

Что такое нормализация баз данных?
Статья расскажет о том, что такое нормализация баз данных, для чего она нужна, и какие виды нормализации существуют. Для наилучшего понимания отношений между таблицами в нормализованной базе данных будут приведены практические примеры.
При создании базы нужно учитывать некоторые правила. Исходя из вышесказанного, можно привести следующую формулировку: нормализация БД — это процесс организации данных определенным образом и рекомендации по проектированию. То есть таблицы и связи между ними (отношения) создаются в соответствии с правилами. В результате обеспечивается нужный уровень безопасности данных, а сама база становится более гибкой. Также устраняются несогласованные зависимости и избыточность.
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества: — упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами; — обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных; — улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД; — отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер; — отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.
Как выполнить нормализацию?
Чтобы привести БД к нормальной форме, необходимо: 1. Объединить имеющиеся данные в группы. 2. Выяснить логические связи между группами. Чтобы обеспечить правильность связей, связываемые поля должны иметь один тип.
Если таблица не нормализована, она может хранить информацию о нескольких сущностях и включать в себя повторяющиеся столбцы, а они, в свою очередь, могут хранить дублируемые значения. Если же нормализована, то каждая таблица хранит информацию лишь об одной сущности.
При нормализации предполагается использование нормальных форм по отношению к структуре имеющихся данных. Есть несколько правил нормализации. Каждое из них носит название «нормальная форма» (НФ). Каждая такая форма, кроме первой, предполагает, что к данным уже применили предыдущую нормальную форму. При выполнении первого правила БД представлено в первой нормальной форме (1НФ), при выполнении трех правил — в третьей нормальной форме (3НФ).
Таких форм (уровней) — семь, однако на практике для большей части приложений вполне достаточно нормализовать БД до третьей нормальной формы (строго говоря, БД и будет считаться нормализованной, когда к ней применяется 3НФ и выше).
Да, обеспечить полное соответствие правилам и спецификациям — задача не всегда выполнимая, ведь для нормализации придется создавать дополнительные таблицы, а это не всегда приемлемо или не находит отклика у клиентов. Но если правила приходится нарушать, надо понимать, что все, связанные с этим проблемы, включая несогласованные зависимости и избыточность, будут учтены, и что это допустимо для приложения, не нарушит его работоспособность.
Правила нормализации на примерах
Первая нормальная форма (1НФ)
Согласно правилам, все атрибуты в такой таблице должны быть простыми, все сохраняемые данные на пересечении столбцов и строк — содержать лишь скалярные значения. Также не должно быть повторяющихся строк.
Для примера возьмем таблицу с автомобилями:

Обратите внимание на нарушение нормализации в моделях BMW — в одной ячейке находится перечень из трех элементов: M5, X5M, M1, то есть можно говорить об отсутствии атомарности. После преобразования в 1НФ таблица меняет вид:
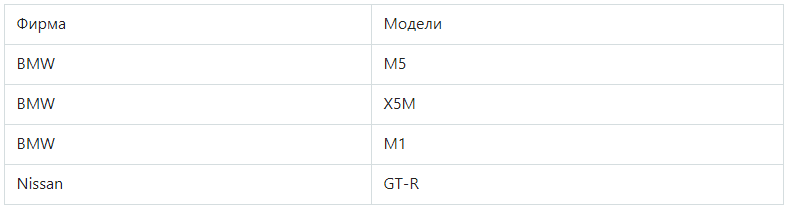
Вторая нормальная форма (2НФ)
Отношения будут соответствовать 2НФ, если сама БД находится в 1НФ, а каждый столбец, который не является ключом, зависит от первичного ключа.
Рассмотрим очередную таблицу:
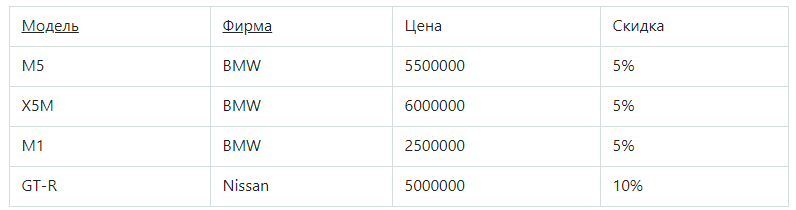
Она в 1НФ, но не во 2НФ. Стоимость авто зависит от модели и производителя. Размер скидки зависит от производителя, поэтому функциональная зависимость от первичного ключа является неполной. Исправить это можно, выполнив декомпозицию на 2 отношения, где неключевые атрибуты будут зависеть от первичного ключа.
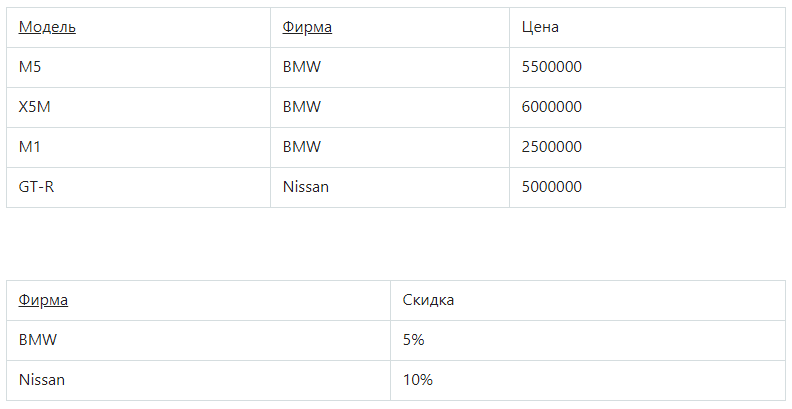
Третья нормальная форма (3НФ)
Таблица должна находиться во 2НФ, плюс любой столбец, который не является ключом, должен зависеть лишь от первичного ключа.
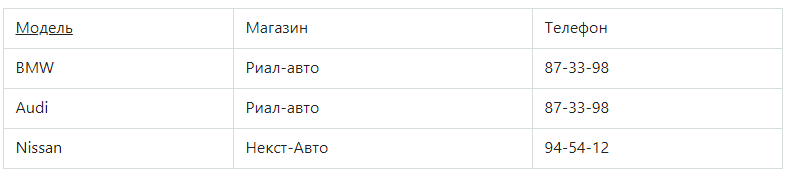
В таблице в отношении атрибут первичным ключом является «Модель». Так как собственные телефоны у автомашин отсутствуют, телефон зависит только от магазина.
В результате можно говорить о наличии в связях следующих функциональных зависимостей:
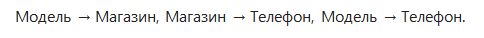
Зависимость «Модель → Телефон» — транзитивна, поэтому отношение не находится в 3НФ.
Разделив исходное отношение, можно получить 2 отношения, и они уже будут находиться в 3НФ:
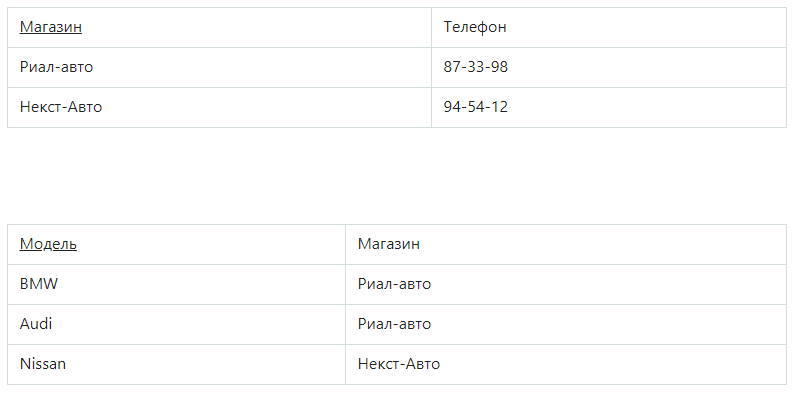
Остальные виды соотношений и правил, можно посмотреть по ссылкам ниже: - https://ru.wikipedia.org/wiki/Нормальная_форма; - https://habr.com/ru/post/254773/.
P. S. Очень надеемся, что теперь у вас сложилось представление о том, что такое нормализация базы данных. Если же вы хотите освоить работу с БД на профессиональном уровне, добро пожаловать на курсы OTUS!