

Регулярное выражение в PHP. Что такое регулярные выражения?
В статье пойдет разговор о регулярных выражениях и функциях PHP regexp. Особое внимание будет уделено функции preg_replace, используемой для поиска по шаблону с последующей заменой на указанную строку.
PHP regexp (Regular Expressions) представляет собой алгоритм сопоставления шаблонов, причем это сопоставление можно выполнять в одном выражении. Для начала вспомним работу с командной строкой — к примеру, использование маски имен файлов, когда для удаления всех файлов в текущей директории, начинающихся на «d», системный администратор прописывает команду
Если вернуться к регулярным выражениям, то стоит сказать, что они представляют собой похожий инструмент для поиска и проверки строк на соответствие какому-нибудь шаблону. Но этот инструмент более мощный. Если сформулировать значение термина более простым языком, то регулярные выражения — это, по сути, специальный язык, предназначенный для описания шаблонов строк.
В каких случаях применяются regexp: • для упрощения идентификации строковых данных посредством вызова одной функции — на выходе получается экономия времени при написании кода; • для проверки данных, введенных пользователем: email-адреса, домена сайта, номера телефона, IP-адреса; • для выделения ключевых слов в результатах поиска; • в целях идентификации тегов/замены тегов.
В языке программирования PHP при работе с регулярными выражениями используют арифметические операторы (к примеру, +, -, ^), что позволяет создавать сложные выражения. Также PHP включает в себя встроенные функции preg, позволяющие работать с Regular Expression. Чаще всего используют: • preg_match — для сопоставления с шаблоном строки. Возвращает true, когда совпадение найдено, в обратном случае — false; • preg_split — для разбивки строки по шаблону с возвратом результата в виде числового массива; • preg_replace – если надо искать по шаблону с последующей заменой на указанную строку.
Функция preg_replace
Основные функции PHP (match, split и replace), предназначенные для работы с регулярками, мы уже перечислили. В этой статье рассмотрим особенности функционирования preg_replace: данная функция напоминает str_replace, — функцию для поиска и замены, только лишь в качестве первого параметра здесь принимается не просто строка, а регулярное выражение. Разница следующая:

Здесь нужно обратить внимание на решетки # — в них помещена буква «а» — их называют ограничителями используемых в коде регулярных выражений. После ограничителей пишутся модификаторы — команды, меняющие общие свойства регулярки. Тот же модификатор i заставит проигнорировать регистр символов:
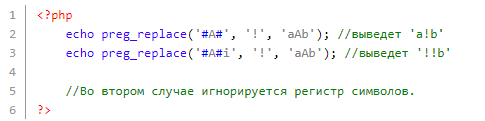
Буквы, цифры, символы
В регулярных выражениях существуют два вида символов: обозначающие сами себя и символы, которые называют командами (спецсимволы).
Цифры и буквы обозначают сами себя, зато точка — спецсимвол, обозначающий «любой символ». Смотрим примеры:

По сути, в коде выше не существует разницы между функциями preg_replace и str_replace – функционируют они одинаково, разница заключается лишь в ограничителях.
В следующем примере можно увидеть, как использовался спецсимвол «точка» — такое уже нельзя сделать с помощью str_replace:

Раз точка — любой символ, то под регулярку подпадут все подстроки, причем по следующему шаблону: буква 'x', потом любой символ, потом снова 'x'. Первые четыре подстроки попали под данный шаблон (xax xsx x&x x-x), поэтому они заменились на '!'. Последняя подстрока (xaax) не подпала по той причине, что внутри (между буквами 'x') находится не один, а два символа.
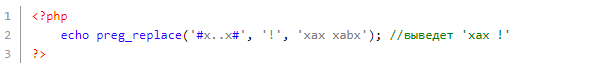
Раз точка — любой символ, а в регулярке мы видим 2 точки подряд, то под регулярку подпадут все подстроки по следующему шаблону: буква 'x', потом 2 любых символа, потом снова 'x'. Первая подстрока не подпадет, т. к. она содержит лишь один символ между буквами 'x', в то время как последняя подстрока (xabx) шаблону соответствует.
Что тут важно запомнить: цифры и буквы обозначают сами себя, точка же заменяет любой символ. Также важно следующее: для функции preg_match точка на деле обозначает любой символ за исключением перевода строки. Дабы точка обозначала и его, необходим модификатор s.
Операторы повторения
Иногда мы хотим указать, что какой-нибудь символ повторяется определенное число раз. Когда мы знаем это число точно, то просто пишем ('#aaaa#'). Но как поступить, если мы желаем повторить один либо больше раз?
Вопрос решается с помощью операторов повторения (квантификаторов): плюс '+' (один и больше раз), потом звездочка '*' (ноль и больше раз), а затем вопрос '?' (ноль либо один раз, то есть может быть, а может и не быть).
Эти операторы действуют на символ, который непосредственно стоит перед ними.
Для наилучшего понимания стоит рассмотреть пример:

В коде выше шаблон поиска выглядит следующим образом: буква 'x', потом 'a' один либо больше раз, потом 'x'.
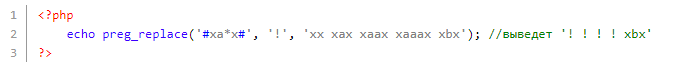
В этом случае шаблон поиска будет выглядеть следующим образом: буква 'x', буква 'a' ноль либо больше раз, буква 'x'. То есть буквы 'a' либо нет, либо она повторяется один и больше раз.
Кроме самого очевидного варианта xax xaax xaaax, также подпадает подстрока 'xx', ведь там не существует буквы 'a' вообще (то есть ноль раз).
Также под шаблон не подпал и 'xbx'. Это связано с тем, что отсутствует 'a', однако есть 'b' (ее не разрешали).

Здесь шаблон поиска выглядит следующим образом: буква 'x', далее 'a' может быть либо не быть, далее 'x'.
Группирующие скобки
В примерах, которые были рассмотрены выше, операторы повторения воздействовали лишь на один символ, стоявший перед ними. Но иногда надо задействовать сразу несколько символов — в таких ситуациях пригодятся группирующие скобки '(' и ')':

Здесь шаблон поиска выглядит следующим образом: буква 'x', потом строка 'ab' один либо больше раз, потом 'x'.
Если что-либо стоит в группирующих скобках, а сразу после закрывающей скобки находится оператор повторения, этот оператор подействует на все, что расположено внутри скобок.
Экранируем спецсимволы
Иногда надо сделать так, чтобы спецсимвол обозначал себя сам. К примеру, чтобы найти по следующему шаблону: 'a', потом плюс '+', потом 'x'. Код ниже будет функционировать не совсем так, как хочется:
<?php echo preg_replace('#a+x#', '!', 'a+x ax aax aaax'); //выведет 'a+x ! ! !'' ?>
Тут разработчик планировал, чтобы шаблон поиска выглядел следующим образом: буква 'a', потом плюс '+', потом 'x'. На деле он выглядит иначе: буква 'a' один либо больше раз, потом 'x'. Именно поэтому подстрока 'a+x' не подпала под шаблон (так как мешает '+'), а все остальные подпали.
Здесь важно запомнить следующее: чтобы спецсимвол обозначал себя сам, его надо экранировать посредством обратного слеша. Вот, каким образом это можно реализовать:

Теперь наш шаблон поиска выглядит нужным образом: буква 'a', потом плюс '+', потом 'x'.

В примере выше шаблон выглядит следующим образом: 'a', далее точка '.', далее 'x'. Сравним с примером ниже (тут забыт обратный слэш):

В результате все подстроки попали под шаблон, ведь неэкранированная точка обозначает, по сути, любой символ.
Следует обратить внимание вот на что: если забудете обратный слэш для точки (в случае, когда она должна сама себя обозначать), это можно даже и не заметить:

Да, визуально все работает правильно, но т. к. точка обозначает любой символ, включая обычную точку '.'. Однако если строку, где происходят замены, поменять, ошибка станет заметна:

Вывод прост: следует быть предельно внимательным!
Ограничители
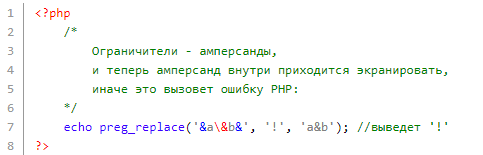
В роли ограничителей способны выступать не только # — для этого существуют и другие символы (буквы и цифры не в счет). Когда применяются скобки, левый ограничитель одновременно является открывающей скобкой, в то время как правый — закрывающей:


Когда символ не специальный, то при использовании его в роли ограничителя, его следует экранировать непосредственно в самой регулярке (станет специальным):

Перечень обычных и спецсимволов
При экранировании обычного символа ничего особенного не случится, и он все равно будет обозначать себя сам. Исключениями являются цифры, которые станут карманами. Также исключением будет модификатор 'X': когда он установлен, экранировка обычных символов вызывает ошибку.
Порой появляются сомнения, а является ли символ специальным. Иногда разработчики даже экранируют подряд все подозрительные символы, но это плохая практика, ведь происходит захламление регулярки обратными слэшами.
- Что является спецсимволами: $ ^ . * + ? \ {} [] () |
- А что не является: @ : , ' '' ; - _ = < > % # ~ `& ! /
- Также спецсимволами будут выбранные ограничители.
Вдобавок к этому, # будет спецсимволом в случае наличия модификатора 'x' (речь идет именно про маленький 'x', разрешающий комментарии).
Об ограничении «жадности»
Для понимания, о чем идет речь, лучше сначала ознакомиться с примером:

Здесь шаблон поиска выглядит следующим образом: 'a', любой символ один и больше раз, 'x'. Но выражение сработало не так, как ожидал разработчик: было захвачено максимально возможное число символов, т. е. закончилась не на первом 'x', а на последнем.
Данное поведение операторов повторения называют жадностью, т. к. они стремятся забрать как можно больше. Это особенность полезна, но не всегда, поэтому ее можно отменить, ограничив жадность. Для этого надо добавить к оператору повторения знак '?': вместо жадных '+' и '' следует написать '+?' и '?', что ограничит эту самую жадность:

В примере выше шаблон поиска выглядит так: 'a', потом любой символ один либо больше раз (с ограничением жадности) и 'x'.
Посредством '?' была ограничена жадность плюсу, поэтому теперь поиск осуществляется до первого совпадения.
Жадность можно ограничивать для всех операторов повторения, включая '?', '{}' — выглядеть это будет так: '??' и '{}?'.
Ссылки на источники: • https://www.internet-technologies.ru/articles/regulyarnye-vyrazheniya-php.html; • http://old.code.mu/books/php/regular/rabota-s-regulyarnymi-vyrazeniyami-v-php-glava-1.html.
