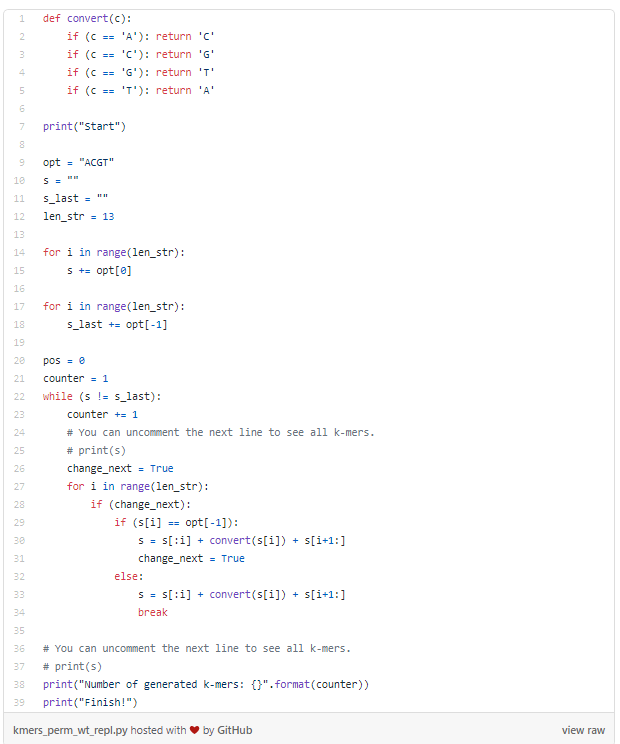
Данная программа выполнится за 61.23 секунды. В течение данного времени будет сгенерировано более 67 млн 13-меров. Дабы не увеличивать время работы программы, код, выводящий результаты, был закомментирован (строки 25 и 37). Если же вы этот код раскомментируете, то учтите, что процесс может занять много времени. Впрочем, всегда можно остановить выполнение программы, нажав CTRL+С на клавиатуре.
Теперь пришла очередь языка C++:
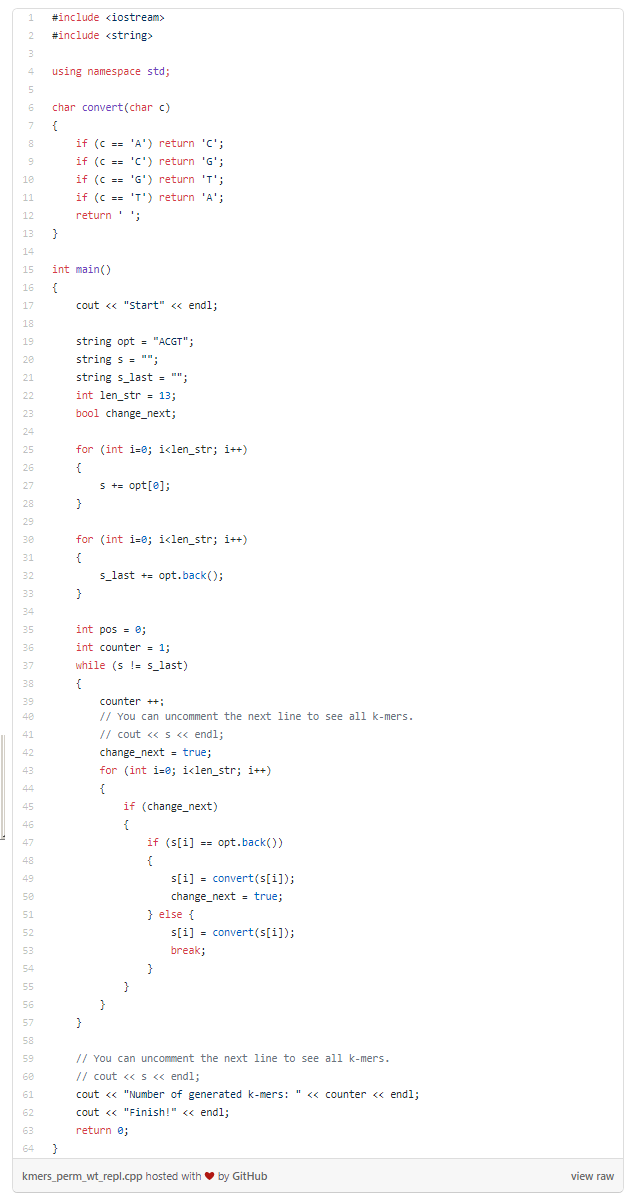
Код, указанный выше, после компиляции выполнится за 2.42 секунды. Из этого следует вывод: «Пайтону» понадобилось в 25 раз больше времени на решение задачи. Если же повторить данный эксперимент с 14 и 15-мерами, то мы снова убедимся, что производительность Python и C++ при выполнении одинаковой задачи существенно отличается.

Конечно, оба варианта кода неидеальны и могут быть оптимизированы. К примеру, мы не используем параллельные вычисления, не сохраняем результаты и т. д. Но общей сути это не меняет.
Таким образом, можно подытожить: дата-сайентистам действительно стоит обращать внимание на C++, если предстоит работа с большими массивами данных, требующими повышенной производительности процесса обработки.
По материалам статьи «How fast is C++ compared to Python?».